Damberg 1996
مرحله ۱ : زمان سفر در هر یال ثابت (زمان سفر تک تک خیابان های ممکن در مسیر بدون ترافیک ) در نظر می گیریم (بهترین حالت زمان سفر آزاد – کاملا بدون ترافیک – را در هر خیابان در نظر می گیریم ) تمام مجموعه مسیر های بین مبدا و مقصد را پیدا می کنیم
مرحله ۲ : تابع لاجیت را برای بدست آوردن بار ترافیکی روی هر مسیر استفاده می کنیم
و از روی فرمول … میزان جریان ترافیکی که از روی یک یال (خیابان) عبور می کند را نسبت به جریان های ترافیکی مسیر ها می توانیم بدست بیاوریم
ترکیبی از الگوریتم دایکتسرا و جریمه کردن
مثلا سه بار الگوریتم دایکسترا با در نظر گرفتن پارامتر های جریمه ای
حذف کردن یال مناسب نیست

در فاز پیاده سازی ۳ تا کوتاهترین مسیر را در نظر بگیرید
مسیر منتخب رو از مدار انتخاب خارج میکنیم
ابتدا با یک الگوریتم مسیرهای کوتاه را پیدا می کنیم-وقتی پیدا کردیم حالا مجموع مثلا ۳ مسیر کوتاه را پیدا می کنیم(برای مخرج لاجیت)
حذف یال خیلی مناسب نیست
ولی جریمه کردن ممکن است نتیجه خوبی بدهد

الگوریتم k shoertest path
میران تفاضل جریان ثانویه را حساب می کنیم اگر بزرگتر از اپسیلون بود ادامه میدهیم
و اگر کمتر از اپسیلون بود متوقف می کنیم
cost ترکیبی از زمان و هزینه است
۲ تا flow داریم (جریان اولیه – جریان ثانویه )
۱- TrueFlow (جریان ترافیکی بدون ترافیک )
۲- Estimated Flow by Logit (یک بار داخل تابع logit می گذاریم)
یک بار بر اساس جریان یالی آزاد میزان جریان را حساب می کنیم
جریان اولیه و با توجه به جریان های قبلی هزینه ها را Update کردیم
با توجه انتخاب الگوریتم logit جریان بعدی باید نزدیک به هم بشوند
۲ هفته دیگه مهلت تمرین تمدید می شود
در جلسه حضوری ۴ شنبه کد ها را از نزدیک بررسی میکنیم
مطابقت دوطرفه برای مساله تنظیم
تخمین سفر path estimator
استفاده از الگوریتم ژنتیک :
– نحوه نمایش ژنتیکی جوابهای مساله
راهی برای ساختن جمعیت اولیه جواب ها
تابع ارزشیابی که میزان شایستگی جواب ها را نشان می دهد.
عملگر های ژنتیکی که ترکیب ژنی فرزندان را صورت داده و جمعیت جدید تولید نماید.
مقادیر پارامتر های ژنتیکی
گام ۱ : پارامتر های مورد ننیاز الگوریتم ژنتیک تعیین و متغیر های تصمصم را به صورت دودویی و بر اساس کران پاین و بالا و کد نمایید.
گام ۲ : جمعیت تصادفی اولیه از متغیر های چراغ راهنما تولید کند
گام ۳ : سطح پایین را به وسیله روشی از PFE حل و جریانهای تعادل کاربر تصادفی برای هر یال شبکه محاسبه کنید.
گام ۴ : زمانهای چراغ راهنمای مطرح شده در گام دو و جریان های تعادلی یال های شبکه محاسبه شده در گام سه را به نرم افزار Transyt داده ، معیار کارایی سیستم را به وسیله آن محاسبه نمایید
گام ۵ : عملگر آمیزش و عملگر ژنتیکی را به کار ببرید
گام ۶ : جمعیت جدید را از روی جمعیت قبلی و فرزندان بسازید.
گام ۷ : اگر تفاوت میان میانگین شایستگی جمعیت و شایستگی بهترین عضو جمعیت کمتر از ۵% باشد جمعیت اولیه ساخته و به قدم سه باز گردید . در غیر انصورت به سراغ قدم بعد بروید.
گام ۸ : اگر بیشترین تعداد مجاز جمعیت گیری حاصل شده باشد، جواب با بالاترین شایستگی را جواب بهینه مساله گرفته و در غیر این صورت به سراغ قدم سه بر گردید
بعد از پیاده سازی تخصیص ترافیک را که انجام دادید
به عنوان تمرین ۲ : جواب مقادیر سبز چراغ راهنما بر این اسا س قابل پیاد هسازی هست یا نه
کد الگوریتم ژنتیک برای بهینه سازی زمانبندی چراغ راهنما بنویسید







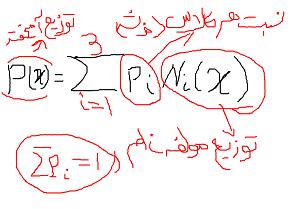






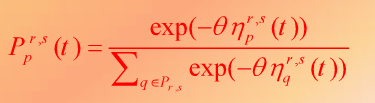
{kind=link}