خلاصه درس تدریس یار داده کاوی – ۹۲/۰۷/۲۸
spss 14 modeler
File – Open – Demo
Source – Node Statistic files – Demos –
از لیست فایل ها فایل telco را انتخاب می کنیم
این فایل شامل ۴۲ ستون و ۱۰ ردیف هست
این فایل را برای مثال K میانگین و ۲ Step Cluster باز می کنیم
از بین لیست متغیر هایی که داریم ، چند فیلد را وارد کرده ایم
در این کار هدف این است که از ۴۲ متغیر با استفاده از این ۵ متغیر کار خوشه بندی داده ها را انجام بدهیم
۱۰ تا مشاهده داریم
به چند روش می توانیم این داده ها را خوشه بندی کنیم
قسمت Field – User Custom Setting را می زنیم
در کرکره Model اتوماتیک هست و یا نام دلخواهی را انتخاب کنیم
اگر از داده های بخش بندی شده استفاده کنیم
ما در سیستم K میانگین محدودیتی داریم که باید بدانیم به چند خوشه می خواهیم تقسیم بندی کنیم
به صورت پیش فرض ۵ خوشه داریم
آیا می خواهیم ستون مربوط به فاصله ها را
در کرکره بعدی Expert : آیا اطلاعاتی که داریم می خواهیم یک خوشه بندی ساده باشد یا اطلاعات کاملتری را هم بدهد.
اگر اجرا کنیم این شکل دیده می شود
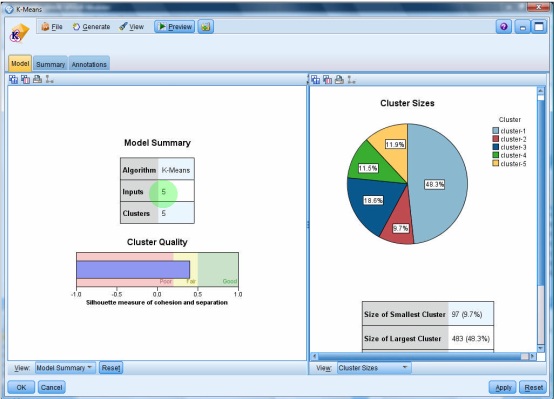
۵ تا خوشه ای که انتخاب کرده ایم
اگر تعداد خوشه های کمتری را انتخاب می کردیم ممکن بود مقدار سایه نما Siloet بهتری را داشتیم
در View گزینه cluster داریم
که می گوید چه ویژگی هایی وارد شده
در ردیف size درصد خوشه ها را نمایش می دهد
در پایین منو نمونه ها و جدول های دیگری را نمایش می دهد
Show Basic : درجه اهمیت و تعداد متغیر های موثر در خوشه بندی اعلام می کند.
متغیر های پیشگو : Predictor importance
Summary : خلاصه اطلاعات را می دهد
می توانیم چند بار از K-means استفاده کنیم
یک روشی دیگر داریم به نام ۲ Step Cluster
باید نرمال چند متغیره باشد
در k-means برای متغیر های کمی هست
و نمی توانیم از متغیر های کیفی استفاده کنیم
در سیستم ۲Step Clustering
امکان محاسبه فاصله برای متغیر های کیفی هم بوجود امده است .
قبلا خوانیم که باید داده ها نرمال چند متغیره باشد
Node 2 Step Cluster را اضافه کردم
با کلید f2 اتصال را برقرار کردم
DblClick که می کنیم روی ۲ step cluster
مشابه متغیر هایی که برای k-means انتخاب کرده بودیم اینجا هم انتخاب می کنیم
در تب Model گزینه ای برای عددی کردن داده ها وجود دارد
exclude outlier : مشاهدات پرت را از تحلیل حذف می کند
به صورت پیش فرض اگر بیش از ۳ داده پرت باشد از دور خارج می کند
برای نفر دوم ، سن نفر دوم را منهای انحراف میانگین نفرات می کند
بهینه تعداد خوشه ها می تواند تشخیص دهد
یا اینکه امکان این هست که تعداد کلاستر را اجبار کنیم
Distance Major : حداکثر درست نمایی : فاصله اقلیدسی هم داریم
معیار خوشه بندی بر اساس معیار بیضی شوارتز BIC یا AIC باشد