Jan 012014
خیلی وقت ها در داده کاوی مجبوریم Data Alaysis انجام دهیم
فرق Data Analysis با Datamining این است که در تحلیل داده ها فرضیه ای را مطرح می کنیم و در مورد صحت و سقم آن نظر می دهیم
ولی در داده کاوی سوال هنوز مطرح نشده
می بینیم چه سوال میشه از دل این داده ها در آورد
یکی از تکنیک ها کمتر شنیدیم جداول توافقی یا جداول پیشایندی هستند
clementine قوی ترین نرم افزار در جداول پیشایندیContigency Table هست
برای جدول یک بعدی و دو بعدی یک مدل بیشتر برازش نمیشود
اساس جداول پیشاوندی DataAlanysis هست
چون به این سوال می خواهیم جواب دهیم که
داده ها را به دو قسمت تقسیم بندی می کنیم
(کمی – کیفی)
داده های کمی به دو دسته ( پیوسته – گسسته ) تقسیم بندی می کنیم
داده های ترتیبی هم می تواند باشد
فرض هایی که در مورد داده های کیفی هست :
۱-در مورد درصد نظر می دهیم (درصد اقایان بیشتر است یا خانم ها )
۲- یا در مورد استقلال ، مثل (سیگار به سرطان ربط دارد ؟ )
Z test
chi square
سرطان – سیگار – جنسیت )- تعداد مدل ها خیلی زیاد می شود
مثلا درصد آرای ۵ کاندیدایی که در انتخابات شرکت می کنند
خطای غیر نمونه گیری و خطای نمونه گیری داریم
فر می کنیم ازمایش Multinomial داریم که حالت توسعه یافته برنولی هست
آزمایش های مولتی نومیال مانند باینومیال مستقل از هم و درصد احتمال هم یکی است
( اگر از یک نفر بپرسند که به کدام یک از این ۳ نفر رای می دهی احتمال انتخاب با نفر بعدی که پرسش می شود یکی است )
آزمایش مولتی نومیال n نفر را به تصادف انتخاب می کنیم
هر یک نفر که انتخاب شده اند به یکی از این k کاندیدا رای می دهند
شرط اول : اگر نفراول احتمال انتخاب p بود نفر بعدی هم احتمال p باشد
شرط دوم : رای نفرات از هم مستقل باشد
N=100
k=3
p=1/3
در جدول پیشایندی نمایش می دهیم ( جدول توافقی )
سوال: ایا ارای این سه نفر یکی است ؟
درآمار شاید ۳۵ با ۴۵ برابر باشد چون ممکن است خطای نمونه گیری داشته باشیم
بنابراین باید آزمون انجام بدهیم
chi Square Test
به دنبال یک استراتژی منطقی برای Treshould که بتوانیم مقایسه کنیم
چون می شود ثابت کرد که این treshold
آمار آزمون همون استراتژی منطقیمون هست
آمار آزمون میاد تعداد مشاهدات را در مورد p1 انجام شده است n1 Observed Value منهای exepected Value
مقایسه را زمانی انجام می دهیم که فرض H0 درست باشد
استقلال را جدول دو بعدی می گوییم
با داده های کیفی در مورد استقلال صحبت می کنیم
در تست استقلال برای جداول دوبعدی مطرح می کنیم
مانند شرایط قبل آیا ارتباطی بین
فرض ها Mulinomial experient هست
فرض H0 آیا نوع خانه و مکان ساخته شده آیا با هم وابسته هستند و یا مستقلند
اگر وابسته نباشند درصد خانه ها چقدر است ؟
expected =حاصلضرب …. تقسیم بر تعداد کل
جدول توافقی دو بعدی
اگر قرار باشه مکان و نوع ربطی به هم نداشته باشند
۱۱۲/۱۶۰ تابع چکالی کناری Marginal
باید تابع چگالی توام مساوی
از نظر شهودی اگر آزمایش انجام دادیم که با آزمایش دیگری از نظر فیزیکی ربطی به هم نداشت از نظر ریاضی هم مستقل هستند
احتمال joint را چجوری حساب می کنیم ؟
احتمال ۶۳ مشیه حاصلضرب این دو احتمال
و وقتی می خواهیم Expected را انجام دهیم ….
در این جلسه در باره جدول توافقی وجدول chi square
صحبت شد
سه فصل امتحان می گیریم
– فصل ۱ و ۲ کتاب Tan به صورت تستی
– خوشه بندی از جزوه انگلیسی و به عنوان کمکی جزوه فارسی می توانید استفاده کنید
– Asociation Role ها
بارم نمرات : ۶ تا ۸ نمره پروژه و ۱۲ تا ۱۴ نمره امتحان دارد
الگوریتم SVM در Clementine
SVM معمولا برای داده های بزرگ به کار می رود
SVM – Support Vector Machine از خانواده یادگیری ماشین و هوش مصنوعی هست
معمولا زمانی از این روش استفاده می کنیم که حجم داده ها خیلی زیاد باشد
مثلا راجع به داده های پزشکی ، سلولهای سرطانی کاربرد دارد
در اینجا مثالی که در Clementine هست کار می کنیم به نام Cell_samples
در این مثال متغیر Clump مشخص کننده سرطانی بودن سلول هست
متغیر ها به عنوان اندازه، شکل ، رنگ , آورده شده است و متغیر های دیگر همچنین فیلد خوش
خیم بودن سلول یا بدخیم بودن آن
که برای سلول های خوش خیم و بدخیم اطلاعات را دسته بندی می کنیم
برای این کار داده های آماده در کلمنتاین به نام Cell Samples Data که از نوع fixfile است ، می
آوریم
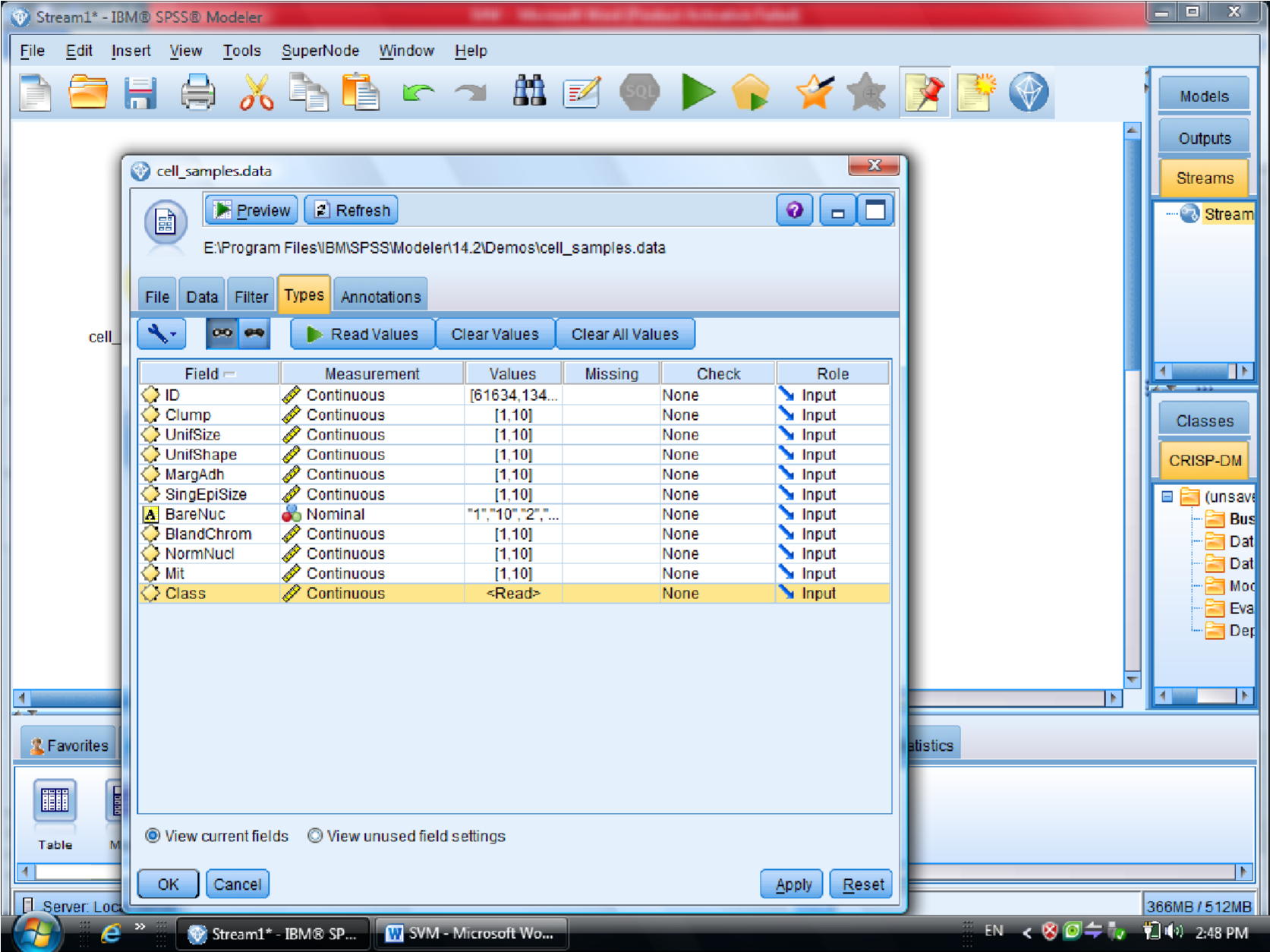
در این دیتا ست ، فیلد ID چون جزو متغیر های موثر نیست آن را فیلتر می کنیم (ID رو Typeless
کردیم)
متغیر class را به عنوان Target معرفی می کنیم (فیلدی که خوش خیم بودن سلول را مشخص می
کند )
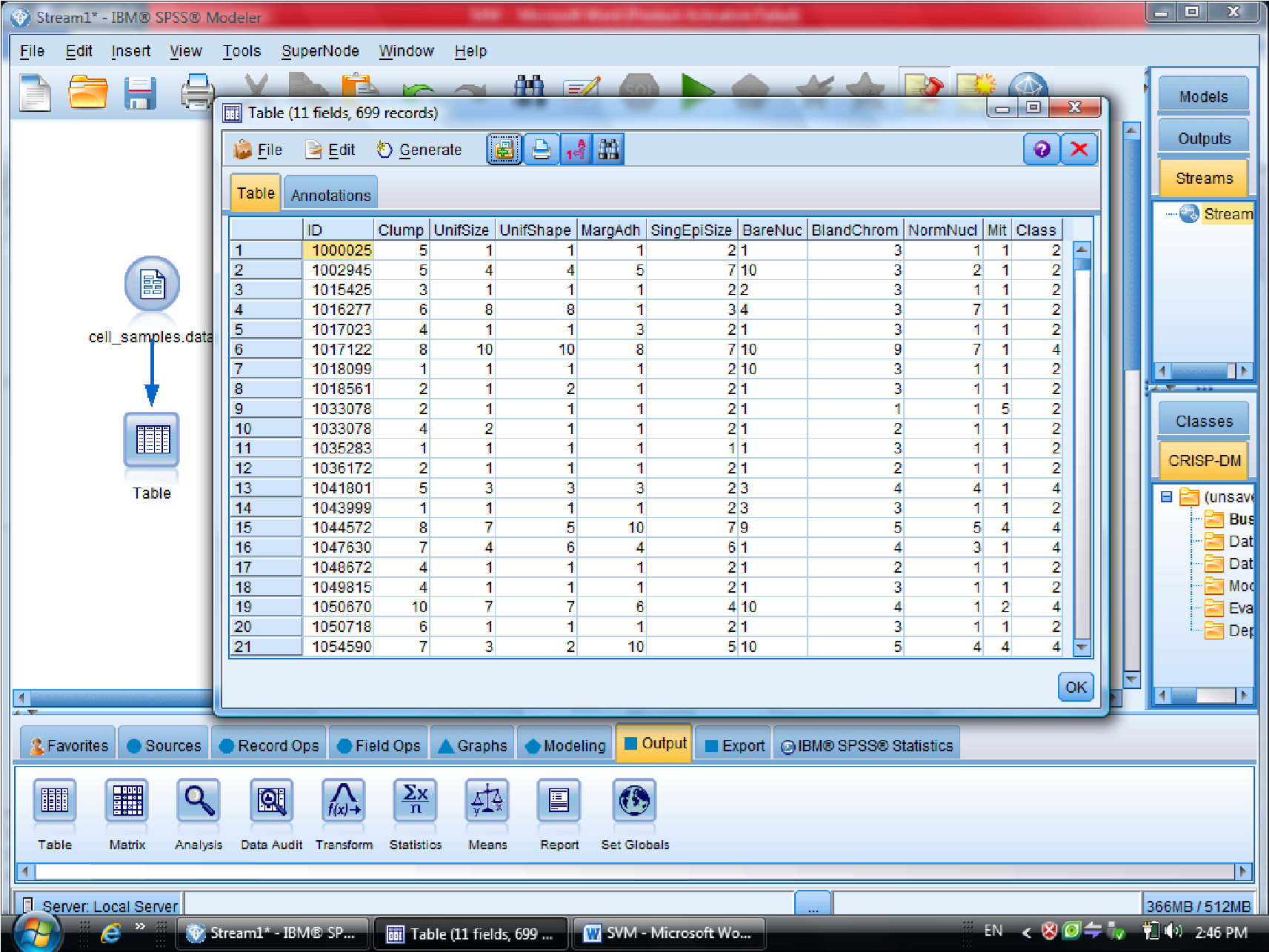
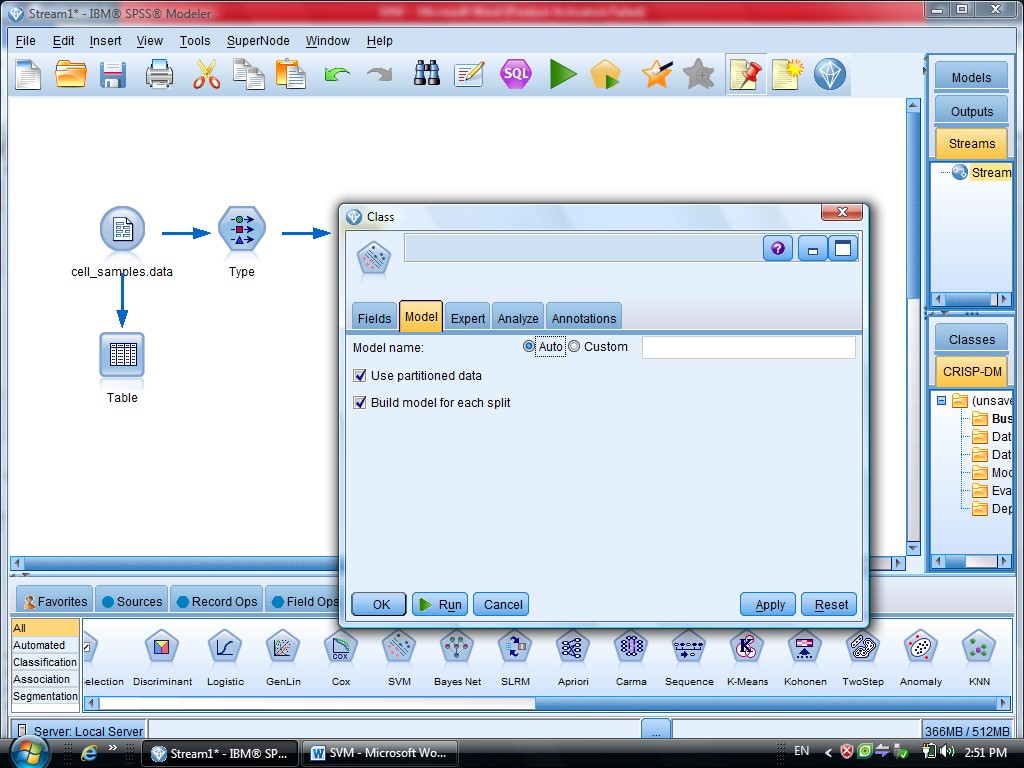
بعد از Type مدل SVM را قرار می دهیم
در گزینه type – SVM – Field متغیر های مستقل هستند ، همه متغیر های دیگر دخیل هستند
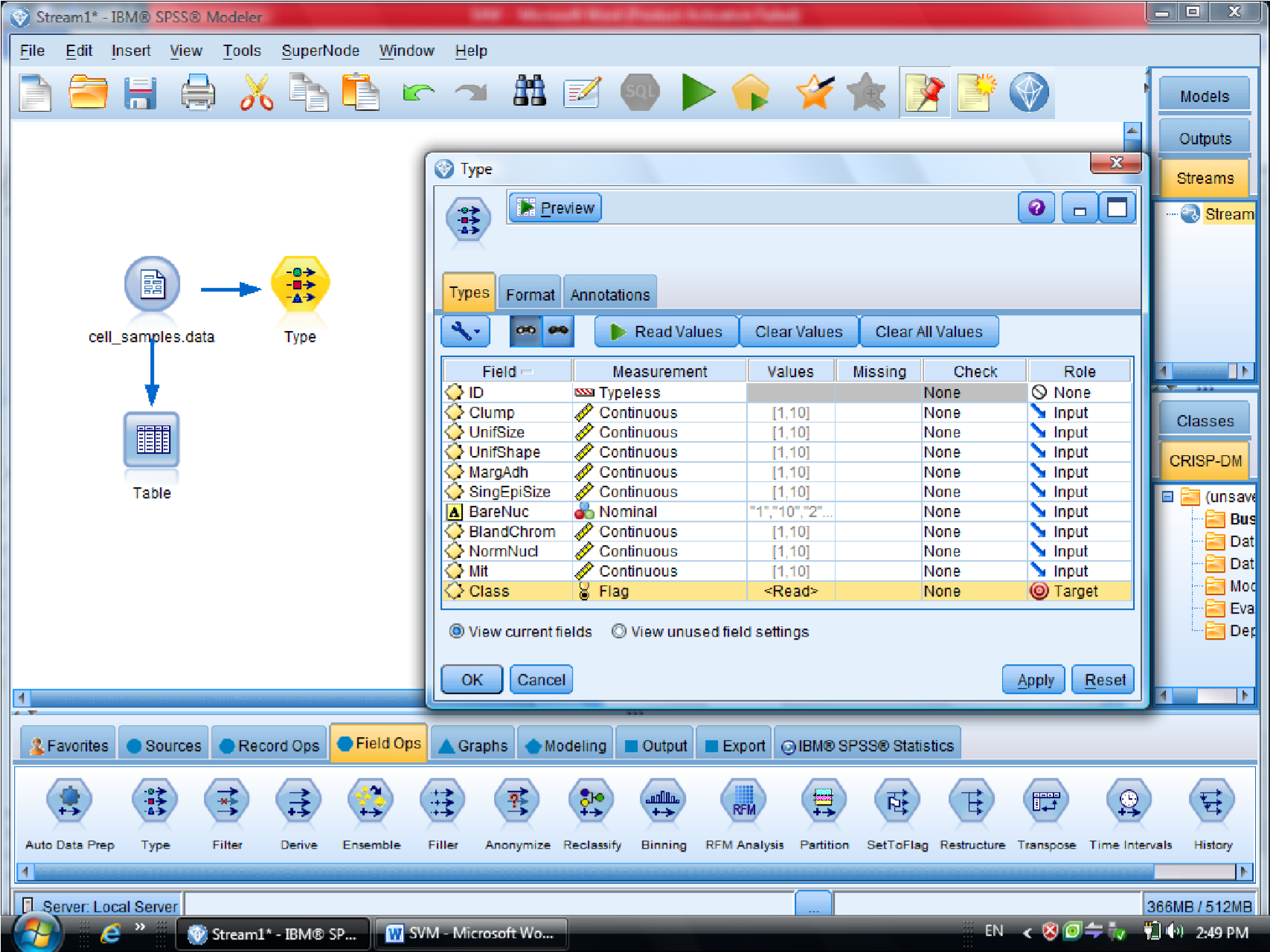
گزینه Expert در متد SVM دو گزینه sample , Expert را داریم
که ما از گزینه Expert استفاده می کنیم برای اینکه بتوانیم چند روش برای دسته بندی داده
استفاده کنیم
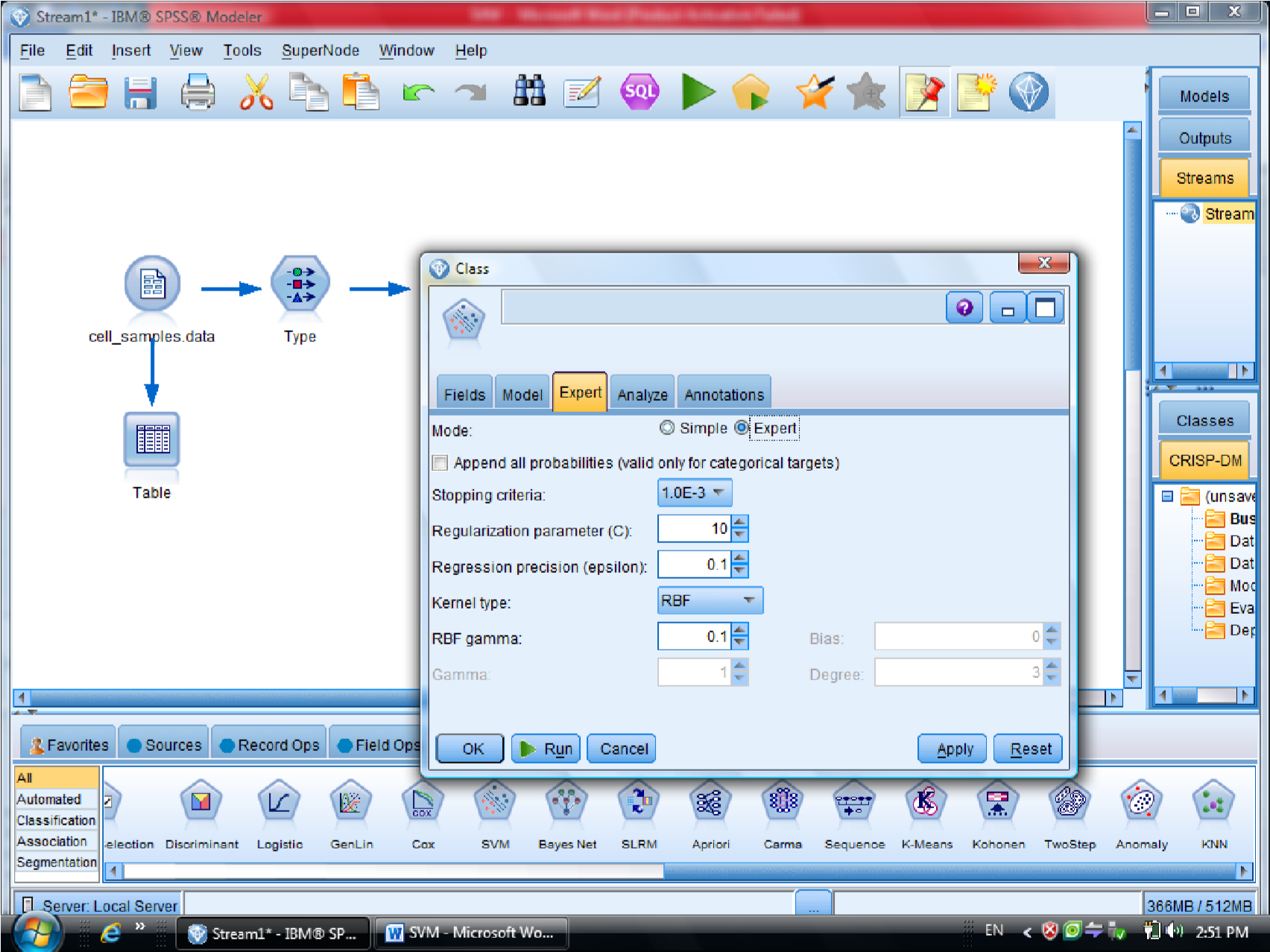
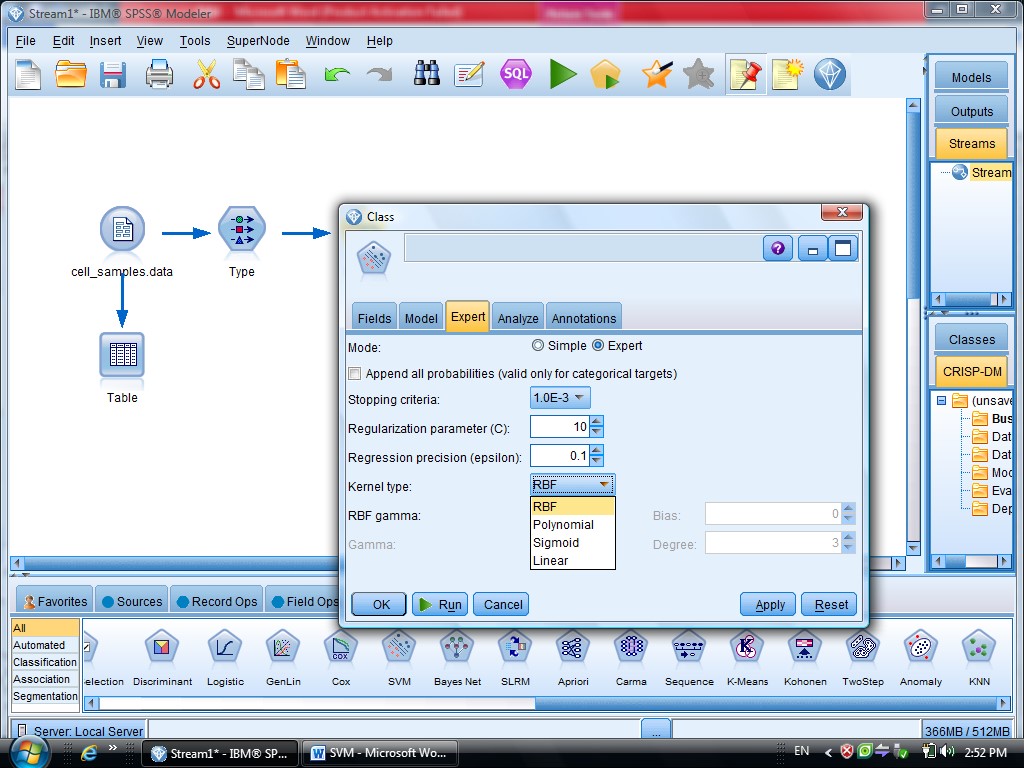
در SVM از تابع Kernel استفاده می شود
درجه وابستگی متغیر ها را می توانیم با SVM مشخص کنیم
گزینه Model مربوط به مدل آیا دیتا های ما از چند قسمت تشکیل شده اند یا خیر
کرکره Expert دو گزینه دارد (Simple , Expert)
یاد آوری می شود روش های SVM از تابع کرنل هست
ممکنه روشهای مختلفی استفاده کنیم
با انتخاب گزینه Expert می توانید از توابع Kernel استفاده کنیم
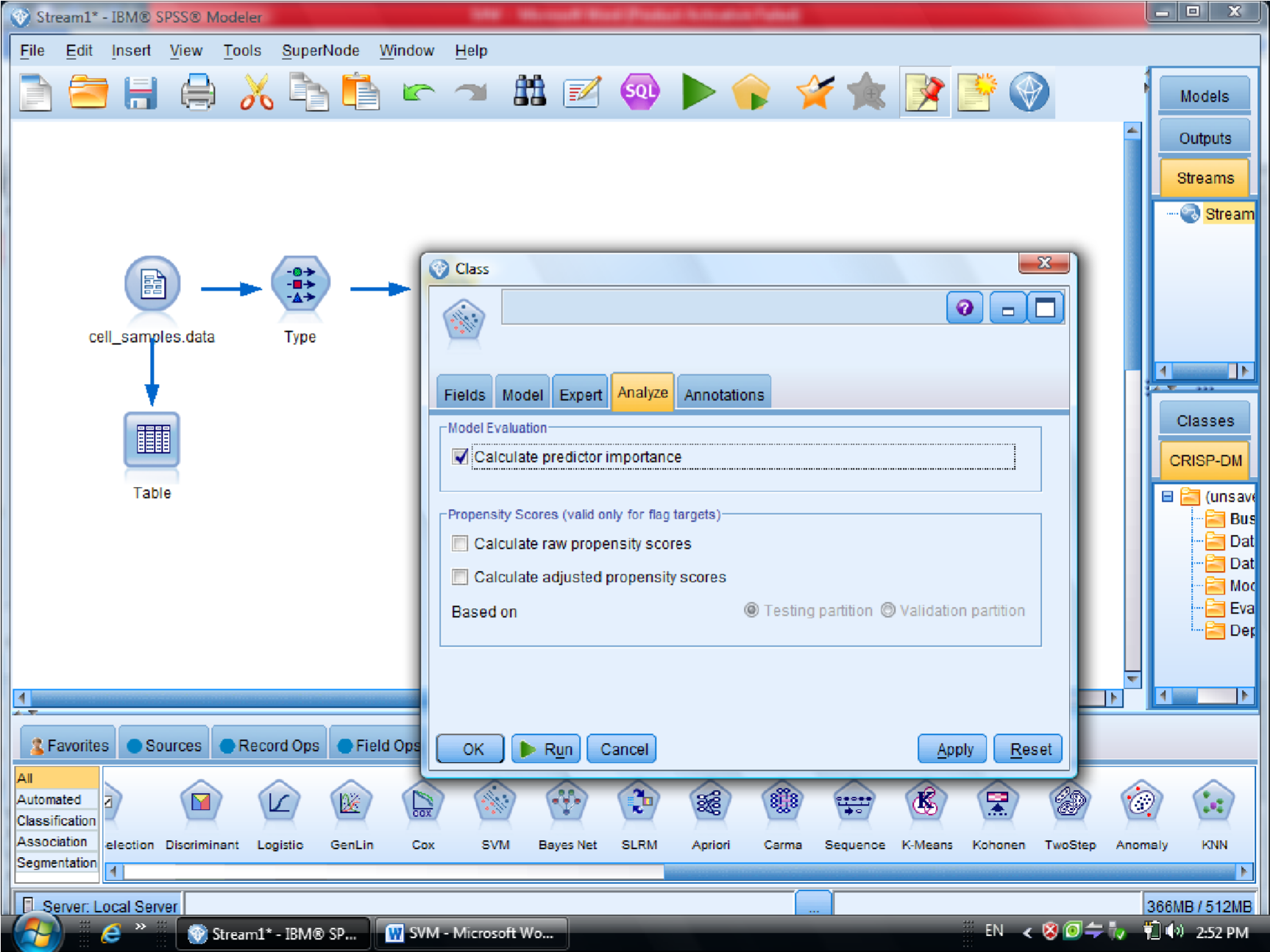
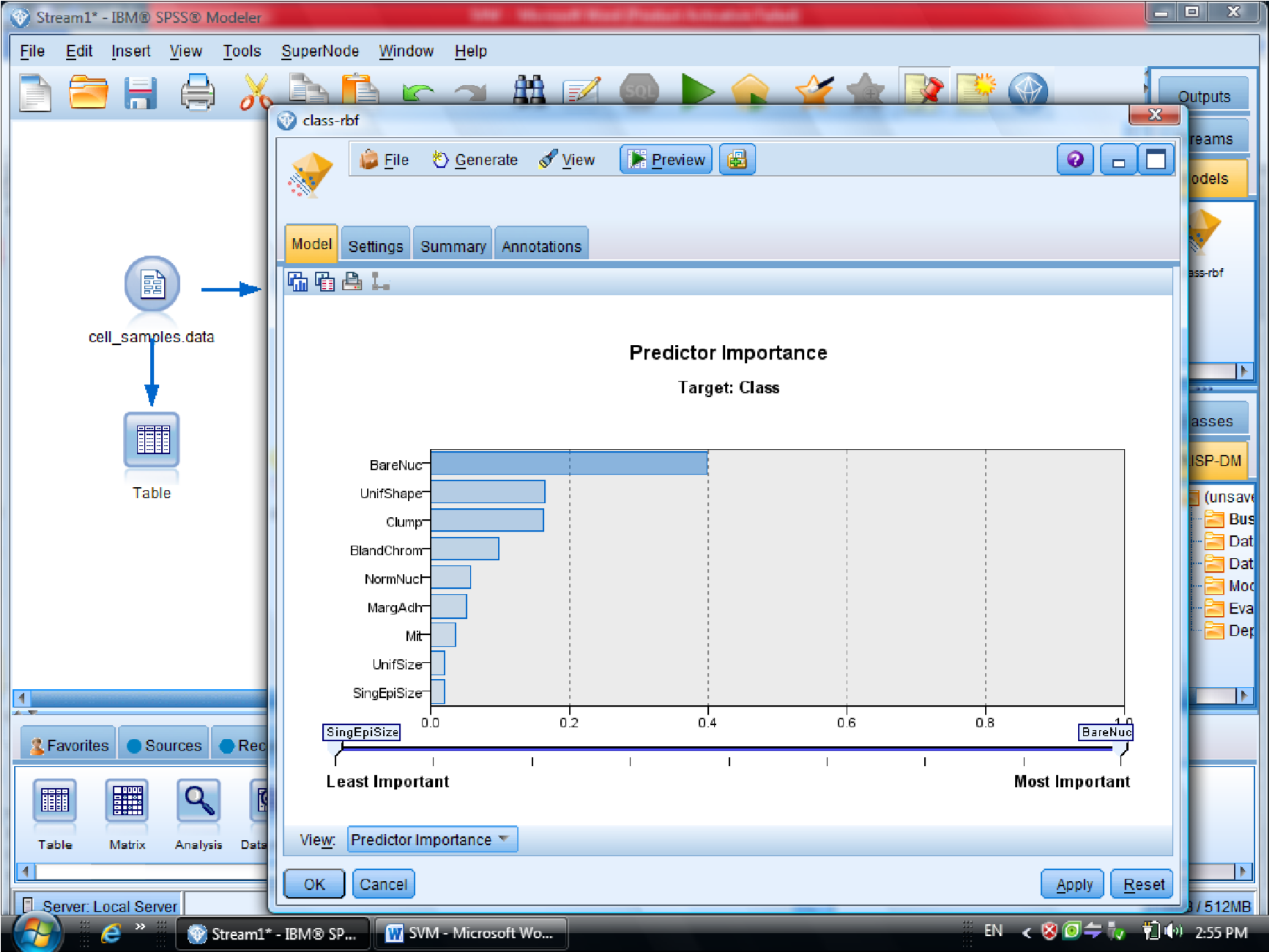
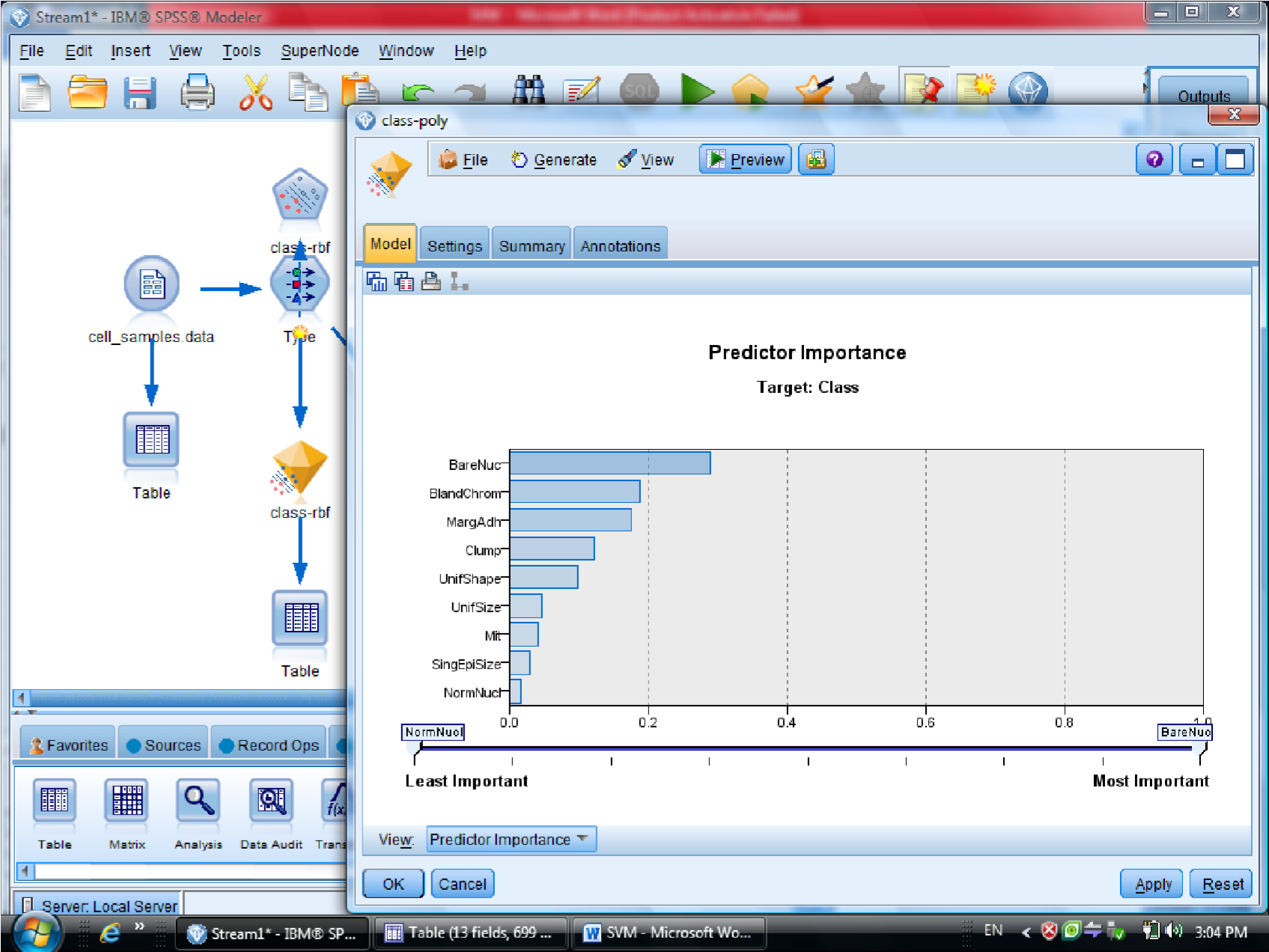
در قسمت اول متغیر ها را بر اساس درجه اهمیت نشان می دهد
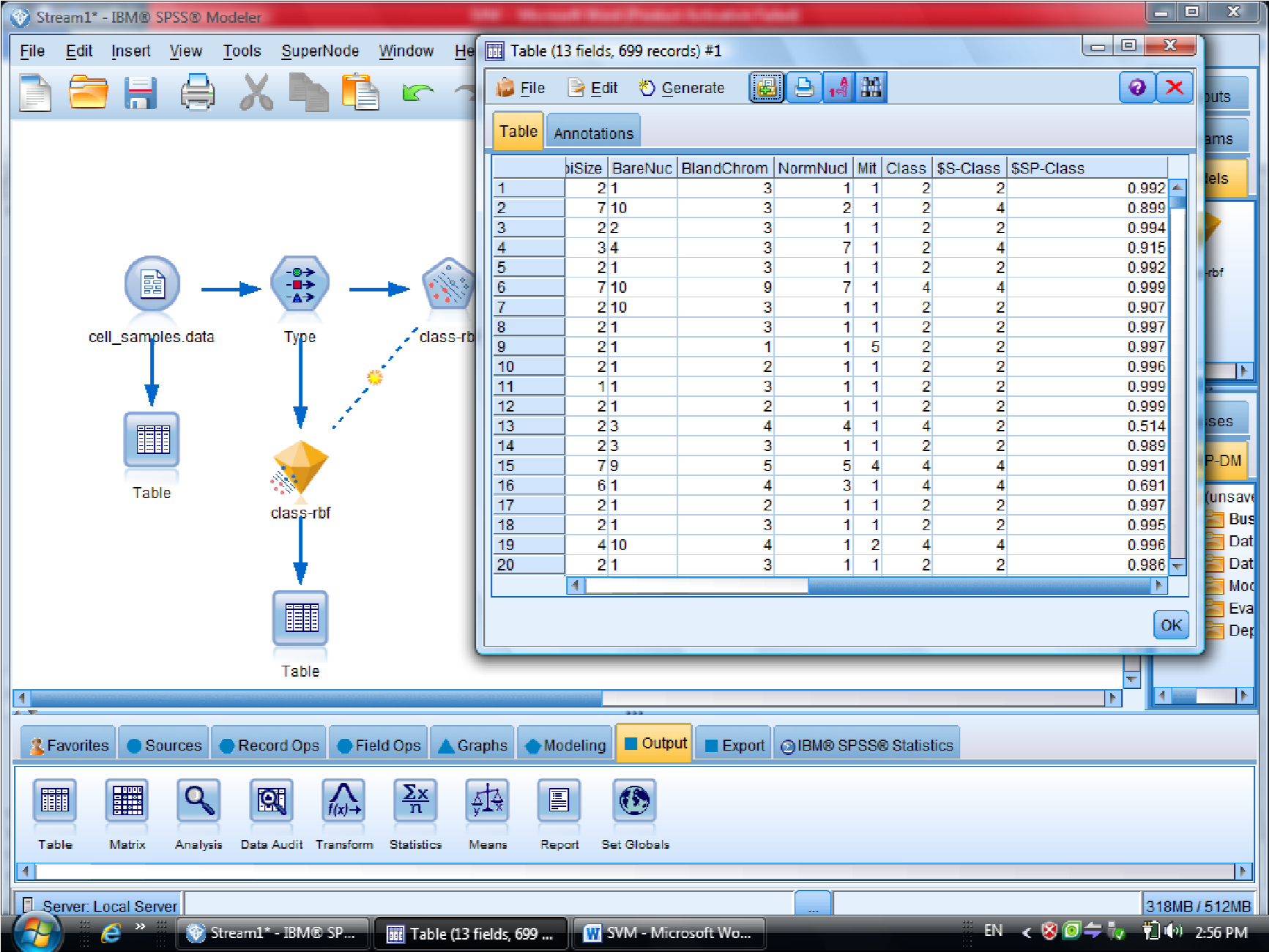
احتمال برای درست پیش بینی شدن را می دهد
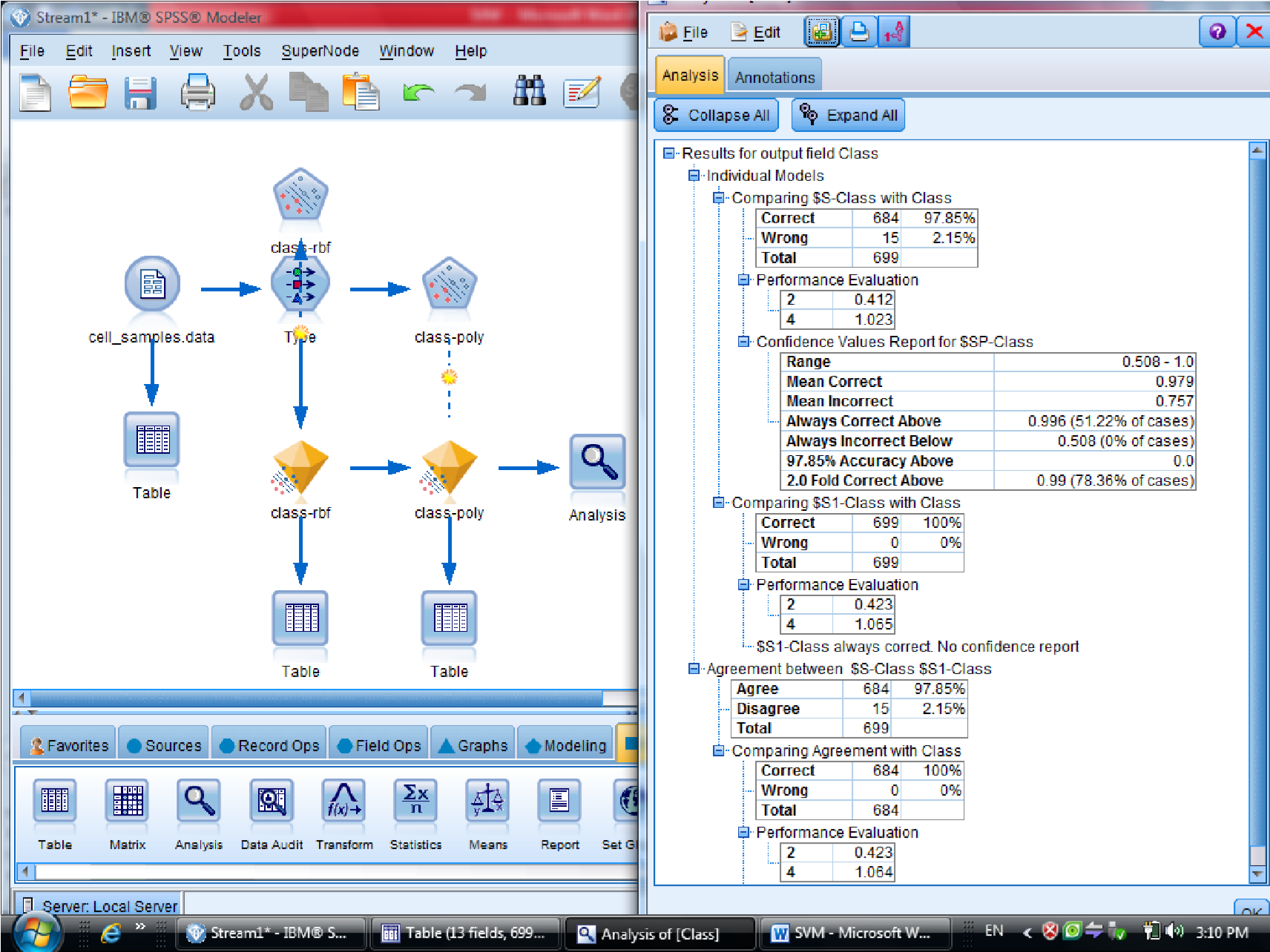
یکبار به روش RBF خروجی گرفتیم
این مقدار احتمال ها ممکن است خیلی به ۱ نزدیک باشد
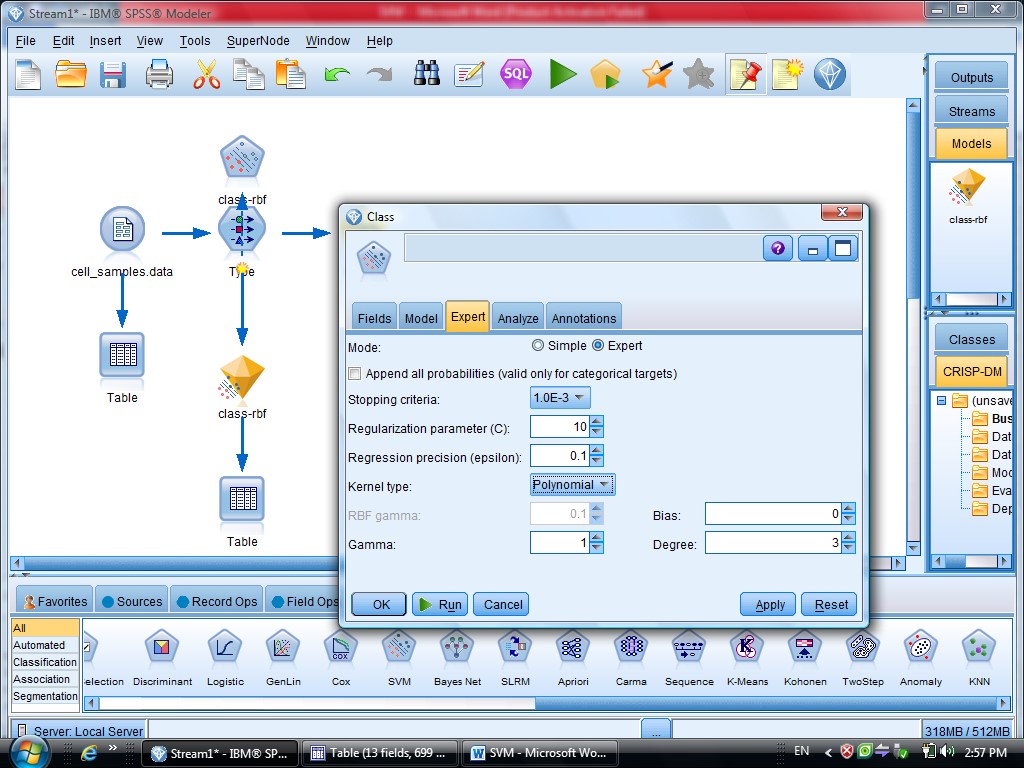
به روش Polynomial (چند جمله ای )، خروجی مربوطه برای متغیر هایی که این فرم را دارند
میزان دقت polynomial صد در صد هست
برای مقایسه دو نتیجه دو تا الماس زرد را با هم مرتبط می کنیم ( با F2 )
و به Analysis وصل می کنیم تا مقایسه این دو نود را ببینیم
در نهایت متدی که به ۱۰۰ نزدیک تر هست ، روش مناسب تری هست
درصد دیتاهایی که درست تشخصی داده را ۰٫۹۷۹ هست
سلول های سرطانی خوشخیم که با ۲ علامت گذاری شده هست ، با احتمال اشتباه بیشتری
هست
در روش دوم ( polynomial ) میزان دقت سلول سرطانی ۱۰۰% هست
ولی برای سلول های سرطانی خوشخیم درجه احتمال بیشتری را خواهد داشت
پس بین این دو روش polynomial بهتر است
این مثال در فصل هشتم داده کاوی و کشف دانش گام به گام با Clementine خانم علیزاده هست
fine
داده کاوی و کشف دانش گام ب گام با نرم افزار Clementine علیزاده د.خواجه نصیر
یکی از روشهای مورد استفاده از متد های شبکه عصبی در داده کاوی هست
مثلا رگرسیون ارتباط متغیر های وابسته به متغیر های مستقل نشان می دهد
مثلا شرکت ها چقدر بدهی داشته باشند
سوالات :
سوال اول تعریفی است
مثلا desicion Tree
الگوریتم هایی که استفاده می کنید
درجه اطمینان و میزان پشتیبانی
روشهای خوشه بندی – kmeans خوشه بندی کنید
با Complete Linckage یا Average Linkage
آزمون تمام مطالب سر کلاس هست
 Continue reading »
Continue reading »
کلاس حضوری داده کاوی – ۹۲/۰۹/۲۱
آقای مهندس حائری – مرکز افکار سنجی جهاد دانشگاهی
دموی تمام الگوریتم ها را ببینید
در داده کاوی ممکن است یکی از کار های بخواهیم
توصیف
مقایسه کردن ( با استفاده از الگوریتم های t , z , Anova , Manova امکان پذیر است )
بررسی رابطه (ضریب همبستگی یا ضرایب پیوند – انواع رگرسیون )
رده بندی و خوشه بندی (درخت تصمیم – درخت رگرسیونی)
پیش بینی (time series)
دانلود رکورد کلاس حضوری دکتر محمد پور
خلاصه جلسه داده کاوی – حضوری – دکتر محمد پور
کاری که PCA انجام می دهد تعداد متغیر ها را کم می کند
ایراد های عمده PCA :
۱- مفهوم متغیر ها را عوض می کند
( ماتریس واریانی – کواریانس )
ماتریس واریانس را حساب می کنیم با ترانهاده اش ماتریس واحد شود
اگر بردار وِیژه را بدست بیاوریم ماتریس متعامد را بدست می آوریم
نتیجه : متغیر ها وابستگی به هم ندارند
بدی PCA داده های برست آمده ترکیب شده هستند
درPCA های مختلف مقایسه کار سختی است
دومین اشکال PCA : باید بردار ویژه و مقدار ویژه را پیدا کنیم
بعضی مواقع متغیر ها بسیار زیاد است محاسبه بردار وِیژه و مقدار ویژه کار بسیار سختی می شود
اشکال سوم PCA : داده ها
Uncorrolocated می شود
رابطه خطی با هم ندارند
مزیتهای PCA :
۱- بر اساس واریانس عمل می کند
به اندازه مقدار ویژه به خودش اختصاص می دهد
———————–
برای کلاسترینگ هیچ وقت از PCA استفاده نمی کنیم – فقط برای کاهش بعد استفاده می کنیم
——————————
روش Random Projection :
مزیتها :
۱- هزینه محاسباتی ناچیز است
۲- فاصه نقاط را حفظ می کند
آیا می توانید روشی را ارائه دهید که هم بعد را کم کند و دقت کاهش پیدا نکند
Stable Random Projection پایان نامه دکتر زارع
هر توزیعی یک نرمی را حفظ می کند
در روش های آماری جایی باشد که دیگر دقت کم نشود
تغییر ظرح نمونه گیری می گوییم
بعضی وقتها حجم نمونه
نحوه نمونه افراد را تغییر دهیم
واریانس این بر آورد گر نصف قبلی می شود
روش مکنتایر – در استرالی بر آورد محصول گندم را بدست آورد
در مساله کلاسترینگ یک نوع مثال بیاورید که داده ها را بعدش را کم کنیم و دقت کاهش نیابد
Ranked Set Sampling
———————
سوالات امتحان :
– Association Analysis
Clustering فارسی با فصل ۱۴ کتاب سلسه مراتبی تقریبا یکی است
DataMining-Tan-SolutionManual.pdf – سوال ۵ نمی آید
———————-
ICA
BSS :
سه نفر به سه میکروفن حرف بزنند ، صحبت ها قاطی می شود
Blind Source Seperation
جدا سازی منابع کورکورانه
مثلا یک سیگنال داریم که سیگنال اصلی را نداریم
چطور با استفاده از X بتوانیم S را بسازیم
فرض می کنیم معادله خطی بوده S=AX
ممکنه نویز هم داشته باشد S=AX+e
خلاصه درس داده کاوی – دکتر محمد پور – ۹۲/۰۹/۱۸
برنامه ارائه مقالات کنفرانس داده کاوی در لینک ذیل قرار دارد:
http://dl.irandatamining.com/users/uploads/BarnamehConference.pdf
امروز در مورد محک های ارزیابی تجربی صحبت می کنیم
سه روش مشهور داریم
که معروفترینشان Cross validation هست
اگر از روش هایی استفاده می کنیم فقط دستورش را ببینیم در clementine هر کدام یک مدل با فرض های مختلفی هستند
و بهتر بودن هر کدام مشخص نیست
با اینکه همه خوشه بندی انجام میدهند ولی ممکن است در ارزیابی موفق نباشند
انتخاب مدل مناسب کار بسیار سختی است
در مرحله ارزیابی مدل را تست می کنیم
از داده ها استفاده می کنیم ببینیم چقدر می تواند پیشبینی را انجام دهد
اگر روشی جدید ابداع کردید باید صحت پیشبینی آن از بقیه روشهای بهتر باشد
قابل تعمیم بودن
قابل تفسیر بودن : روش ما باید قابل تفسیر باشد
سادگی
کیفیت نشانگر ها Domain-Dependent quality indicators
————
چطور خطا را حساب می کنیم
با تابع Loss Function
ساده ترین آنها Zero Loss Function است
امید Loss میشه Risk
در مساله خوشه بندی خیلی ساده تعداد ۱ ها بخش بر n می شود
در خوشه بندی وقتی می خواهیم Evaluate کنیم
Nc تعداد داده های درست کلاس بندی شده
Nt تعداد کل
درصد درست کلاس بندی شده هاست
e درصد اشتباه کلاس بندی شده هاست

C اپسیلون داد ها
هزینه برای داده های بد کلاس بندی شده ها
miss clasification Cost
اگر بخواهیم به صورت نظری
COLT typical research questions
با داده های مثال از پیش تست شده روش جدید را می توانیم تست کنیم
چرا ؟ چون باید در بدترین شرایط تست شود
Emprical evaluation
سعی و آزمون
مثلا به تصادف چند داده را انتخاب کنیم
Resampling : ( باز نمونه گیری ) چند بار به صورت تصادفی انتخاب میکنیم میانگین آنها را محاسبه می کنیم
BootStrap : Resampling با جایگذاری است
Hold out برای داده های بزرگ کاربرد دارند
k-fold Cross Validation :
خیلی ها اتفاق نظر دارند که این روش خیلی بهتری است
در این روش جای داده های train و test عوض می شوند
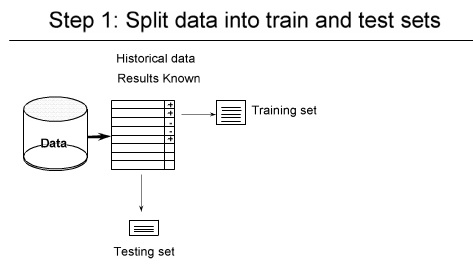
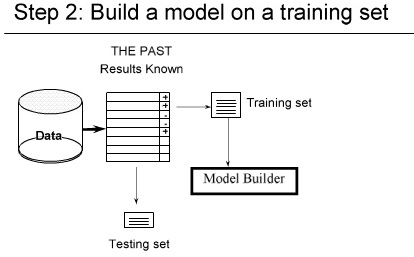
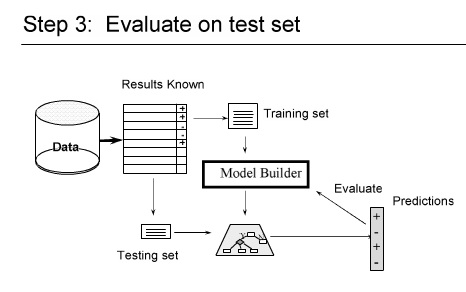
۱- شکستن داده ها ( به صورت تصادفی ) مثلا یک سوم test دو سوم tranining
۲-
۳- داده هایی را که برای تست در نظر گرفتیم خطا ها را حساب می کنیم
——————————–
در Hold-out ما overlapping داریم
ولی در Cross-validation بحث overlapping را نداریم
اگر بخواهیم دو الگوریتم را با هم مقایسه کنیم
از روش های آماری می توانیم استفاده کنیم
خلاصه جلسه تدریس یار داده کاوی – ۹۲/۰۹/۱۷
برای روابط می توانیم از روش های آماری مختلف استفاده کنیم
مثل رگرسیون
می توانیم از جداول دو بعدی (توافقی) هم استفاده کنیم
اگر متغیر هایی که ما می خواهیم بررسی کنیم هر دو کمی باشند می توانیم از ضرایب همبستگی
پیرسون استفاده کنیم
بعضی مواقع روابط بین متغیر ها هر دو ممکن است کمی نباشند
و یکی از آنها کیفی ترتیبی باشد
مثلا در آمد افراد با سن افراد نسبتی را بدست بیاوریم
رابطه بین دو متغیر را با پیرسون مشخص می کنیم
ضریب همبستگی فقط شدت و جهت متغیر ها را نشان می دهد
چه رابطه ای بین متغیر مستقل و ثابت وجود دارد ؟
کدام متغیر روی دیگری اثر می گذارد ؟
آیا سن روی در آمد تاثیر می گذارد ؟
سن به عنوان متغیر ورودی ، تاثیر گذار
در آمد به عنوان متغیر تاثیر پذیر
به این دلیل که درآمد که نمیتواند روی سن تاثیر بگذارد
بنابراین از روش های رگرسیونی استفاده می کنیم
در روش های رگرسیونی متغیر وابسته چیست ؟
متغیر وابسته ما مقدار کمی است
اگر متغیر وابسته بین صفر و یک باشد رگرسیون معمولی نمی توان گرفت
ممکن است رگرسیون لوجستیک دو حالتی را انتخاب کنیم
اگر پاسخ کمی و عددی باشد ممکن است رگرسیون پواسن را انتخاب کنیم و یا رگرسیون دو جمله
ای منفی
اگر متغیر کیفی ترتیبی باشد …
اگر متغیر وابسته عددی باشد …
در رگرسیون خطی آیا فرمولش مشخص است؟
فرم رگرسیون خطی را باید مشخص می کنیم
در فیلد های کمی سرشماری می تواند به عنوان متغیر target استفاده شود
بعضی از پیش فرض ها ذهنی هستند
مثلا در مناطق مرفه نشین خانه ها بزرگ تر ، انرژی بیشتری مصرف می کنند
اگر متغیر ما تحصیلات باشد و به آن کد اختصاص داده باشیم باید آنرا به متغیر های مجازی تبدیل
کنیم
مثلا متاهل =۱ و مجرد=۰ قرار می دهیم
برای تحصیلات فوق دیپلم =۰ یا ۱ ، لیسانس = ۰ یا ۱ ، فوق لیسانس =۰ یا ۱
(فقط صفر و یک )
مثلا برای در آمد
income = a + B1.Age+B2.Edj1+B3.Edj2+B4
جدول آنالیز واریانس را در خروجی می بینیم
برای مثال در فایل دیتای نمونه telco را کار می کنیم
در گزینه Expert گزینه include را می زنیم
در گزینه output علاوه بر دو تیک بالایی که خلاصه مدل و اطلاعات مربوط به ضرایب رگرسیونی را می دهد ضرایب جزیی و نیمه جزیی را می دهد
در کرکره analyze می زنیم
اینکه کدام از یک از متغیر ها در مدل تاثیر دارد نشان داده میشود
در کرکره summary خلاصه را می بینیم
در کرکره Advanced گزینه های پیشرفته را داریم
در جدول correlations ضرایب همبستگی متغیر ها با هم نشان داده می شود
متغیر هایی که خارح شمد و داخل شدند در جدول Variables Entere/Remoed نشان داده می شند
در model Summary نشان دهنده شدت همبستگی همه متغیر های وابسته با متغیر مستقل را نشان می دهد
به فرم درصدی نشان داده می شود
R square ضریب تعیین کننده است ، هر چه به ۱ نزدیک تر باشد نشان دهنده این است که متغیر ها خوب است
و هر چقدر به صفر نزدیک باشه نشان دهنده خوب نبودن متغیر های وابسته هست
آماره durbin-watsin هر چقدر از ۲ فاصله بگیرد ، ناخالصی را نشان می دهد
اگر آماره durbin-watsin بین ۰ و ۲ باشد نشان دهنده خود همبستگی مثبت است
اگربین ۲ تا ۴ باشد یعنی بین متغیر ها نتوانسته رابطه خوبی را تشخیص دهد
جدول آمالیز واریانس ANOVA
آیا مدل رگرسیون که انتخاب کردیم مدل مناسبی هست ؟
ویژگی های آماری
ستون درجه آزادی
ستون آماره F
sig – significant level سطح معنی داری (اگر از ۰٫۵ کتر باشد نشان دهنده این است که متغیر ضریبش مخالف ۰ است )
می خواهیم ببینیم که بیشترین تاثیر را دارد ستون بتا را می بینیم
صرف نظر از اینکه مثبت یا منفی باشد ، عدد نشان دهنده بیشترین تاثیر را نشان می دهد
zero-order
partial ضریب همبستگی سن و درآمد را وقتی مابقی متغیر ها هم اثر را گذاشتند و این اثر را حذف کردیم
Part ضریب همبستگی نیمه جزیی بین سن و در آمد ، همه متغیر ها روی متغیر وابستهاثر گذاشتند و ثابت مانده اند ( حذف نکردیم )
Col
بعضب مواقع بین متغیر ها رابطه رگرسیونی اجرا می کن تا بین متغر ها رابطه همخطی نباید وجود داشته باشد
ستون vif باید زیر ۱۰ باشد
در جدول بعدی مقادیر ویژه و مقادیر شرطی را مطرح کرده
شاخص شرطی هم باید زیر ۳۰ باشد
در قسمت variance proportions
وقتی عرض از مبدا اثر می گذارد سن دیگر نقش موثری ندارد
جدول آخر مقادیر پیش گویی شده را نشان می دهد
مشاهدات واقعی منهای جواب پیشگویی
SVM
Support vector Machine
از روشهای هوش مصنوعی است مثل درخت های تصمیم گیری بر اساس یک متغیر هدف خاص که
ترجیحا از جنس کیفی باشد
داده ها را می خواهیم پیشگویی کنیم
ستون ID را بدون فرمت می کنیم (Typeless)
متغیر اصلی و هدف class هست
از پارامتر عرض ازمبدا که پیش فرض را ۱۰ گرفته است استفاده می کنیم
مهمترین متغیر های موثر را به ما نشان میدهد
یک گزارش از مقاله Datamining Report حداکثر ۳ صفحه بنویسید
موعد تحویل پروژه ۲۳ دی ماه است
بررسی پایان نامه خانم نعمت الهی به عنوان نمونه
فصل ۱ و ۲ که مقدمه هست ، فصل ۳ و نهایتا فصل ۴
فصل چهارم : پیاده سازی فرایند داده کاوی بر روی داده های هزینه و در آمد خانوار های شهری
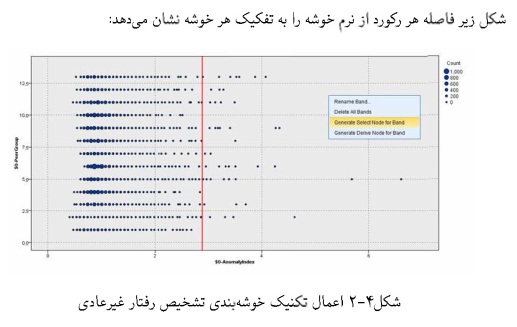
در فصل ۲ روی داده ها تحلیل خوشه ای انجام میدهید
قواعد پیوند
نکات :
فهرست اشکال نیاز نیست
عنوان فصل نیاز نیست
مرجع صحیح است ، منبع که می نویسید نشان از کپی کردن دارد
می نماید ، می نمایید استفاده نمی شود به جایش از فعل کرد استفاده کنید
فایل تبدیل شده به PDF را نگاه کنید که بهم ریختگی نداشته باشد
آمار های رسمی Official Statistic : آمار هایی که دولت جمع آوری می کند
در Data Analysis یک فرضیه مطرح می شود با روش های آماری قبول یا رد می شود
ولی در داده کاوی فرضیه از قبل نداریم ولی اگر در داده کاوی Data Alanysis هم استفاده
کردید بد نیست
بزگترین چالش داده کاوی Data Quality هست ، خطای نمونه گیری هم جزء اشکالات هست
لازم نداریم یک روش را توضیح بدهیم ( مثل k-means )
تحلیل خوشه ای
قواعد پیوند
امتحان از دو بخش Hirarchical Clustering و قواعد پیوند می گیریم
یک صفحه A4 می توانید سر جلسه بیاورید ، ولی موبایل و تبلت نمی شود
تحلیل خوشه ای باید انجام بدهید
کتاب الکترونیکی خوشه بندی دکتر حسین هوشیار منش را بخوانید
خلاصه مباحث درس Celementine 92/09/03
الگوریتم Quest
Modeling –> Feauture Selection
اگر بخواهیم از بین مولفه های زیادی چند گزینه را انتخاب کنیم
باید تک تک متغیر ها را با متغیر هدف مورد مطالعه قرار دهیم
و آن متغیر که تاثیر بیشتری دارد را نگه می داریم
پس ما به دنبال متغیر های مناسب هستیم
Modeling –> Anomaly
با استفاده روش های تحلیل خوشه با حضور چند متغیر پرت هستند شناسایی کنیم (Anomaly Detection )
داده هایی که بیشترین مغایرت با داده های دیگر را دارد شناسایی کنیم
خلاصه درس داده کاوی – دکتر محمدپور – ۹۲/۰۸/۲۷
برای پیدا کردن Association Role
Apriori : پیچیدگی محاسباتی را تا حد قابل قبولی کاهش دهد
دومین الگوریتم علاوه بر عدم پیچیدگی ذخیره سازی روی هارد کمتر انجام شود
Rapid miner : پروسسور ها بصورت موازی استفاده می کند
نرم افزار هایی که در داده کاوی استفاده می شوند معمولا قابلیت استفاده از چند
پروسسور یا استفاده از GPU را دارد

دو مرحله دارد :
۱- تمام itemset هایی که تکراری هستند پیدا می کند
۲- از itemset ها برای ساخت Rule ها استفاده می کند
تعریف frequent itemset : ساپورت آن از یک minimum support بیشتر باشد

F1 شامل تمام itemset های با اندازه ۱ هست
F2 یکی از اعضاشون frequent بوده را شامل می شود
مثال :
یا روی تعداد کار می کنیم یا روی احتمال ( فراوانی یا مینیمم ساپورت )
min support= x /n
ابتدا تمام itemset های تکی را با تعداد تکرارشان می نویسیم
چون ۴ فقط یک بار تکرار شده در قدم بعدی اصلا ترکیب با itemset 4 را نمی آوریم
در مرحله بعد itemset های دو تایی
تمام itemset هایی که فقط یک بار تکرار شده اند در مرحله بعد محاسبه نمی آوریم
در صورت دلخواه الگوریتم Apriori را پیاده سازی کنید
Candidate Generator
هرس , join می کنیم
بعد از الگوریتم Apriori بین Frequent itemset ها Association rule ها را بدست می آوریم
برای مجموعه حساب نمیشه چون شرطی است
در مورد confidence فقط برای assotioation Rule ها استفاده می کنیم
تمام زیر مجموعه ها = ۲ به توان n
صورت :
مخرج : تعداد کل ایتم ها
با الگوریتم Apriori یک مثال برای خودتان حل کنید
برای حل مسئله از مجموعه ۱ عضوی شروع می کنیم تا تعداد اعضا
فرض کنید که ۷ تا Transaction داریم
یکی گوشت و مرغ و شیر میگیرد
برای محاسبه confidence

[image1]
Frequent itemset
Association Rules
برای محاسبه Confidence به دو صورت می توانید محاسبه کنید
۱- احتمال صورت به احتمال مخرج
۲-تعداد x بخش بر مجموع کل

[image2]
اگر شیر نتیجه میداد جوجه و لباس
الگوریتمهای زیادی برای پیدا کردن قواعد پیوند داریم
برای ۷ تا پیوند تعداد زیادی Rule رسیدیم
بنابراین برای hypermarket های بزرگ با این روش منطقی نیست
استراتژی محاسبه قواعد متفاوت است
خیلی از نتایج هم تکراری هست
الگوریتم های مختلفی که ارائه شده اند با اینکه متفاوت هستند ولی باید به نتایج یکسانی برسند ولی با هزینه های پیاده سازی متفاوت هستند
که در اینجا Apiriori Algorithm استفاده شده است
Apiriori Algorithm دو مرحله دارد
۱- تمام itmeset هایی که به کار رفته استفاده می کند
۲- از frequent temset استفاده می کند برای تولید قواعد
Frequent Itemset باید از minimum support بیشتر باشد
مثل خوشه بندی که یکجا دندوگرام را می بریم
ایده اصلی این الگوریتم از خاصیت Apiori استفاده می کند که هر زیر مجموعه Frequent itemset خودش یک frequent itemset هست
اگر یک مجموعه ABD – Frequent باشد بنابراین زیر مجموعه هاش هم حتما Frequent هستند
مثلا در ABD مجموعه AC چون زیر مجموعه اش نیست می تواند Frequent نباشند
بنابراین غیر Frequent ها را جدا می کند و کار ما را سریع می کند
Frequent Item set باید از مینیمم support ی که ما تعیین کردیم بیشتر باشد
اگر بتوانید یک مثال کتاب را حل کنید ( Rule ها را بنویسید )
برای تجزیه تحلیل سری های زمانی
مثلا فوریه ترانسفورم یک ایزومتری هست
موجک (wavelet) هم همینطور است
اگر بتوانیم …
Spectural Density را رسم کنیم پیک را که نگاه کنیم سیکل را به ما نشان می دهد
در نرم افزار itsm به راحتی تست می کنیم
Seasonal Index
سری زمانی
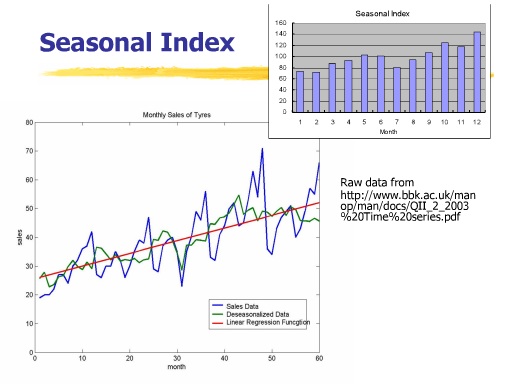
بر اساس این اطلاعات Cycle و Trend و Simlarity می توانیم در مورد Predection داده ها صحبت کنیم
در Time-Series Analysis با یک سری زمانی سر و کار داریم
ولی در داده کاوی با چندین سری زمانی سرو کار داریم یا با یک سری زمانی طولانی
داده ها را هم توزیع می کند و هم نرمال
برای تشخیص نا ایستایی ها
اگر می خواهید فشرده سازی هم انجام دهید wavelet Transform بهتراست
تبدیل فوریه : اگر بخواهیم برای متغیر تصادفی پیوسته انجام دهیم
تقریبی برای حالت پیوسته است
Enhanced Similarity Search Methods
در ITMS2000
در سری های زمانی اول داده ها را می خوانیم و سپس Time plot را رسم می کنیم
باید موارد نا ایستایی را حذف کنیم
واریانس به زمان وابسته هست
پس لاندا را صفر در نظر می گیریم
با این کار امدیم ناایستایی در واریانس را حذف کردیم
حالا سری که این سه مولفه را ازش حذف می کنیم
و سپس
سری باید بدون trend , seasonality , … , ….. باشد


مدل زمانی ایستا
ARMA
ARAR
Auto regresive
میانگین متحرک
مدل برازش بدهیم Autofit را انتخاب می کنیم
با استفاده از روش AIC می توان بهترین مدل را انتخاب کرد
بهترین مدل ان است که AIC آن کمتر باشد
ARMA forecast
برای امتحان
کتاب Tan مرجع هست
خلاصه درس تدریس یار خوشه بندی – مهندس حائری ۹۲/۰۸/۱۲
درخت تصمصم گیری
یک روشی هست که بر اساس قوانین .. ایجاد میشه
درخت تصمصم گیری تارگت شان متغیر های کمی هست
متغیر خروجی اگر کیفی باشد ، درخت رده بندی گفته می شود
می توانیم درخت های متعددی بکشیم
در C5 ممکن است چندین روش وجود داشته باشد ولی بهترینش را نشان می دهد ولی در درخت تصمیم همه درخت ها را نمایش می دهد
از معایبش اینکه اگر تعداد متغیر ها زیاد باشد در صفحه مونیتور نمی توان دید
درخت تصمیم کاربرد های زیادی دارد
برای اینکه الگوریتم C5 را فرا بخوانیم لازم بود type را بدانیم و آن چیز هایی که لازم نیست را حذف کنیم
ReadValue را می زدیم تا اطلاعات را بخواند
الگوریتم C5 ویژه متغیر های کیفی بود
این الگوریتم خیلی تحت تاثیر مشاهدات بی پاسخ قرار نمی گیرید
Target کیفی است ولی input هم می تواند کیفی باشد هم کمی
هر چقدر تعداد use Boosting ها مون کمتر باشد پیچیدگی کمتری خواهیم داشت
اگر از گزینه Expert استفاده می کردیم
گزینه Window Attributes قبل از اینکه C5 شروع بع کار کند متغیر هایی که در رشد درخت نقض سازنده ای نداشته باشد در مدل بندی استفاده نخواهد کرد
Costs :
use misclassification costs
اگر دیتایی بخواهد بد رده بندی شود جریمه ای در نظر گرفته شود یا خیر
در گزینه Analyze
Calculate predictor impotance : اهمیت هر کدام از متغیر های مسقل ورودی را برای ورود به ساخت درخت
خلاصه درس تدریس یار داده کاوی ۹۲/۰۸/۰۵
K-means
Unomary Detection
تحلیل خوشه ای نیاز به هیچ پیش شرط آماری نیست
یک متغیر Target یا هدف باید داشته باشیم
که یا از قبل مشخص می کنیم به عنوان Target
یا به جای اینکه از use type node setting استفاده کنیم از use
custom setting استفاده می کنیم
یکی از این الگوریتم ها الگوریتم C5 هست
الگوریتم C5 اولا برای متغیر های کیفی ( چه به فرم اسمی باشد یا
به فرم ترتیبی )
ملاک برای خوشه بندی چه متغیر هایی می تواند باشد ؟
باید مجموعه ای از متغیر های ( کمی و یا کیفی ) در دسته بندی
متغیر ها مورد استفاده قرار بگیرد
متغیر های ورودی Input را باید وارد کنیم
در نسخه IBM modeler 14 یک گزینه اضافه شده : Use Weight Field
(مثلا به تفکیک سال )
Build model each split
اگر مدلی را به عنوان تقسیم کننده انتخاب کرده باشیم ، برای هر
بخش تقسیم شده کدش را نمایش می دهد
مدل می تواند Simple ساده باشد یا Expert حرفه ای
درخت تصمیم بایستی با کمترین شاخه بتواند ما را با نتیجه برساند
در تمرین قبل الگوریتم C5 را اجرا کنید و بفرستید
خلاصه جلسه داده کاوی – دکتر محمد پور ۹۲/۰۷/۲۹
GMM – Gaussian Mixture Model
چهار روش بر آوردی پارامتر های یک مدل آمیخته گاوسی
در آمار مفهوم مستقل و هم توزیع داریم
۲- مدل آمیخته گاوسی :
برای نشاهدات مستقل و هم توزیع x1,…,xn ، مجموع وزن دار K مولفه ، با تابع چگالی گاوسی است که با معادله زیر نشان میدهیم :
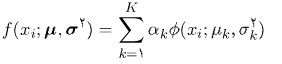
۳- برآورد پارامتر های مدل آمیخته گاوسی به روش تحلیلی
* مهم : باید داده ها را شبیه سازی کنیم
کلاسترینگ سالانه کنفرانس دارد ، ۸۰ مجله به چاپ مقالات کلاسترینگ می پردازند
۳-۱ روش گشتاوری
می خواهیم از دو جامعه نرمال آمیخته …
مثال قد و وزن دختر ها و پسر ها خوشه بندی کنیم
به چهار روش این مساله را بررسی می کنیم ( برای دو متغیره )
۱- روش دقیق
۲- روش ریاضی
۳- EM روش آماری
۴- Gip Sampling – شبیه سازی
آیا این مساله به روش تحلیل قابل حل است ؟
با روش تحلیل فوق العاده پیچیده می شود ( گشتاور مرکزی )
در آخر صفحه کد های تولید GMM آورده شده است با نرم افزار R

۳-۲ ماکسیمم درستنمایی
با این روش می توانیم پارامتر ها را دقیق تر بر آورد کنیم
تابع چگالی را به عنوان یک پارامتر ببینیم
پیدا کردن maximum Likelyhood

در حالت چند متغیره :
در حالت ۵ متغیره با روش تحلیلی بسیار پیچیده می شود.
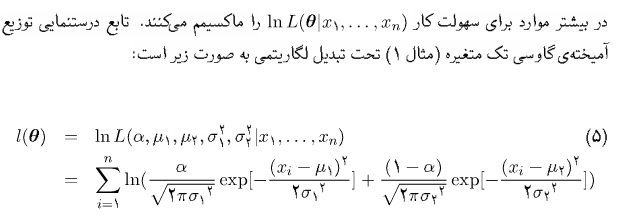
کد بر آورد پارامتر های GMM با روش عددی
اگر بخواهیم ماکزیمم تابع را پیدا کنیم با استفاده از دستور optim می توانیم انجام
دهیم
۳-۲-۲ برآورد پارامتر های GMM با الگوریتم EM
الگوریتم EM
روش Gipsampling
قبلا به روش های آمار کلاسیک حل می کردیم
ولی با این روش در چارچوب آمار بیز حل کنیم
یعنی یک اطلاعات پیشین هم باید داشته باشیم
توزیع پیشین مزدوج : (یک مساله استاندارد است )
تمرین برای جلسه بعد : تولید عدد تصادفی از GMM چند متغیره در متلب انجام
بدهید – مثل مقاله –
چگونه با استفاده از متلب با GMM اعداد تصادفی تولید می کنید ؟
جواب را به Email statdatamining بفرستید
خلاصه درس تدریس یار داده کاوی – ۹۲/۰۷/۲۸
spss 14 modeler
File – Open – Demo
Source – Node Statistic files – Demos –
از لیست فایل ها فایل telco را انتخاب می کنیم
این فایل شامل ۴۲ ستون و ۱۰ ردیف هست
این فایل را برای مثال K میانگین و ۲ Step Cluster باز می کنیم
از بین لیست متغیر هایی که داریم ، چند فیلد را وارد کرده ایم
در این کار هدف این است که از ۴۲ متغیر با استفاده از این ۵ متغیر کار خوشه بندی داده ها را انجام بدهیم
۱۰ تا مشاهده داریم
به چند روش می توانیم این داده ها را خوشه بندی کنیم
قسمت Field – User Custom Setting را می زنیم
در کرکره Model اتوماتیک هست و یا نام دلخواهی را انتخاب کنیم
اگر از داده های بخش بندی شده استفاده کنیم
ما در سیستم K میانگین محدودیتی داریم که باید بدانیم به چند خوشه می خواهیم تقسیم بندی کنیم
به صورت پیش فرض ۵ خوشه داریم
آیا می خواهیم ستون مربوط به فاصله ها را
در کرکره بعدی Expert : آیا اطلاعاتی که داریم می خواهیم یک خوشه بندی ساده باشد یا اطلاعات کاملتری را هم بدهد.
اگر اجرا کنیم این شکل دیده می شود
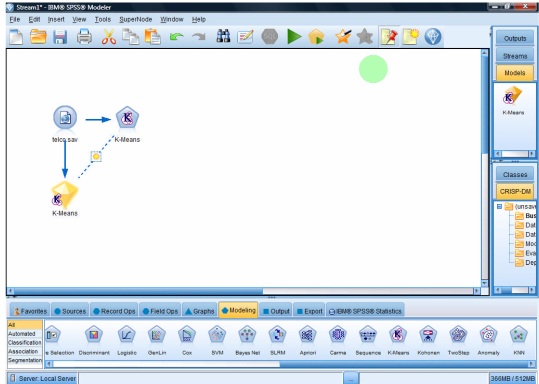
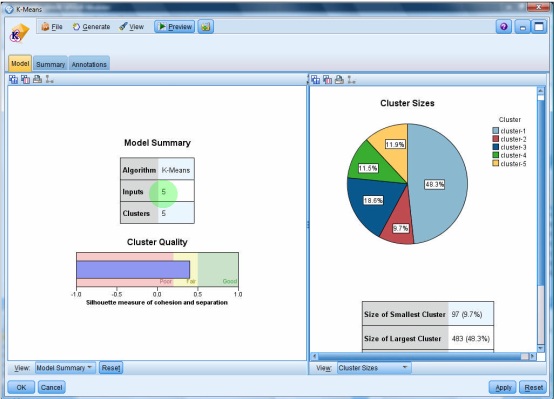
۵ تا خوشه ای که انتخاب کرده ایم
اگر تعداد خوشه های کمتری را انتخاب می کردیم ممکن بود مقدار سایه نما Siloet بهتری را داشتیم
در View گزینه cluster داریم
که می گوید چه ویژگی هایی وارد شده
در ردیف size درصد خوشه ها را نمایش می دهد
در پایین منو نمونه ها و جدول های دیگری را نمایش می دهد
Show Basic : درجه اهمیت و تعداد متغیر های موثر در خوشه بندی اعلام می کند.
متغیر های پیشگو : Predictor importance
Summary : خلاصه اطلاعات را می دهد
می توانیم چند بار از K-means استفاده کنیم
یک روشی دیگر داریم به نام ۲ Step Cluster
باید نرمال چند متغیره باشد
در k-means برای متغیر های کمی هست
و نمی توانیم از متغیر های کیفی استفاده کنیم
در سیستم ۲Step Clustering
امکان محاسبه فاصله برای متغیر های کیفی هم بوجود امده است .
قبلا خوانیم که باید داده ها نرمال چند متغیره باشد
Node 2 Step Cluster را اضافه کردم
با کلید f2 اتصال را برقرار کردم
DblClick که می کنیم روی ۲ step cluster
مشابه متغیر هایی که برای k-means انتخاب کرده بودیم اینجا هم انتخاب می کنیم
در تب Model گزینه ای برای عددی کردن داده ها وجود دارد
exclude outlier : مشاهدات پرت را از تحلیل حذف می کند
به صورت پیش فرض اگر بیش از ۳ داده پرت باشد از دور خارج می کند
برای نفر دوم ، سن نفر دوم را منهای انحراف میانگین نفرات می کند
بهینه تعداد خوشه ها می تواند تشخیص دهد
یا اینکه امکان این هست که تعداد کلاستر را اجبار کنیم
Distance Major : حداکثر درست نمایی : فاصله اقلیدسی هم داریم
معیار خوشه بندی بر اساس معیار بیضی شوارتز BIC یا AIC باشد
خلاصه درس داده کاوی ۹۲/۰۷/۲۲ – دکتر محمد پور
صفحه ۱۸/۲۱
OLAP Operations : Data Cube
جدول ها را نرم افزار می کشد ، لازم نیست
اگر بعضی وقت ها داده ها دو بعدی باشد ، هیستوگرام را سه بعدی می کشیم
hist2D فراوانی داده ها را به صورت دو بعدی محاسبه میکند
OLAP را رسم کنید
خلاصه شده داده ها را نشان میدهد
با استفاده از خلاصه سازی رابطه بین متغیر ها را می توانیم مشخص کنیم
مثلا برای جدول ۷ بعدی ۲۴۰۰۰ مدل داریم
clustering یک روش unsupervised هست که هدفش قرار دادن داده های همگون در خوشه هست
اگر داده های یک بعدی باشد همان متر معمولی را در نظر می گیریم
ولی اگر داده ها بیش از یک بعد داشت ( p بعدی )
مولفه ها را با هم مقایسه می کنیم
نرم اقلیدسی
با یک تبدیل می توانیم بردار را به ماتریس تبدیل کنیم
در روش سلسله مراتبی ما اطلاع نداریم که چند تا خوشه داریم
با روش جمع شونده
هر یک از داده ها را یک خوشه می گیریم
و در هر مرحله یک خوشه کم می شود
برای همین محاسبات خیلی سنگین می شود
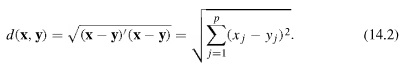
فاصله یک نقطه از مجموعه : چند روش مختلف داریم
۱- فاصله نقطه تا مینیمم مجموعه Single Linkage ( Nearest Neighbor )
مثال جرم و جنایت در شهر های آمریکا
رسم دندوگرام
۲- روش Complete Linkage
در مرحله بعدی جدولی که بدست می آوریم مشابه جدول روش اول است
۳- Average Linkage
میانگین فاصله
۴- روش Centroid
چون روش agerage محاسبات سنگینی دارد در Centroid به جای فاصه میانگین ها ، از میانگین فاصله ها استفاده می کنیم
۵- روش median میانگین وزنی است
۶- روش ward

تمرین : برای هفته آینده

جدول جرم و جنایت در آمریکا
با سه روش
single linkage
Complete Linkage
Average Linkage
به ایمیل بفرستید
statdatamining@gmail.com
۹۲/۰۷/۲۱ تدریس یار داده کاوی
ما می خواهیم که ۴ سری دیتا به عنوان تمرین وارد کنید و ارسال کنید
فایل cars
در sample های spss معمولی اگر باز کرده باشید می توانید باز کنید و استفاده کنید در folder sample هست
بعد از اینکه node statistic را لود کردیم
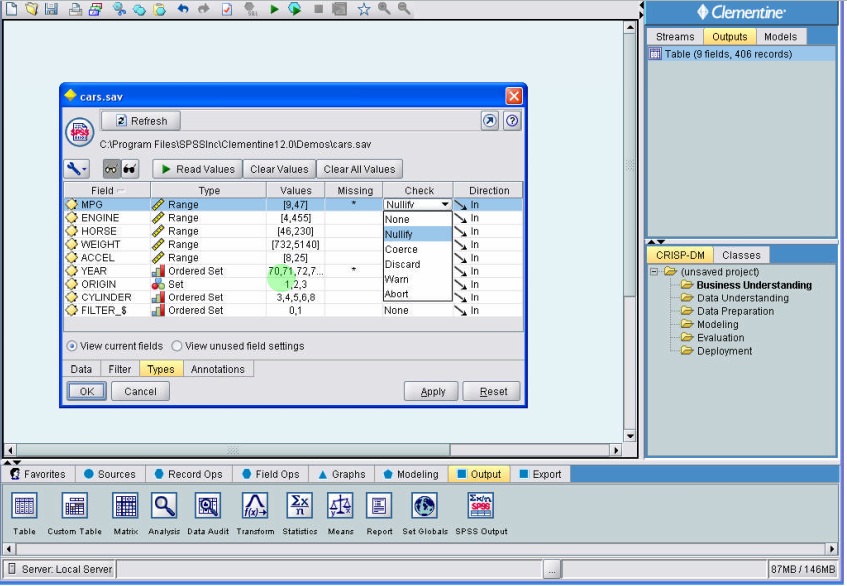
در ستون value متغیر ها لود می شود
ممکن است در متغیر ها بی پاسخی داشته باشیم
مثلا در متغیر MPG اطلاعاتش نباشد
وقتی روی missing کلیک می کنیم می توانیم آنرا خاموش یا روشن کنیم
یعنی بی پاسخی را برای آن تعریف کنیم
در سیستم این امکان وجود دارد که با بی پاسخی هر جا اطلاعات داشته باشد استفاده کند و رهر جایی که missing باشد آنرا رها میکند
برای کنترل داده های معتبر می توانیم در missing specify را انتخاب کرده و در ستون check محدوده اعداد و یا شرطی را انتخاب کنیم و جایگذاری کنیم
نحوه برخورد با بی پاسخی را تنظیم می کنیم
گزینه Coerce : وقتی به محدوده بی پاسخی میرسد , متغیر کمی است میانگین داده ها در نظر می گیرید
اگر داده ها به صورت عددی باشد و مثلا ۰ را به عنوان بی پاسخ داده باشیم نزدیکترین عدد را جایگذاری می کند
اگر در Type Set بگذاریم در داده ها عدد هم باشد ، اعداد با کوچکترین عددی که سیستم می شناسد جایگذاری می کند.
در مورد جنسیت True / False بی پاسخ باشد به صورت کد کوچکترین را قرار می دهد ( false خواهد بود )
داده ها می تواند بدون نقش باشد ( مثل شماره دانشجویی ) محاسباتی نیست
برای اینکه بدانیم که داده ها به طور صحیح وارد شده Table آنرا ایجاد میکنیم
روی مبدا کلیک , F2 و سپس روی مقصد کلیک می کنیم
سیستم که می خواهد مدلی را Run کند
در قسمت expert هم نوع خروجی که سیستم میدهد مشخص می شود
اگر expert را انتخاب کنیم شرط توقف را هم در داده ها خواهیم داشت
نمودار siloet
هر چه مقدارش به ۱ نزدیک تر باشد نشان دهنده مناسب بودن خوشه هاست
۹۲/۰۷/۰۱
داده کاوی
دکتر محمد پور
مجموعه شمارا – گسسته
صفت های پیوسته :
مثل وزن ، قد
– در خصوصیت داده ها به سه مساله باید اشاره کنیم
۱- تعدد بعد داده ها Dimensionality
۲- پراکندگی داده ها Sparsity
۳- دقت Reslution
کیفیت داده ها خیلی مهم است
Unomarly Detection
missing Value
missing At Random (میانگین داده را جایگزین کنیم – بد ترین را ه ممکن هست – یا اینکه داده را حذف کنیم )
بهترین روش از روش EM -Algorithm باید استفاده کرد
(—————————–
کتاب روش شناسی آماری ( دکتر صالحی )
ترجمه پژوهشکده آمار
۱- خطاهای نمونه گیری
۲- خطاهای غیر نمونه گیری
شناسایی خواندن فرمها با روش ICR
Intelligent Charachter Recognition
نسل قدیمی آن OCR بود
————————)
Duplicate Data
به علت خرابی صدا کلاس ناتمام ماند

{kind=link}