خلاصه جلسه پنجم درس خوشه بندی – دکتر زارع ۹۲/۰۷/۲۲
بحث کلاسترینگ و Mixture Model
N تا آبجکت داریم که می خواهیم به K تا گروه خوشه بندی کنیم
مدل آمیخته(Mixture Model ) ترکیبی از توزیع های احتمالاتی است
چون هر خوشه با خوشه دیگر تفاوت دارد می توانیم این فرض را بگیریم که هر خوشه خودش دارای یک توزیع احتمال است و مجموع کل داده ها یک توزیع احتمالاتی دارد که ترکیبی از تک تک چگالی های داخل هر خوشه است
کاربرد مدل آمیخته در خوشه بندی :
در روشهای سلسله مراتبی و k-means نداشتیم نمی دانستیم که الگوریتم تا کجا باید پیش برود و تعداد K چند تا باشد جواب بهینه بدست می آید و بیشتر به خروجی نگاه می کردیم
ولی در Mixture Model می توانیم برای انتخاب بهترین مدل، معیار داشته باشیم
مثل BIC و AIC
Akaeki Information Cretaria
Baysian Information Cretaria
معمولا از تابع گوسی استفاده می کنیم
GMM – Gaussian Mixture Model
آقای Andrew Moore
مولفه را با امگا i نشان داده ایم
برداری از ویژگیها داریم
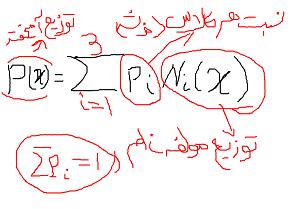
فرض می کنیم نوع تراکنش هر گونه باهم برابر است
توزیع یونیفرم
ابتدا یک عدد تصادفی بین صفر و یک ایجاد می کنیم
اگر عدد تصادفی ایجاد شده کمتر از ۰٫۳ بود امگا ۱ می گذاریم
اگر عدد تصادفی ایجاد شده کمتر از ۰٫۵ و بیشتر ۰٫۳ بود امگا ۲ می گذاریم
و بزرگتر از ۰٫۵ بود امگا ۳ می گوییم
ممکن است شکل خوشه ها شکل هم نباشد
همبستگی خطی
تا هفته بعد تمرین که حداکثر ۱ نمره دارد بفرستید
Mixture of Gaussian
متغیر پنهان
هر نقطه در آن واحد فقط می تواند به یک خوشه متعلق باشد