خلاصه درس داده کاوی ۹۲/۰۷/۲۲ – دکتر محمد پور
صفحه ۱۸/۲۱
OLAP Operations : Data Cube
جدول ها را نرم افزار می کشد ، لازم نیست
اگر بعضی وقت ها داده ها دو بعدی باشد ، هیستوگرام را سه بعدی می کشیم
hist2D فراوانی داده ها را به صورت دو بعدی محاسبه میکند
OLAP را رسم کنید
خلاصه شده داده ها را نشان میدهد
با استفاده از خلاصه سازی رابطه بین متغیر ها را می توانیم مشخص کنیم
مثلا برای جدول ۷ بعدی ۲۴۰۰۰ مدل داریم
clustering یک روش unsupervised هست که هدفش قرار دادن داده های همگون در خوشه هست
اگر داده های یک بعدی باشد همان متر معمولی را در نظر می گیریم
ولی اگر داده ها بیش از یک بعد داشت ( p بعدی )
مولفه ها را با هم مقایسه می کنیم
نرم اقلیدسی
با یک تبدیل می توانیم بردار را به ماتریس تبدیل کنیم
در روش سلسله مراتبی ما اطلاع نداریم که چند تا خوشه داریم
با روش جمع شونده
هر یک از داده ها را یک خوشه می گیریم
و در هر مرحله یک خوشه کم می شود
برای همین محاسبات خیلی سنگین می شود
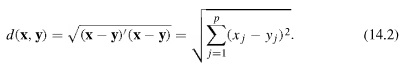
فاصله یک نقطه از مجموعه : چند روش مختلف داریم
۱- فاصله نقطه تا مینیمم مجموعه Single Linkage ( Nearest Neighbor )
مثال جرم و جنایت در شهر های آمریکا
رسم دندوگرام
۲- روش Complete Linkage
در مرحله بعدی جدولی که بدست می آوریم مشابه جدول روش اول است
۳- Average Linkage
میانگین فاصله
۴- روش Centroid
چون روش agerage محاسبات سنگینی دارد در Centroid به جای فاصه میانگین ها ، از میانگین فاصله ها استفاده می کنیم
۵- روش median میانگین وزنی است
۶- روش ward

تمرین : برای هفته آینده

جدول جرم و جنایت در آمریکا
با سه روش
single linkage
Complete Linkage
Average Linkage
به ایمیل بفرستید
statdatamining@gmail.com