خلاصه درس خوشه بندی جلسه ۹۲/۰۷/۲۹
GMM assumption
فرض می کنیم هر کلاستر تابع توزیع نرمال هست
اگر بخواهیم یک مدل آمیخته را نمایش دهیم
اگر Latent Variable ها را بدانیم
Latent Varible ها Parent های کلاستار ها هستند
aic : Akaike information Criteria
BIC :Bayesian Information Criteriaumber of cluster
می توانیم از فرمول قانون بیز استفاده کنیم

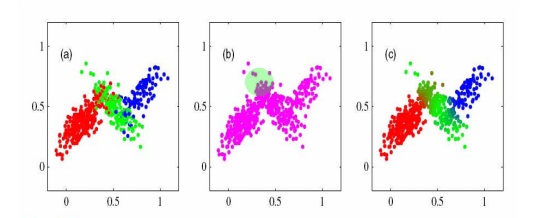
اگر تعداد داده ها زیاد باشد و شکل نمایشی آن gaussian مانند باشد استفاده از روش GMM بسیار خوب است
ولی اگر داده ها کم است از GMM استفاده نکنید
الگوریتم EM – یک فرض می گذارد
اساس کار این است که به صورت پیش فرض اطلاعات کافی نیست
و مشاهدات ناقص هست
یک متغیر zk به مساله اضافه می کند
و بر اساس متغیر پنهان (Latent variable )
هدف : با استفاده از الگوریتم EM، پارامتر های توزیع آمیخه(Mixture Model ) را بدست بیاوریم
قدم اول : مقدار دهی اولیه : Log Lokely hood را حساب می کنیم
قدم دوم : expectarion امید را حساب می کنیم
قدم سوم : مجددا پارامتر های استفاده شده را در وضعیت حاضر بدست میاریم
قدم آخر : فرض میکنیم Stop کردیم
موی کا ، سیگما کا و پای کا را بدست آوردیم
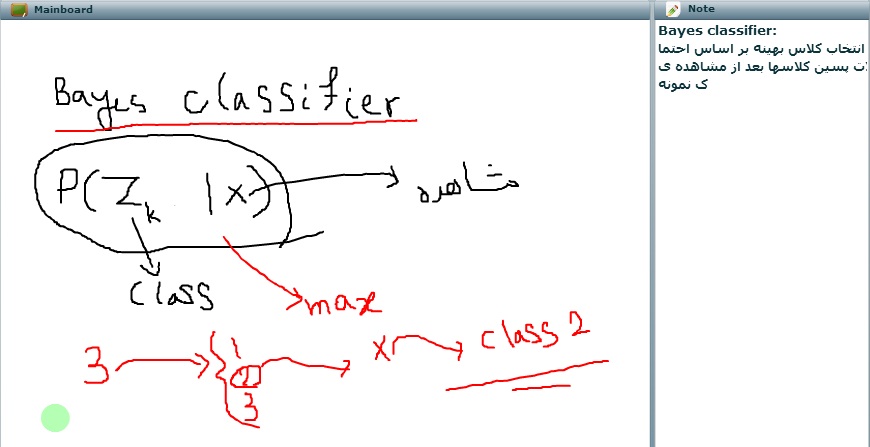
احتمال پسین هر کلاس به شرط مشاهده xi را حساب می کنیم
از قاعده بیز هر کدام که احتمالش بیشتر بود
داده کلاستر ۲ می شود
عمل انتصاب را انجام می دهیم
جلسه بعد AIC , BIC و همچنین Evaluation را می گوییم
پروژه :
برای پروژه درس از داده های شغلی تان استفاده کنید
مقاله از jornal international استفاده نکنید
از ۲۰۱۱ یا ۲۰۱۲ به بعد باشد