خلاصه جلسه ششم درس حمل و نقل هوشمند ۹۲/۰۷/۲۳
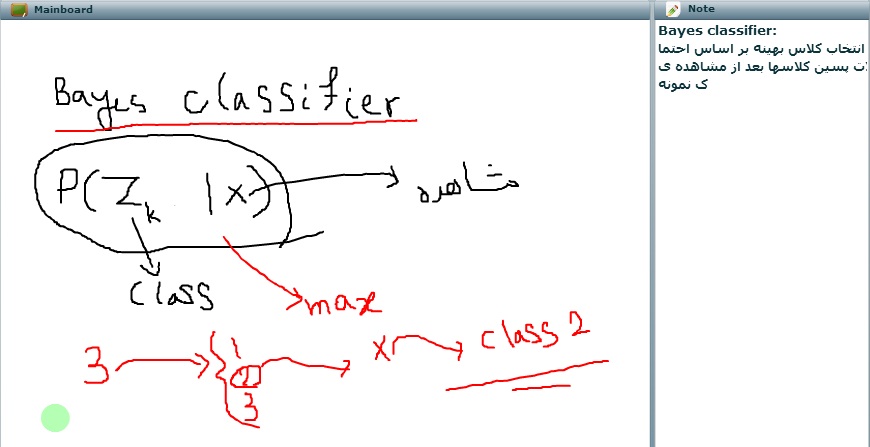
در هر مساله کنترلی یک پارامتری داریم مثل ساو
هر تغییری که در ساو اتفاق بفتد در سفر های مردم تغییر حاصل می شود.
ستاره هم به معنی تعادل است
مثلا چراغ راهنمایی را زمانش را تغییر میدهیم ، مثلا ترافیک بیشتری ایجاد می شود تا جایی که در خیابان های اطراف هم تاثیر می گذارد
Ca هزینه است که یک نفرپرداخت می کند
Qa تعداد افراد هستند
نقطه تعادل محل تقاطع دو منحنی است
تقاضا و عملکرد
برای بیان تعادل اصل اول و دوم wardrop را مطرح می کنیم
در اصل دوم wardrop هوش راننده ها هم دخیل هست
برای پیاده سازی الگوی تعادل کاربر تصادفی
….
تعریف مجدد زمان پیمایش
برای پیاده سازی مساله
یک احتمال انتخاب مسیر p در زمان t داریم
مدل های انتخاب
Probit (شرط نرمال بودن خطا)
Logit (تحلیلی )
——————————-
Logit model
فرم تحلیلی دارد
وابسته بودن مسیر ها به هم انکار می شود و به همگرایی می رسد
توزیع خطا از نوع گامبل در نظر گرفته می شود
تابع احتمال انتخاب مسیر در این مدل از رابطه زیر به دست می آید

یک مساله Convex هست مثل مساله سهمی که حتما یک جواب بهینه دارد
میزان جریان مسیر =میزان تقاضای سفر * تابع انتخاب logit

آقای دمبرگ Damberg از این فرمول استفاده کرد
برای هر مبدا مقصد یک مجموعه مسیر در نظر گرفته و یک جریان شدنی اولیه روی مسیرها بیابید.
در هر تکرار جریان به دست آمده از فرمول انتخاب لاجیت به دست آورده جریان فعلی را با آن مقایسه و به کمک آن جریان فعلی را به هنگام نمایید.
بر اساس جریانهای به دست آمده، هزینه پیمایش مسیرها را به هنگام و دوباره مسیریابی نمایید و به مجموعه مسیرها افزوده واین عملیات را تا حصول همگرایی تکرار کنید.
مساله شمارش مسیر ها و ایده های حل
۱- برچسب های مختلف بر اساس سلیقه ها (زیبایی ، خلوت بودن ، کوتاه ترین ، ارزان ترین )
۲- تولید ستون
۳- k مین مسیر کوتاه
۴- ابتکار بر اساس حذف یالها
۵- ابتکار برای وضع قوانین جریمه یالها
۶- مسیر های حداکثر k مشابه
۷- مسیر های نا متشابه
۸- مسیر های تصادفی
۹- مسیر های نامغلوب فازی
ایده جریمه :
۱٫ واحدهای جریمه، (یال یا گره یا هر دو)
۲٫ ساختار جریمه،(جمعی یا ضربی)
۳٫ بزرگی جریمه
۴٫ مسیر جریمه (مسیر فعلی یا کل مسیرها تا حال)
ویژگیهای ایده جریمه
سادگی ایده
فاقد عمومیت برای همه مثالها
فاقد راهی برای ارزشیابی میزان شایستگی مسیرهای انتخاب شده
انتخاب مسیرها وابسته به نحوه انتخاب پارامترهای فوق
در به کارگیری روش جریمه ضربی ریسک ناپایداری عددی
نیاز به وجود یک ترتیب برای ورود جریانهای مختلف شبکه، که در بحث جریمه شدن جریانی خاص دخیل است.
ایده مسیرهای نامتشابه
یک اندازه تنافر بین مسیرهای موجود در یک مجموعه دادهشده، بیشینه میشود. از این جهت این ایده یکی از کاراترین روشهای انتقال مواد استراتژیک و خطرناک میباشد.
ایدههای ساخت مسیرهای نامتشابه (متنافر)
۱ – ایده جریمههای متوالی
۲ – ایده کوتاهترین مسیر دروازهای
۳ – ایده کمینه گرفتن روی بیشینه شباهتها
۴ – ایده p-پخش ( بیشینه گرفتن روی حداقل تنافر)
مطابقت دوطرفه برای مساله تنظیم
نرم افزار TRANSYT برای محاسبه مقدار کارایی سیستم به ازای متغیرهای کنترلی چراغ راهنما و نرمافزار PFE برای تعیین مقدار جریان تعادلی.
تنظیم چراغ راهنما با آلگوریتم ژنتیک دودویی کد
نکاتی که در پیادهسازی آلگوریتم ژنتیک بایستی به آنها توجه شود:
•نحوه نمایش ژنتیکی جوابهای مساله
•راهی برای ساختن جمعیت اولیه جوابها
•تابع ارزشیابی که میزان شایستگی جوابها را نشان دهد.
•عملگرهای ژنتیکی که ترکیب ژنی فرزندان را صورت داده و جمعیت جدید تولید نماید.
• مقادیر پارامترهای ژنتیکی
گام ۱٫ پارامترهای مورد نیاز آلگوریتم ژنتیک تعیین و متغیرهای تصمیم را به صورت دودویی بر اساس کران پایین و بالا و کد نمایید.
گام ۲٫ جمعیت تصادفی اولیه از متغیرهای چراغ راهنما تولید کنید.
گام ۳٫ مساله سطح پایین را به وسیله روشی از PFE حل و جریانهای تعادل کاربر تصادفی برای هر یال شبکه محاسبه کنید.
گام ۴٫ زمانهای چراغ راهنمای مطرح شده در گام دو و جریانهای تعادلی یالهای شبکه محاسبه شده در گام سه را به نرم افزار TRANSYT داده، معیار کارایی سیستم را به وسیله آن محاسبه نمایید.
گام ۵٫ عملگر آمیزش و عملگر جهش ژنتیکی را به کار برید.
گام ۶٫ جمعیت جدید را از روی جمعیت قبلی و فرزندان بسازید.
گام ۷٫ اگر تفاوت میان میانگین شایستگی جمعیت و شایستگی بهترین عضو جمعیت کمتر از ۵% باشد، جمعیت اولیه جدیدی ساخته و به قدم سه بازگردید. در غیر این صورت به سراغ قدم بعد بروید.
گام ۸٫ اگر بیشترین تعداد مجاز جمعیت گیری حاصل شده باشد، جواب با بالاترین شایستگی را جواب بهینه مساله گرفته و الا به سراغ قدم ۳ برگردید.
تمرین : با یکی از روش های ۱ و۴و ۷ فوق پیاده سازی کنید و تا هفته بعد ارسال کنید.
شبکه ای که آپلود شده در LMS استفاده کنید
شکل شبکه را در مقاله صفحه ۴۶۶ آمده روی هر کدام از یالها شماره گذاری شده در جدول صفحه ۴۶۷ تقاضای سفر ها آمده یک فرمول هم آمده جریان تقسیم بر سفر
در صفحه ۴۶۸ – پارامتر های لازم آمده
برای حل این مساله ۲ هفته فرصت هست
کدی پیاده سازی کنید با روش دمبرگ با همین ۳ تا ایده دمبرگ اسلاید شما ره ۹ ، یاد آوری با استفاده از ساو Q را پیدا میکنیم
۲ سطحی هست
در یک سطح با استفاده از Saw مقدار Q را پیدا کنیم
با استفاده از مقدار های Q مقدار Saw را آپدیت کنم
در این مسایل از نرم افزار های تخصصی برای هر بخش استفاده کنیم
نرم افزار Transyt برای چراغ راهنما
از نرم افزار PFE برای تعیین مقدار جریان تعادلی
استفاده از الگوریتم ژنتیک برای محاسبه پارامتر کنترلی
نحوه ساخت تابع ارزشیابی هم با این روش مشخص می شود
شنبه ۲۷/۷/۹۲ جلسه دفاع پایان نامه با نرم افزار TURBO توسط خانم روشنی برگزار می شود
و همچنین سه شنبه هفته آینده در جلسه تکمیل تر تکرار خواهد شد

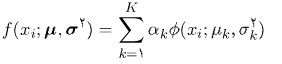


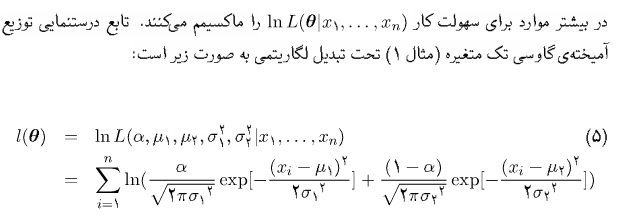


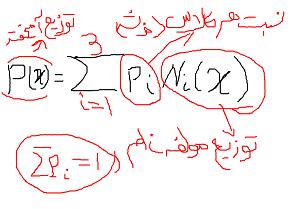
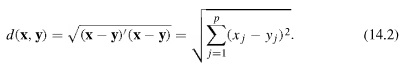






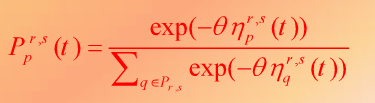



{kind=link}