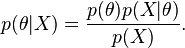SVM
Support Vector Mchine
ماشین بردار پشتیبان
شهرت این روش بخاطر تشخیص نوشته های دست نویسOCR بوده
از روش های شبکه عصبی بهتر بوده
SVM( جزو شاخه Kernel Method است )
شبکه عصبی به دنبال خطی بود که بتواند دسته بندی کند
در شبکه عصبی wi ها را update می کرد تا دقیق تر شود ( persepptorant
هدف : (Clustering – دسته بندی – Ranking – پاکسازی)
مسایل :نمایش الگو های پیچیده – پرهیز از overfitting )
اگر دو کلاس مثبت و منفی داریم باید بتوانیم با SVM از هم جدا کنیم
جدا کننده های مختلفی امکان دارد که باشد ولی کدام جدا کننده از همه بهتر است : خطی که از خط های مرزی بیشتری فاصله را داشته باشد.
معادله خط : w1X1+w2X2+b=0
که برای حال n بعدی هم قابل تعمیم است
آیا کاربرد ماشین بردار پشتیبان برای نقاطی هست که کاملا از هم تفکیک هستند ؟ خیر ، با ترسیم فضای چند بعدی می توان با این روش تفکیک را انجام داد.
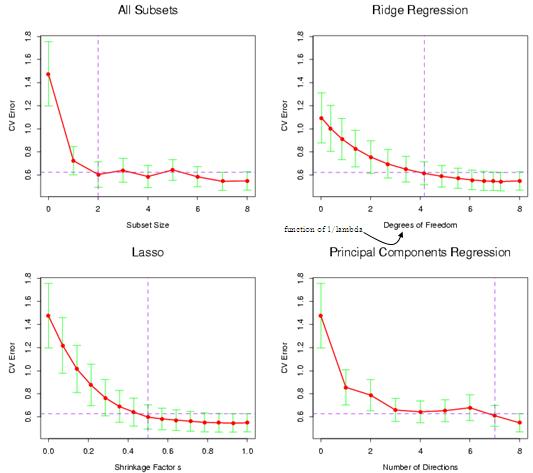
این جلسه تا ابتدای فرمول ها
چند لینک مرتبط با SVM
http://www.statsoft.com/textbook/support-vector-machines/
http://research.microsoft.com/en-us/groups/vgv/
http://www.idsia.ch/~juergen/rnn.html
http://jmlr.org/papers/volume1/mangasarian01a/html/node2.html
http://www.jvrb.org/past-issues/3.2006/760
http://docs.opencv.org/doc/tutorials/ml/introduction_to_svm/introduction_to_svm.html
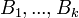 یک افراز برای فضای نمونه ای
یک افراز برای فضای نمونه ای  تشکیل دهند. طوری که به ازای هر
تشکیل دهند. طوری که به ازای هر 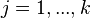 ، داشته باشیم
، داشته باشیم 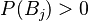 و فرض کنید
و فرض کنید  پیشامدی با فرض
پیشامدی با فرض  باشد، در اینصورت به ازای
باشد، در اینصورت به ازای 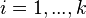 ، داریم:
، داریم:
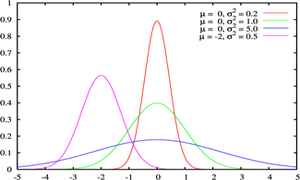
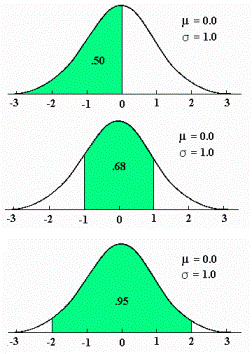
 (که مثلاً میزان رای به یک نامزد انتخابات را مدل می کند.) یک توزیع احتمالاتی است که میزان عدم قطعیت یک فرد را در مورد آن کمیت قبل از مشاهده داده نشان می دهد.
(که مثلاً میزان رای به یک نامزد انتخابات را مدل می کند.) یک توزیع احتمالاتی است که میزان عدم قطعیت یک فرد را در مورد آن کمیت قبل از مشاهده داده نشان می دهد. پس از مشاهده داده
پس از مشاهده داده  برابر است با
برابر است با 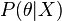 . اگر
. اگر 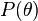 احتمال پیشین
احتمال پیشین