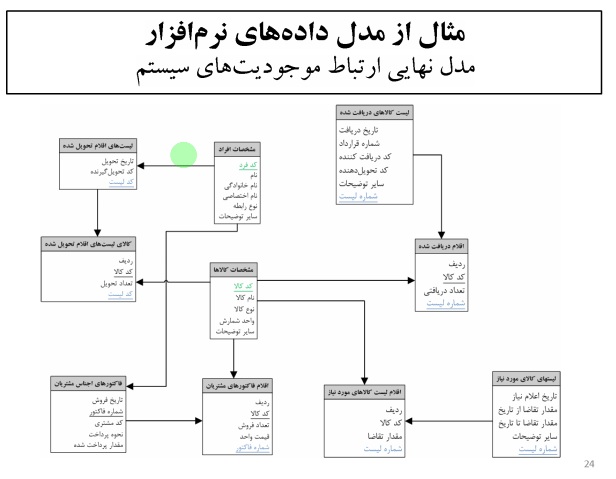
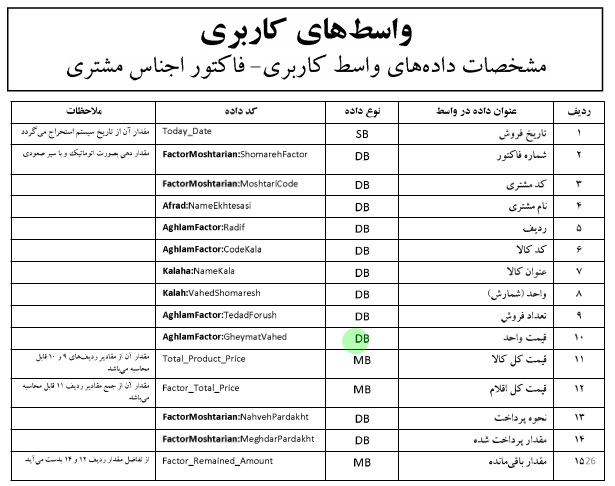
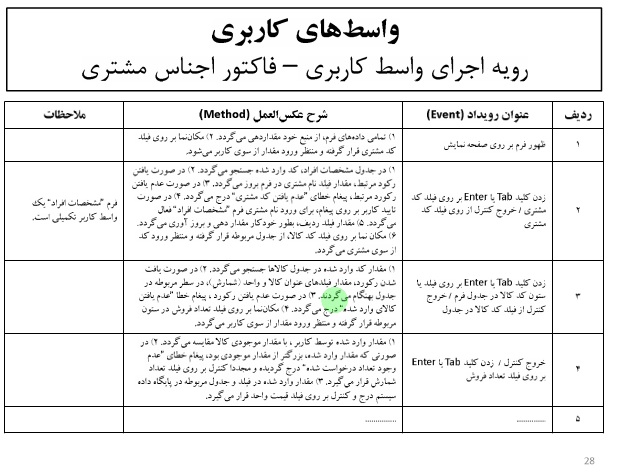
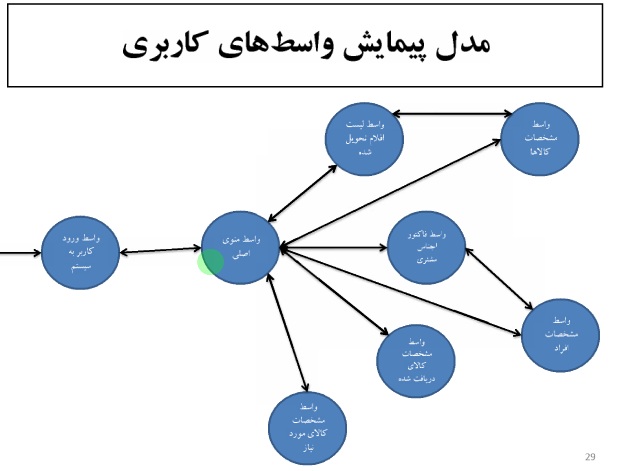
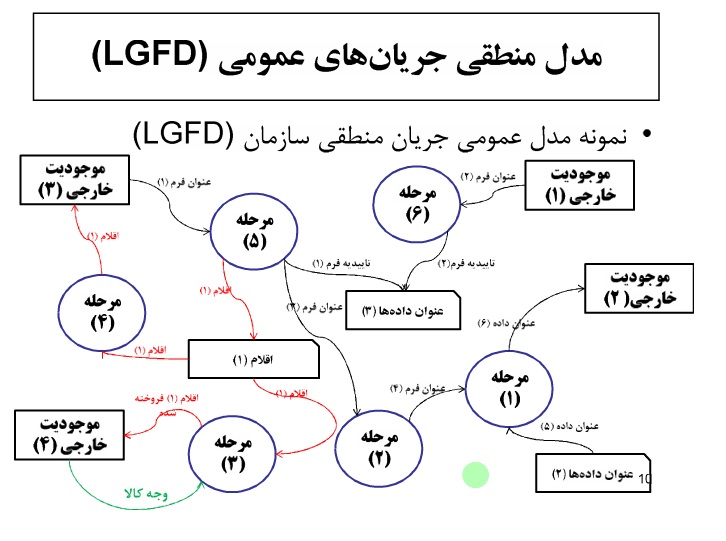
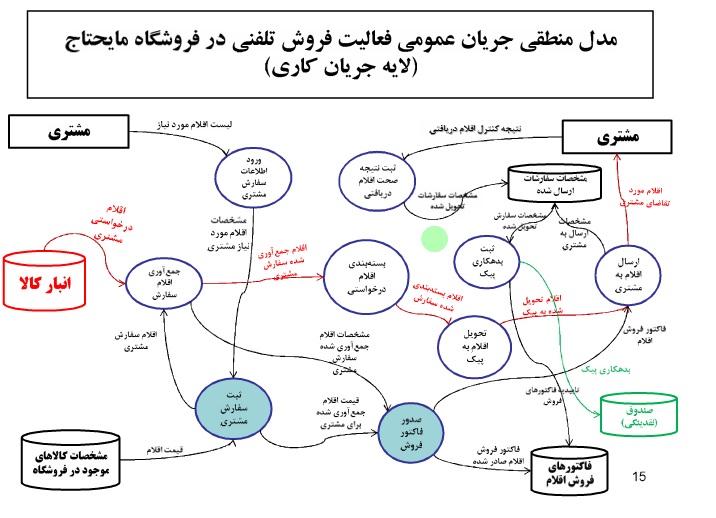
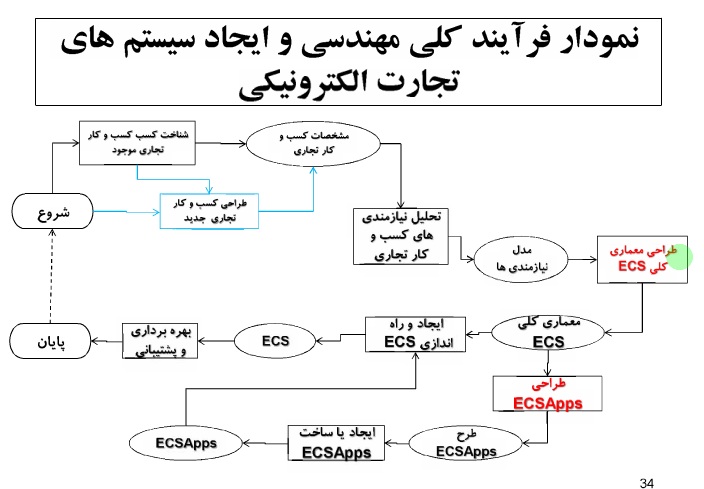
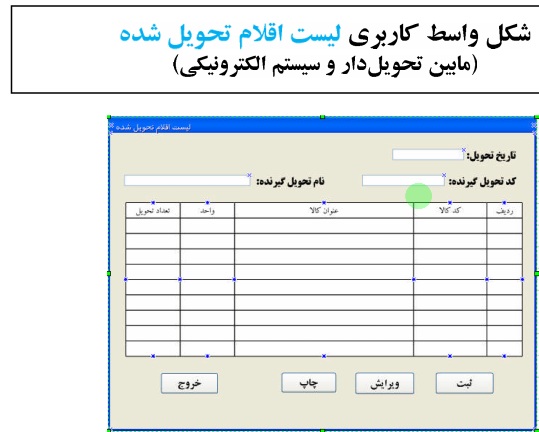
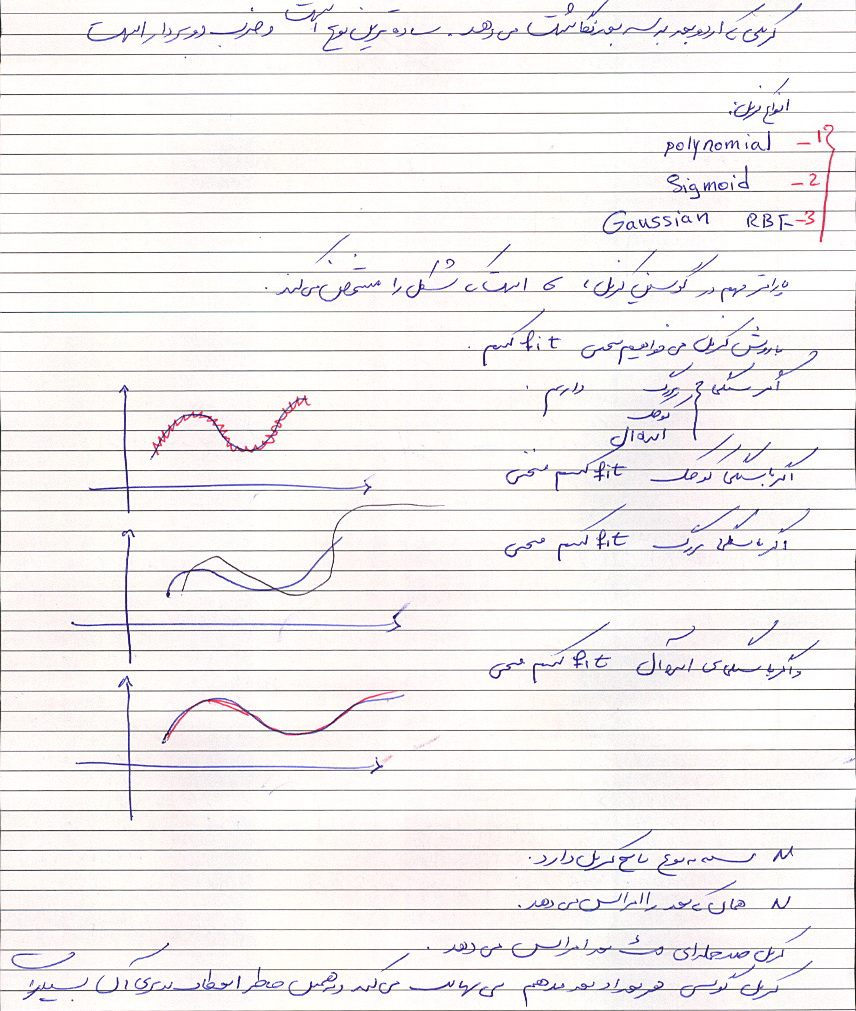
خلاصه درس داده کاوی – دکتر محمد پور – ۹۲/۰۹/۱۸
برنامه ارائه مقالات کنفرانس داده کاوی در لینک ذیل قرار دارد:
http://dl.irandatamining.com/users/uploads/BarnamehConference.pdf
امروز در مورد محک های ارزیابی تجربی صحبت می کنیم
سه روش مشهور داریم
که معروفترینشان Cross validation هست
اگر از روش هایی استفاده می کنیم فقط دستورش را ببینیم در clementine هر کدام یک مدل با فرض های مختلفی هستند
و بهتر بودن هر کدام مشخص نیست
با اینکه همه خوشه بندی انجام میدهند ولی ممکن است در ارزیابی موفق نباشند
انتخاب مدل مناسب کار بسیار سختی است
در مرحله ارزیابی مدل را تست می کنیم
از داده ها استفاده می کنیم ببینیم چقدر می تواند پیشبینی را انجام دهد
اگر روشی جدید ابداع کردید باید صحت پیشبینی آن از بقیه روشهای بهتر باشد
قابل تعمیم بودن
قابل تفسیر بودن : روش ما باید قابل تفسیر باشد
سادگی
کیفیت نشانگر ها Domain-Dependent quality indicators
————
چطور خطا را حساب می کنیم
با تابع Loss Function
ساده ترین آنها Zero Loss Function است
امید Loss میشه Risk
در مساله خوشه بندی خیلی ساده تعداد ۱ ها بخش بر n می شود
در خوشه بندی وقتی می خواهیم Evaluate کنیم
Nc تعداد داده های درست کلاس بندی شده
Nt تعداد کل
درصد درست کلاس بندی شده هاست
e درصد اشتباه کلاس بندی شده هاست

C اپسیلون داد ها
هزینه برای داده های بد کلاس بندی شده ها
miss clasification Cost
اگر بخواهیم به صورت نظری
COLT typical research questions
با داده های مثال از پیش تست شده روش جدید را می توانیم تست کنیم
چرا ؟ چون باید در بدترین شرایط تست شود
Emprical evaluation
سعی و آزمون
مثلا به تصادف چند داده را انتخاب کنیم
Resampling : ( باز نمونه گیری ) چند بار به صورت تصادفی انتخاب میکنیم میانگین آنها را محاسبه می کنیم
BootStrap : Resampling با جایگذاری است
Hold out برای داده های بزرگ کاربرد دارند
k-fold Cross Validation :
خیلی ها اتفاق نظر دارند که این روش خیلی بهتری است
در این روش جای داده های train و test عوض می شوند
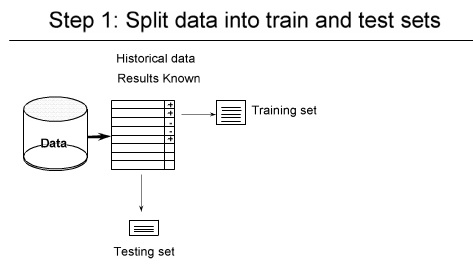
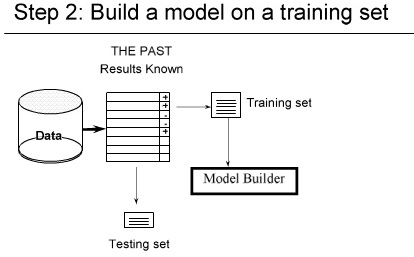
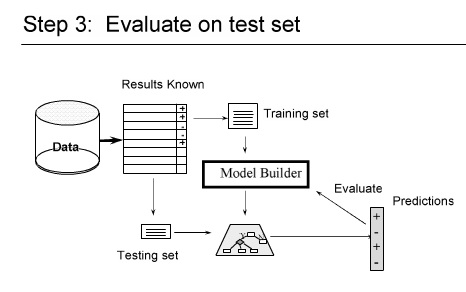
۱- شکستن داده ها ( به صورت تصادفی ) مثلا یک سوم test دو سوم tranining
۲-
۳- داده هایی را که برای تست در نظر گرفتیم خطا ها را حساب می کنیم
——————————–
در Hold-out ما overlapping داریم
ولی در Cross-validation بحث overlapping را نداریم
اگر بخواهیم دو الگوریتم را با هم مقایسه کنیم
از روش های آماری می توانیم استفاده کنیم