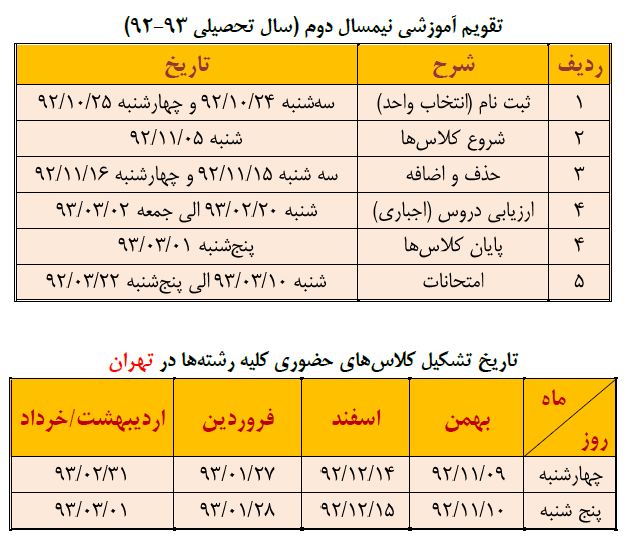
Jan 132014

با سلام
لطفا در مورد فایلهای همراه این ایمیل در سایت باشگاه مجازی دانشگاه امیرکبیر اطلاعرسانی شود.
البته این فایلها در روی سایت درس نیز قرار خواهد گرفت.
در مورد درخواست برخی از دوستان در مورد سری نهایی تمرینها، تمرین همان تمرین قبلی است،
و دوستان بایستی تنها دو صفحه گزارش بر اساس دستورالعملی که توسط آقای دکتر برادران تهیه شده است،
انجام دهند.
clustering project instructions
—
Hadi Zare, Ph.D
Assistant Professor,
Faculty of New Sciences and Technologies,
University of Tehran, Iran



سوال اساسی : نسبت ATMS و ATIS
در ATMS : مدیریت تقاطع ها
در ATIS مدیریت اطلاع رسانی کاربران ، خبرگان
معماری ارتباط بین ATMS و ATIS را می تواند برقرار کند
معماری سراسری و معماری منطقه ای داریم
در مبحث استاندارد سازی به چند نکته اشاره می کنیم
۱- در حوزه مفاهیم : در سطح ملی بایستی استاندارد سازی مفاهیم شود
۲- استاندارد سازی در حووزه سخت افزار ها
۳- استاندارد سازی نرم افزاری
استاندار های بازار یابی
استاندارد ها به صورت قوانین می توانند تبدیل شوند
سازمان استاندارد در حوزه های IT و ITS استاندارد های خوبی داریم
TC 204 در ISO به ITS اختصاص دارد – ولی در ایران نداریم
جا دارد که در حوزه های خدمات ITS این استاندارد ها را تکمیل کنیم
TC204 مرجع اساسی جمع بندی سیستم های ITS هست
روی اقلام مختلف ITS استاندارد های مختلفی را داریم
۱۳۷ مورد موسسه ایزو استاندارد های مختلف در حوزه ITS قرار داده است
تمرین : ( مهلت تا ۶ دی )
فرم های آپلود شده در LMS
پرسشنامه – مصاحبه برای نیازمندی ها
با آگاهی از کاربر
معماری اصل است
معماری به ما کمک می کند خطا به حداقل برسد ، ریسک پایین بیاد
الگوی های استاندارد از پیش تعیین شده پیش برویم
ارتباط برقرار کردن بین سیستم ها برسیم
در یکی از بحث های مهم استاندارد های تدوین معماری هست
برای تدوین استاندارد های معماری بر اساس استاندارد مناسب با توجه به جنبه های
موثر در معماری
کتاب هم به چاپ رسیده توسط موسسه توسعه معماری
تاکید مضاعف بر توسعه معماری : حوزه های مختلف را باید بتوانیم پوشش بدهیم
شروع کار از سطوح مطالعاتی است
تاکید بر فرایند بازگشت پذیر بودن
زیر ساخت های
در قالب Teamwork ها در بخش های صاحب نفوذ
پیدا کردن راه حل های مشترک
policy نویسی
Strategic plan on ITS
در کلیه بخش های ITS نیازمند اول Policy های مربوط به بخش را پیدا کنند و سپس
تعریف کار در حوزه انجام شود
برای پشتیبانی از Policy چه خدماتی باید ارائه شود
بر روی آن سرویس های کاربر را بتواند پوشش دهد
در حوزه آینده پژوهی باید بسیار کار شود
ITS effisient
Green ITS
Feature ITS
امتحان :
۱- خدمات ITS (زیر سیستم ها – )
۲- الگوریتم ( تخصیص ترافیک – شمارش مسیر ها – الگوریتم لاگرانژ – مطابقت دو طرفه ) در حد مباحث اسلاید ها
خلاصه جلسه جبرانی خوشه بندی ساعت ۵ تا ۶:۳۰ دکتر زارع ۹۲/۰۹/۲۵
Classification
فیشر :
با استفاده از توزیع گوسی روش فیشر را بدست آورد در بحث Pattern Recognition
داده ها را به دو دسته train و test تقسیم می کنیم
اگر بتوانیم یک جدا ساز ساده تعیین کنیم برای داده های تست عملکرد خوبی داشته باشیم
nearest Neighbor در صورت اضافه شدن داده جدید ،
یک پیش پردازش برای کاهش بعد انجام می دهیم
و معمولا از Feature Selection برای بیرون انداختن داده های نامربوط استفاده می کنیم
برای تشخیص پارامتر های موثر
از یکی از این سه روش می توانیم استفاده کنیم
-Forward Selection
– Backward Elimination
– Bi-Directional search
در بحث Distanse های مختلفی می توانیم استفاده کنیم ( اقلیدسی – منهتن – ماهالونوبیس )
دو تا اسم داریم Peter , Piotr
از اسم اول با ۳ عملگر می توانیم به اسم دوم برسیم
————————————
فایلهای زیر آپلود شد
Clustering Final exam
sharifi test
intro_SVM_new
classification – part 4
———————————-
———————————-
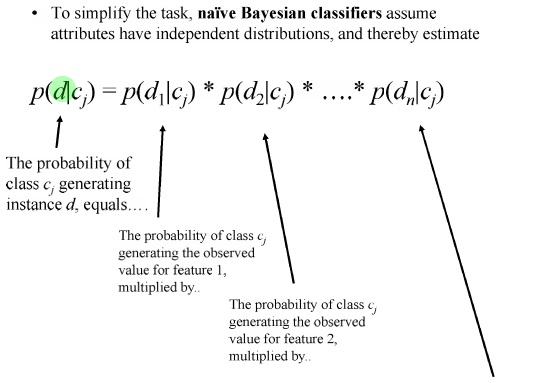
Naive Bayes رو معمولا بر اساس گراف می کشند
نایو بیز نسبت به Future های نامربوط حساس نیست
چون در واقع ویژگی ها از هم مستقلند اثر یک ویژگی از بین می رود
آیا می شود روش Naive Bayes را بهتر کرد ؟ بله
مزایا و معایب روش Naive Bayes:
————————————–
در امتحان نمی آید
SVM : Support Vector Machine
ماشین بردار پشتیبان
آقای vladimir vapnik مطرح کرد ۱۹۸۰
Statistical Learning Theory
Dataset – MNIC
error rate بسیار کمی داشت
اولین بار روش Kernel را با SVM مطرح کردند
اگر دو کلاس داشته باشیم و بتوانیم با یک خط جدا کنیم پس بی نهایت خط دیگر می توانیم رسم کنیم
بهترین خط را کدام در نظر بگیریم
دو خط مرزی را در نظر می گیریم و مرز تصمیم گیری را در میانگین این دو خط مرزی در نظر می گیریم
Margin را باید Maximize کنیم
KKT Conditions
سر امتحان
ماشین حساب بیارید
دندوگرام باید بکشید
K-means
GMM
PCA
Fisher
روشهای classification
Naive Bayes و K-nearest Neighbor را باید بلد باشد
h.zare@ut.ac.ir
مقاله ها را به این ایمیل بفرستید
تا ۱۵ بهمن تاریخ نحویل پروژه هست
نمونه سوال سال تحصیلی ۹۰ – ۹۱
دانشگاه صنعتی امیرکبیر
دانشکده مهندسی کامپیوتر و فناوری اطلاعات
امتحان درس مهندسی و ساخت سیستمهای تجارت الکترونیک
بخش الف) یک مرکز داده قصد دارد تا به مشتریان خود, سرویس دهنده مجازی (Virtual Private Server-VPS) عرضه نماید. در این نوع از خدمات زیرساخت, به کمک تکنولوژی های نرم افزاری از مجموعه مشخصی از امکانات و تجهیزات حقیقی شامل سرویس دهنده حقیقی (حاوی حافظه جانبی, حافظه اصلی, پردازش گر و …) , عرض باند اینترنتی و سایر موارد، سرویس دهنده های مجازی متعدد و با ظرفیت های مختلف و قابل تعریف مبتنی بر خصوصیات نیاز متقاضی, ایجاد و با استفاده از ابزار مدیریتی مستقل در اختیار او قرارداده می شود. مشتریان می توانند از میان پیکره بندی های تعیین شده قبلی, سرویس دهنده مورد نیاز خود را انتخاب نموده و یا ایجاد سرویس دهنده ای را مبتنی بر نیاز خاص خود درخواست نمایند.
۱) با فرض وجود حداقل نقش های خریدار، فروشنده، بانک به عنوان مرجع پرداخت الکترونیکی، ثبت احوال به عنوان مرجع احراز هویت افراد حقیقی، سیستم تجارت الکترونیکی و موسسه اعتبارسنجی مشتریان، فرآیند هر یک از فعالیت فروش الکترونیکی VPS از پیش آماده و فروش الکترونیکی VPS اختصاصی، را طراحی نمایید.
۲) به غیر از فعالیت های ذکر شده در بند قبل، دو فعالیت تجاری و دوفعالیت غیرتجاری دیگر را که مکمل یا مرتبط فعالیت های بند قبل باشند، فقط نام برده و نوع آنها را بلحاظ موضوعی مشخص نمایید.
بخش ب) در شکل (۱)، جریان های کاری مربوط به فعالیت های یک زنجیره تامین کامپیوتر به صورت سفارشی برای مشتریان آورده شده است. با فرض آن که خریدار یا مشتری عنصری خارج از زنجیره تلقی گردد، مطلوبست:
۱) مدل های PGFD سطوح فرآیند و کل زنجیره تامین
۲) طراحی مجدد جریان های گردش کار برای فعالیت های زنجیره با فرض آن که هر یک اعضای زنجیره (فروشنده، توزیع کننده و تامین کننده) دارای یک سامانه تجارت الکترونیکی مجزا و مستقل باشند.
۳) طراحی نمودارهای LGFD سطح گردش کار الکترونیکی و PGFD سطح صفر مربوط به سیستم تجارت الکترونیک هر یک از سامانه های تجارت الکترونیکی زنجیره
۴) با توجه به فهرست جریان های ورودی و خروجی بدست آمده در سئوال قبلی، نمودار پیمایش واسط های کاربر برای هر یک از نرم افزار سیستم تجارت الکترونیک زنجیره مورد نظر را طراحی نمائید.(توجه: در صورت نیاز می توانید به مجموعه عناوین حاصل، موارد دیگری را حسب نیاز و جهت تکمیل نمودار پیمایش اضافه نمائید.)
بخش (ج): با توجه مراحل آورده شده در فرآیندهای کاری الکترونیکی شده مربوط به بخش قبل و سمینارهای ارائه شده در کلاس مشخص نمایید که در انجام یا الکترونیکی نمودن کدامیک از مراحل آورده شده در جریان های کاری, می توان از ایده ها، مدل ها و مطالب ارائه شده در مقالات سمینارهای کلاسی, بهره گرفت؟ ذکر کاربرد دو مورد از مقالات ارائه شده در سمینارهای کلاسی کافی است. (برای هر یک حداکثر در چهار سطر)
(موفق باشید)
—-
نمونه سوال سال تحصیلی ۸۹- ۹۰
دانشگاه صنعتی امیرکبیر
دانشکده مهندسی کامپیوتر و فناوری اطلاعات
امتحان درس مهندسی و ساخت سیستمهای تجارت الکترونیک
بخش الف) مرکز تحقیقات پردازش های فوق سریع دانشگاه صنعتی امیرکبیر موفق شده تا با ایجاد یک ابر رایانه خوشه ای (Super Cluster) امکان عرضه خدمات پردازش فوق سریع به سایر سازمان ها ، دانشگاه ها و اشخاص حقیقی را فراهم آورد. همچنین این مرکز قادر است تا علاوه بر ارائه خدمات پردازش فوق سریع، بنابر سفارش سازمان های متقاضی برای آنها اقدام به تولید ابر رایانه نماید. این مرکز تصمیم گرفته تا برای ارائه این خدمات شرکتی با ماهیت تجاری را در مرکز رشد دانشگاه تاسیس نماید.
۱) فعالیت های تجاری ممکن و چهار فعالیت فرعی شرکت مورد نظر را مبتنی بر محصولات مشخص شده برای آن نام ببرید.
۲) با طراحی یک چارت سازمانی که اجزای آن بر مبنای وظیفه تعیین شده باشد، مدل جریان کار سازمانی جهت ارائه دو فعالیت تجاری عنوان شده در سئوال قبل را با فرض عدم وجود سیستم الکترونیکی مشخص و به صورت ماتریس گردش کار ترسیم نمائید.(در پشت صفحه)
۳) فرض وجود سیستم الکترونیکی در سئوال قبل، چه ابعادی از مدل جریان های کاری طراحی شده را تحت تاثیر قرار خواهد داد؟ آیا می توان به در مورد شرکت مذکور، به یک سازمان تمام الکترونیک(Virtual Organization) دست یافت؟
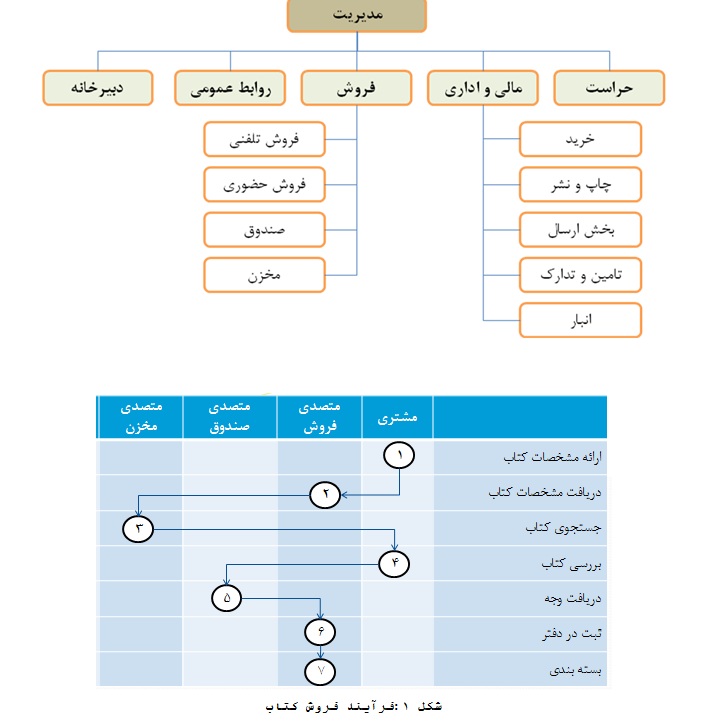
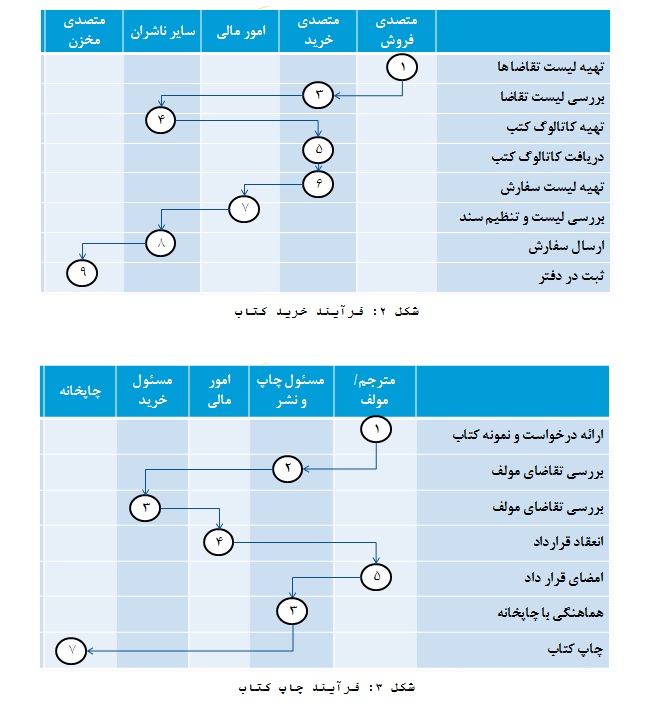
بخش ب) در بخش ضمیمه، جریان های کاری مربوط به سه فعالیت فروش، خرید و چاپ کتاب در یک بنگاه انتشاراتی آورده شده است. مطلوبست:
۴) تحلیل جریان های عمومی بنگاه مذکور در لایه فرآیندهای کاری PGFD-LGFD منظورشه
۵) تحلیل جریان های عمومی کل بنگاه در لایه زمینه (سطح صفر)
۶) طراحی مجدد جریان های گردش کار به منظور ایجاد سیستم تجارت الکترونیک
۷) تعیین نمودار جریان های عمومی سیستم تجارت الکترونیک سازمان در لایه زمینه (سطح صفر)
۸) با توجه به فهرست جریان های ورودی و خروجی بدست آمده در سئوال قبلی، نمودار پیمایش واسط های کاربر برای نرم افزار سیستم تجارت الکترونیک بنگاه مورد نظر را طراحی نمائید.(توجه: در صورت نیاز می توانید به مجموعه عناوین حاصل، موارد دیگری را حسب نیاز و جهت تکمیل نمودار پیمایش اضافه نمائید.)
بخش (ج): با توجه موارد ارائه شده در بخش قبل و سمینارهای ارائه شده در کلاس و همچنین جوابهای حاصل از پاسخ به سئوالات این بخش، به سئوالات زیر پاسخ دهید:
۱) مطالب و محتوای کدامیک از مقالات ارائه شده در سمینارهای کلاسی، در راستای ایجاد کدام بخش از سیستم تجارت الکترونیکی برای کتابفروشی قابل استفاده و بکارگیری است؟ کاربرد هر یک را در حد اختصار بیان نمایید.
۲) جزئیات نحوه استفاده از دو مورد از روشها و ایدههای مطرح شده در مقالات ارائه شده در سمینارهای کلاسی را به اختیار توضیح دهید. در این رابطه فرض کنید که سیستم تجارت الکترونیک کتابفروشی، به عنوان مثال عملی مقالههای انتخاب شده، در نظر گرفته می شوند.
(موفق باشید)
خیلی وقت ها در داده کاوی مجبوریم Data Alaysis انجام دهیم
فرق Data Analysis با Datamining این است که در تحلیل داده ها فرضیه ای را مطرح می کنیم و در مورد صحت و سقم آن نظر می دهیم
ولی در داده کاوی سوال هنوز مطرح نشده
می بینیم چه سوال میشه از دل این داده ها در آورد
یکی از تکنیک ها کمتر شنیدیم جداول توافقی یا جداول پیشایندی هستند
clementine قوی ترین نرم افزار در جداول پیشایندیContigency Table هست
برای جدول یک بعدی و دو بعدی یک مدل بیشتر برازش نمیشود
اساس جداول پیشاوندی DataAlanysis هست
چون به این سوال می خواهیم جواب دهیم که
داده ها را به دو قسمت تقسیم بندی می کنیم
(کمی – کیفی)
داده های کمی به دو دسته ( پیوسته – گسسته ) تقسیم بندی می کنیم
داده های ترتیبی هم می تواند باشد
فرض هایی که در مورد داده های کیفی هست :
۱-در مورد درصد نظر می دهیم (درصد اقایان بیشتر است یا خانم ها )
۲- یا در مورد استقلال ، مثل (سیگار به سرطان ربط دارد ؟ )
Z test
chi square
سرطان – سیگار – جنسیت )- تعداد مدل ها خیلی زیاد می شود
مثلا درصد آرای ۵ کاندیدایی که در انتخابات شرکت می کنند
خطای غیر نمونه گیری و خطای نمونه گیری داریم
فر می کنیم ازمایش Multinomial داریم که حالت توسعه یافته برنولی هست
آزمایش های مولتی نومیال مانند باینومیال مستقل از هم و درصد احتمال هم یکی است
( اگر از یک نفر بپرسند که به کدام یک از این ۳ نفر رای می دهی احتمال انتخاب با نفر بعدی که پرسش می شود یکی است )
آزمایش مولتی نومیال n نفر را به تصادف انتخاب می کنیم
هر یک نفر که انتخاب شده اند به یکی از این k کاندیدا رای می دهند
شرط اول : اگر نفراول احتمال انتخاب p بود نفر بعدی هم احتمال p باشد
شرط دوم : رای نفرات از هم مستقل باشد
N=100
k=3
p=1/3
در جدول پیشایندی نمایش می دهیم ( جدول توافقی )
سوال: ایا ارای این سه نفر یکی است ؟
درآمار شاید ۳۵ با ۴۵ برابر باشد چون ممکن است خطای نمونه گیری داشته باشیم
بنابراین باید آزمون انجام بدهیم
chi Square Test
به دنبال یک استراتژی منطقی برای Treshould که بتوانیم مقایسه کنیم
چون می شود ثابت کرد که این treshold
آمار آزمون همون استراتژی منطقیمون هست
آمار آزمون میاد تعداد مشاهدات را در مورد p1 انجام شده است n1 Observed Value منهای exepected Value
مقایسه را زمانی انجام می دهیم که فرض H0 درست باشد
استقلال را جدول دو بعدی می گوییم
با داده های کیفی در مورد استقلال صحبت می کنیم
در تست استقلال برای جداول دوبعدی مطرح می کنیم
مانند شرایط قبل آیا ارتباطی بین
فرض ها Mulinomial experient هست
فرض H0 آیا نوع خانه و مکان ساخته شده آیا با هم وابسته هستند و یا مستقلند
اگر وابسته نباشند درصد خانه ها چقدر است ؟
expected =حاصلضرب …. تقسیم بر تعداد کل
جدول توافقی دو بعدی
اگر قرار باشه مکان و نوع ربطی به هم نداشته باشند
۱۱۲/۱۶۰ تابع چکالی کناری Marginal
باید تابع چگالی توام مساوی
از نظر شهودی اگر آزمایش انجام دادیم که با آزمایش دیگری از نظر فیزیکی ربطی به هم نداشت از نظر ریاضی هم مستقل هستند
احتمال joint را چجوری حساب می کنیم ؟
احتمال ۶۳ مشیه حاصلضرب این دو احتمال
و وقتی می خواهیم Expected را انجام دهیم ….
در این جلسه در باره جدول توافقی وجدول chi square
صحبت شد
سه فصل امتحان می گیریم
– فصل ۱ و ۲ کتاب Tan به صورت تستی
– خوشه بندی از جزوه انگلیسی و به عنوان کمکی جزوه فارسی می توانید استفاده کنید
– Asociation Role ها
بارم نمرات : ۶ تا ۸ نمره پروژه و ۱۲ تا ۱۴ نمره امتحان دارد
الگوریتم SVM در Clementine
SVM معمولا برای داده های بزرگ به کار می رود
SVM – Support Vector Machine از خانواده یادگیری ماشین و هوش مصنوعی هست
معمولا زمانی از این روش استفاده می کنیم که حجم داده ها خیلی زیاد باشد
مثلا راجع به داده های پزشکی ، سلولهای سرطانی کاربرد دارد
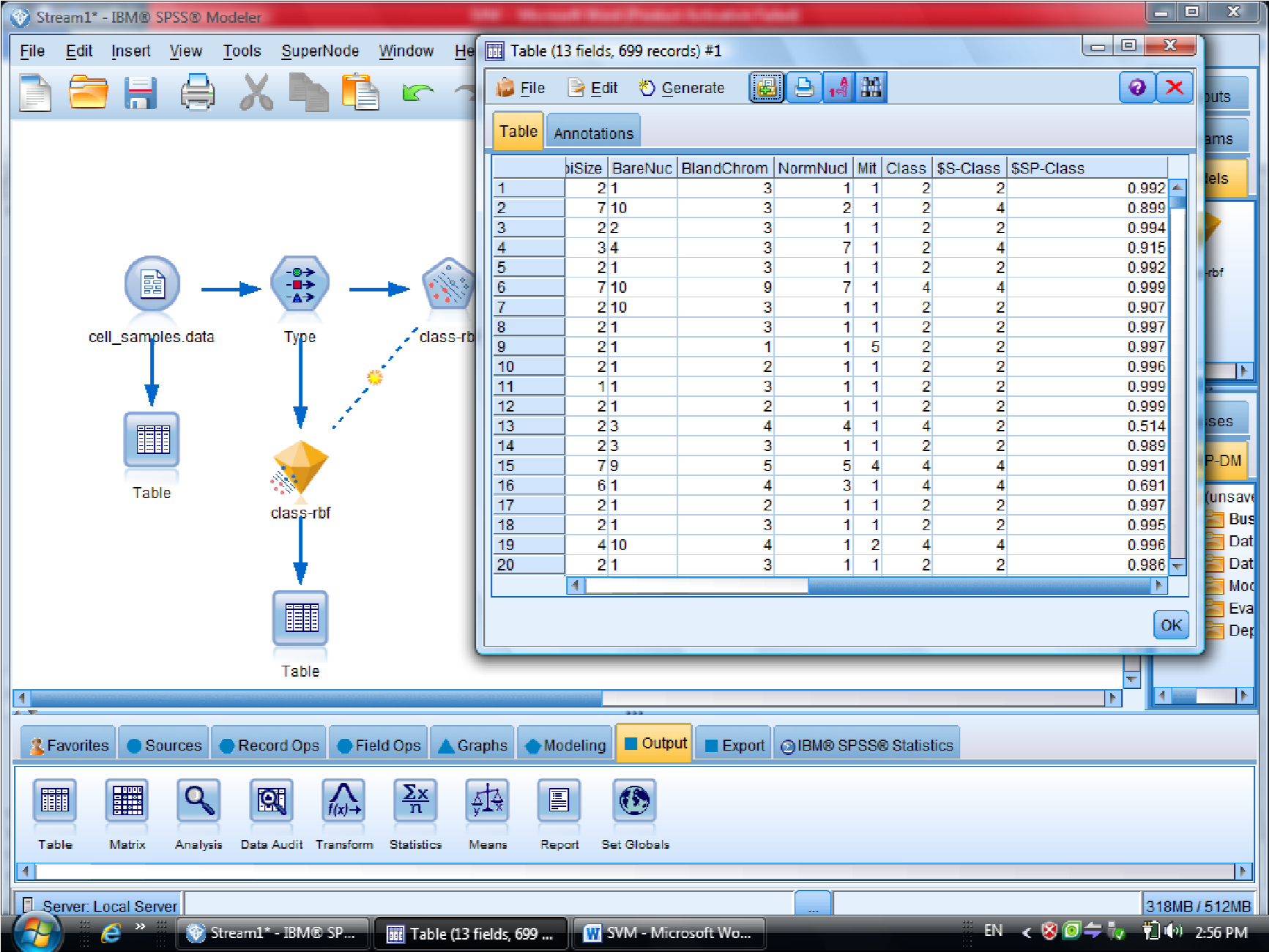
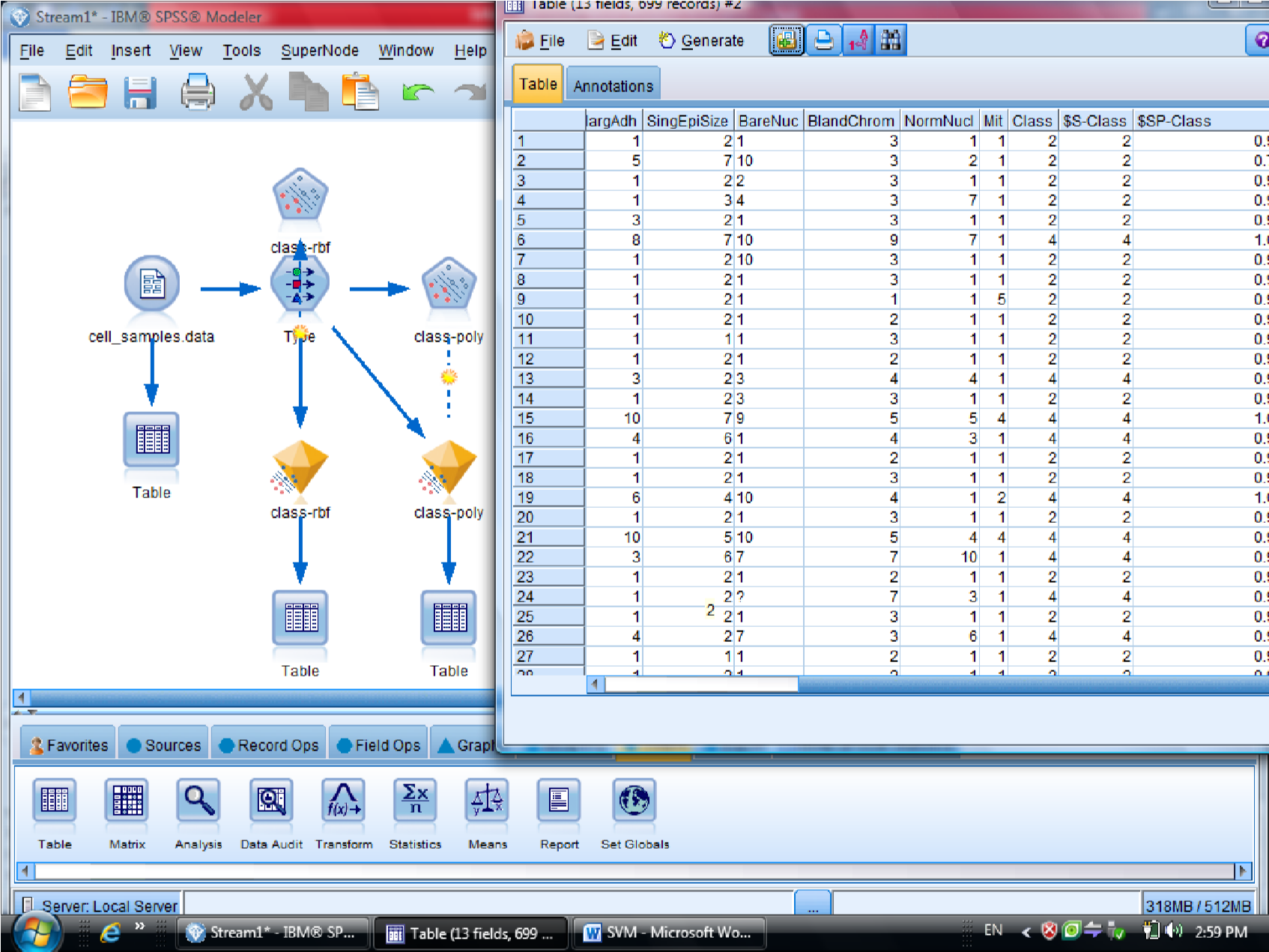
در اینجا مثالی که در Clementine هست کار می کنیم به نام Cell_samples
در این مثال متغیر Clump مشخص کننده سرطانی بودن سلول هست
متغیر ها به عنوان اندازه، شکل ، رنگ , آورده شده است و متغیر های دیگر همچنین فیلد خوش
خیم بودن سلول یا بدخیم بودن آن
که برای سلول های خوش خیم و بدخیم اطلاعات را دسته بندی می کنیم
برای این کار داده های آماده در کلمنتاین به نام Cell Samples Data که از نوع fixfile است ، می
آوریم
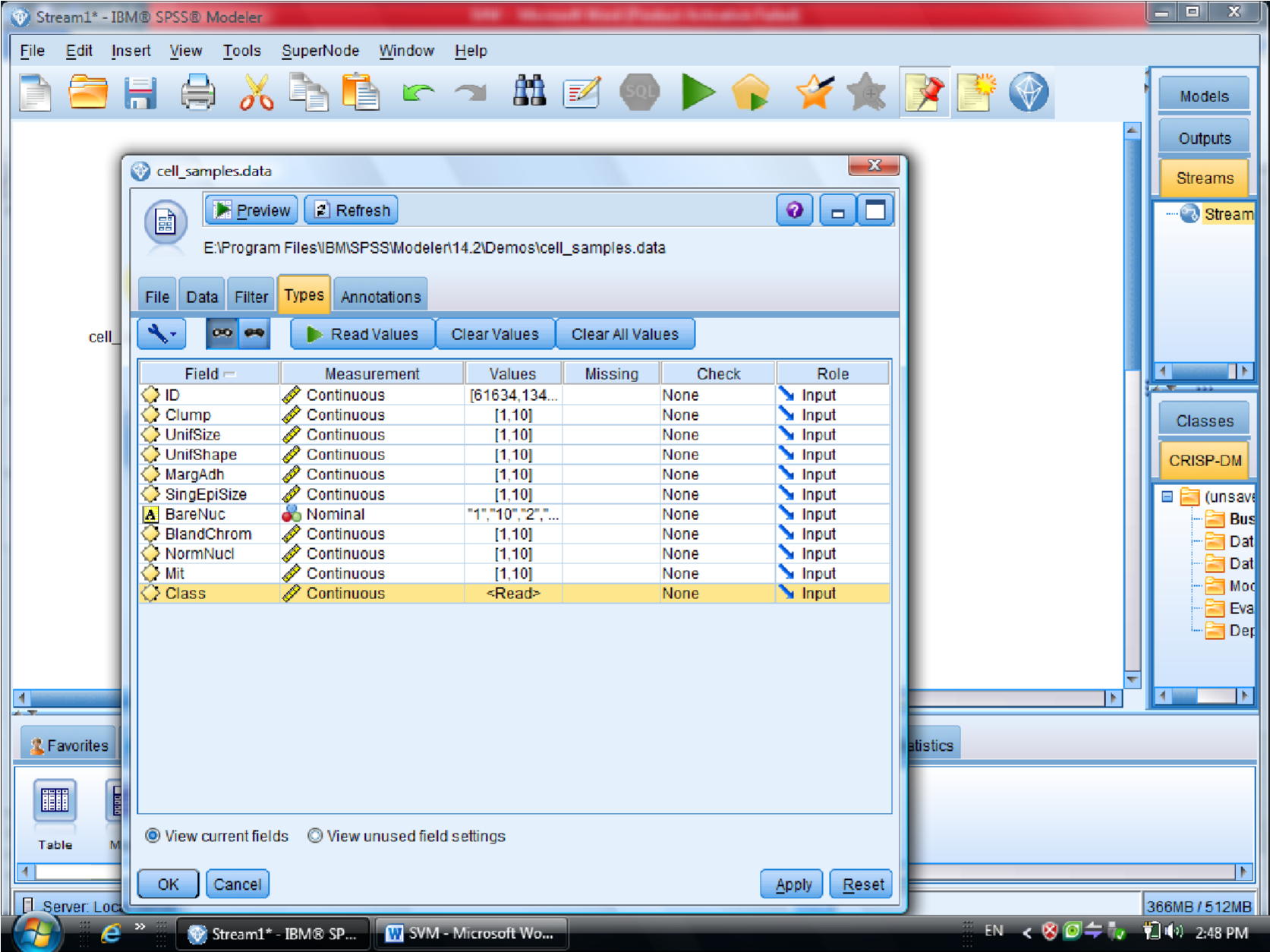
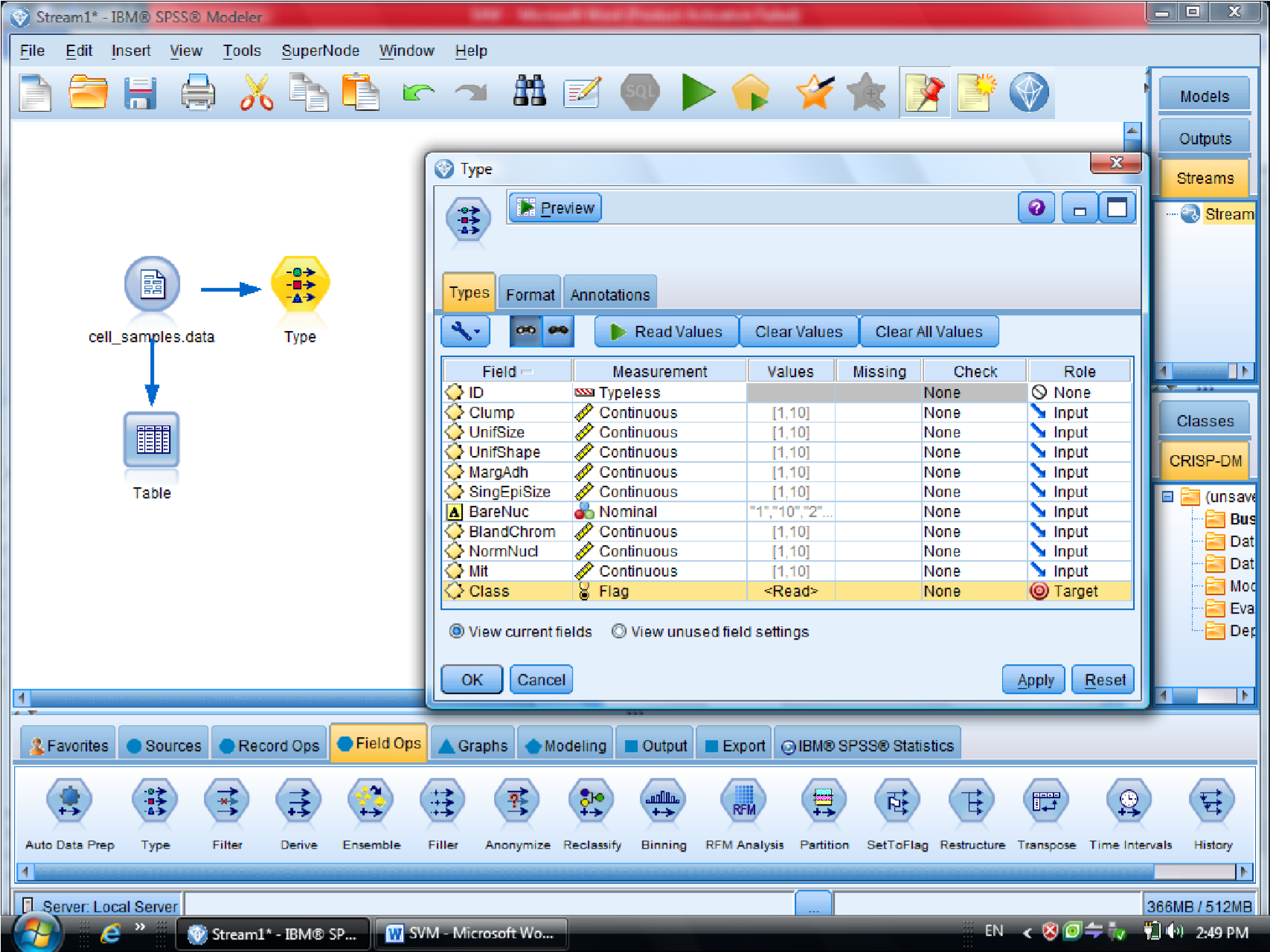
در این دیتا ست ، فیلد ID چون جزو متغیر های موثر نیست آن را فیلتر می کنیم (ID رو Typeless
کردیم)
متغیر class را به عنوان Target معرفی می کنیم (فیلدی که خوش خیم بودن سلول را مشخص می
کند )
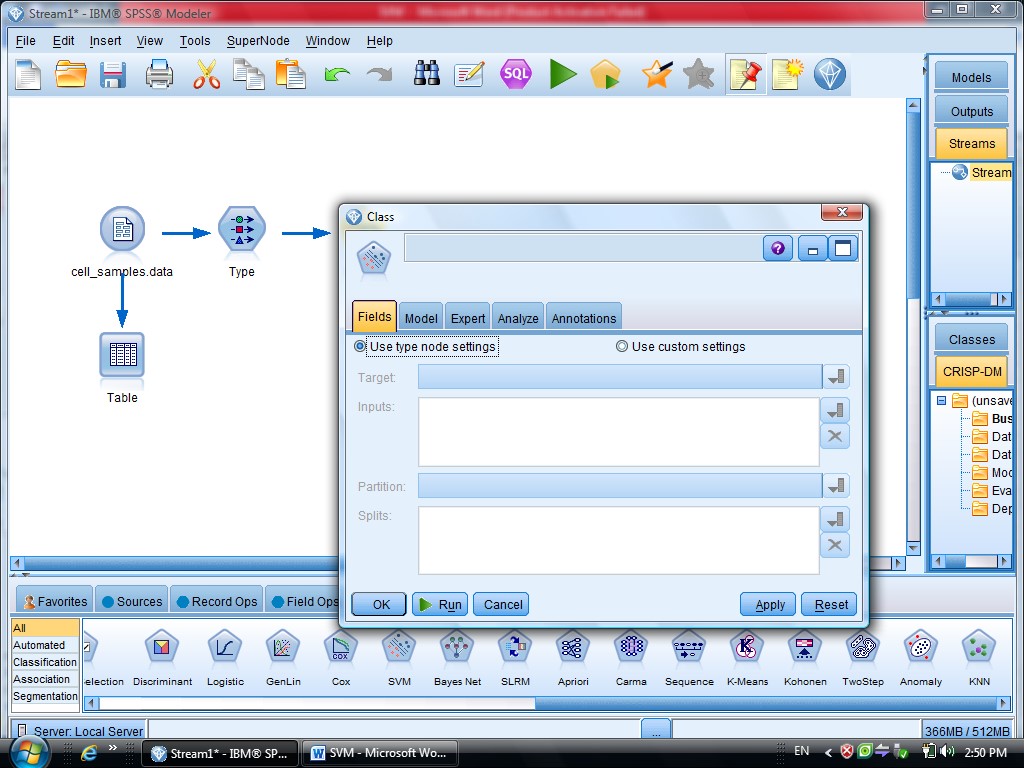
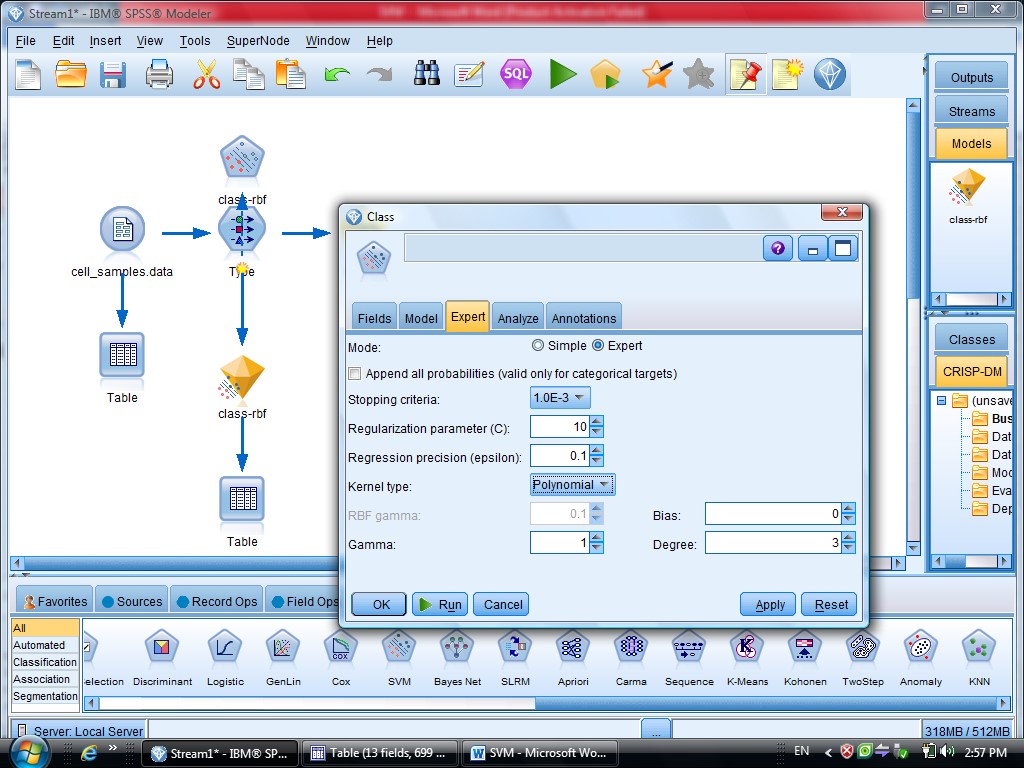
بعد از Type مدل SVM را قرار می دهیم
در گزینه type – SVM – Field متغیر های مستقل هستند ، همه متغیر های دیگر دخیل هستند
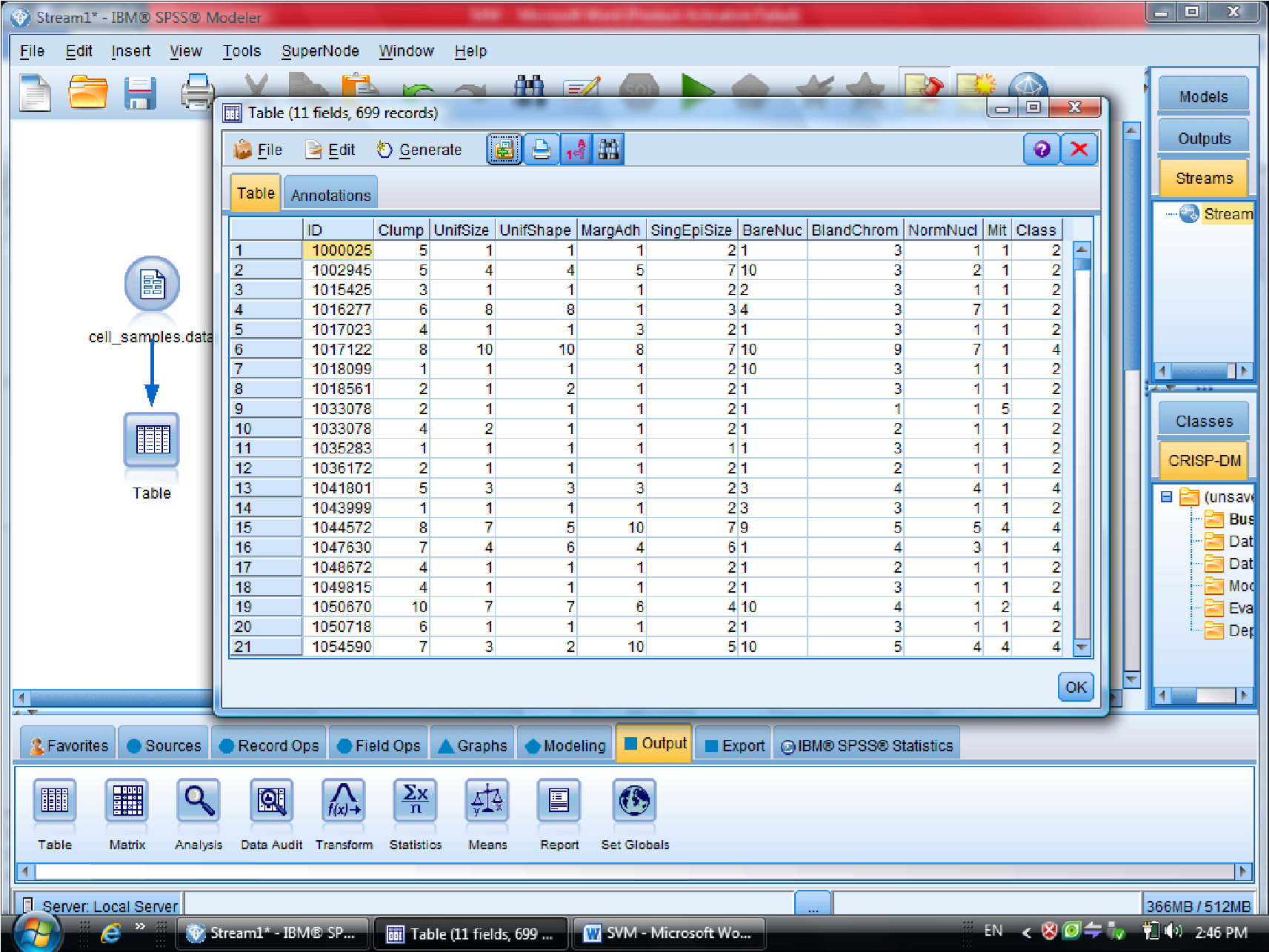
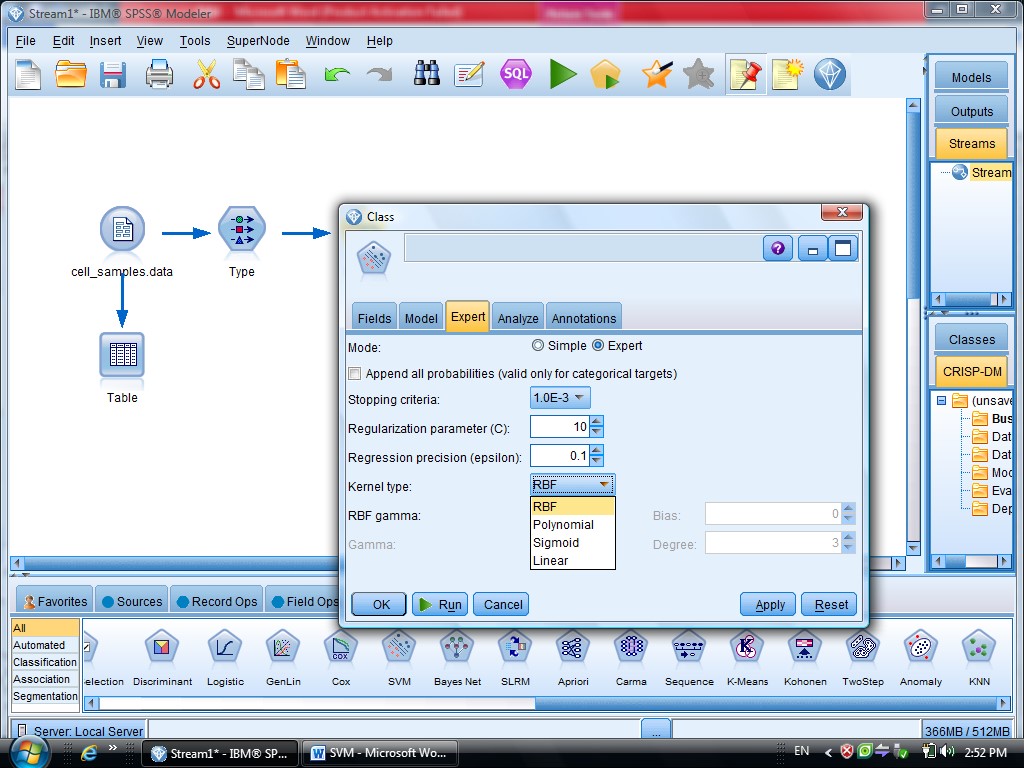
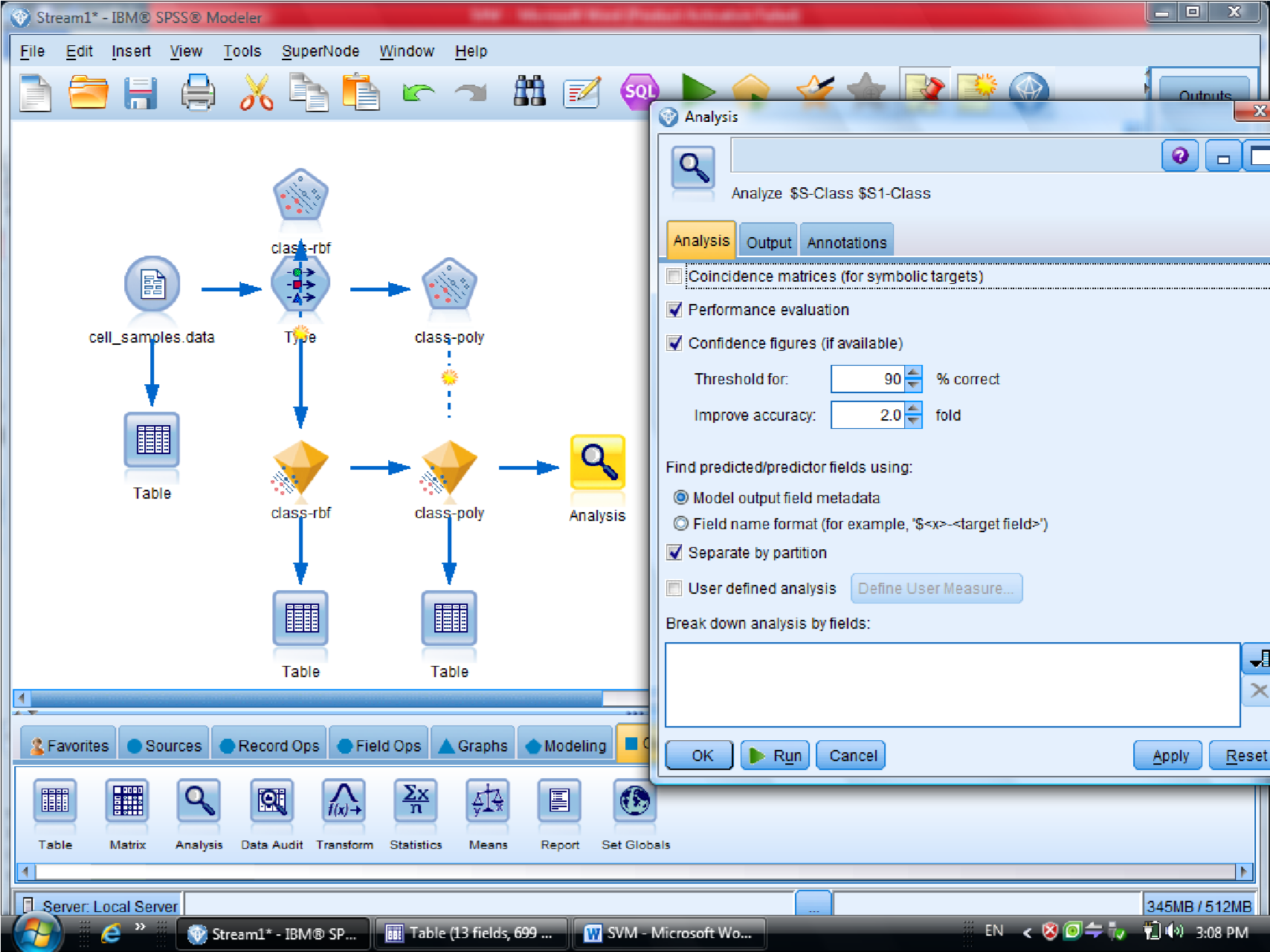
گزینه Expert در متد SVM دو گزینه sample , Expert را داریم
که ما از گزینه Expert استفاده می کنیم برای اینکه بتوانیم چند روش برای دسته بندی داده
استفاده کنیم
در SVM از تابع Kernel استفاده می شود
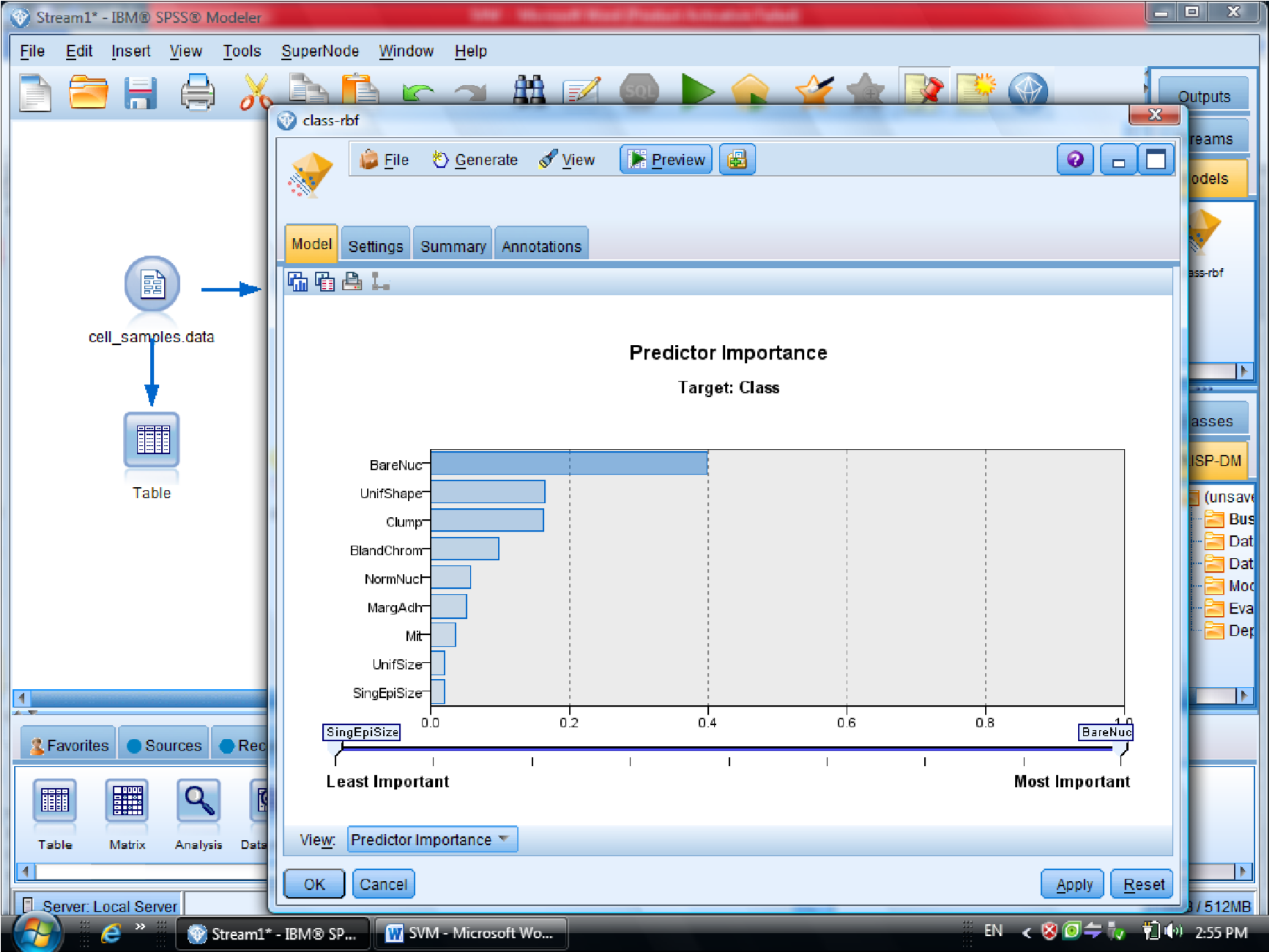
درجه وابستگی متغیر ها را می توانیم با SVM مشخص کنیم
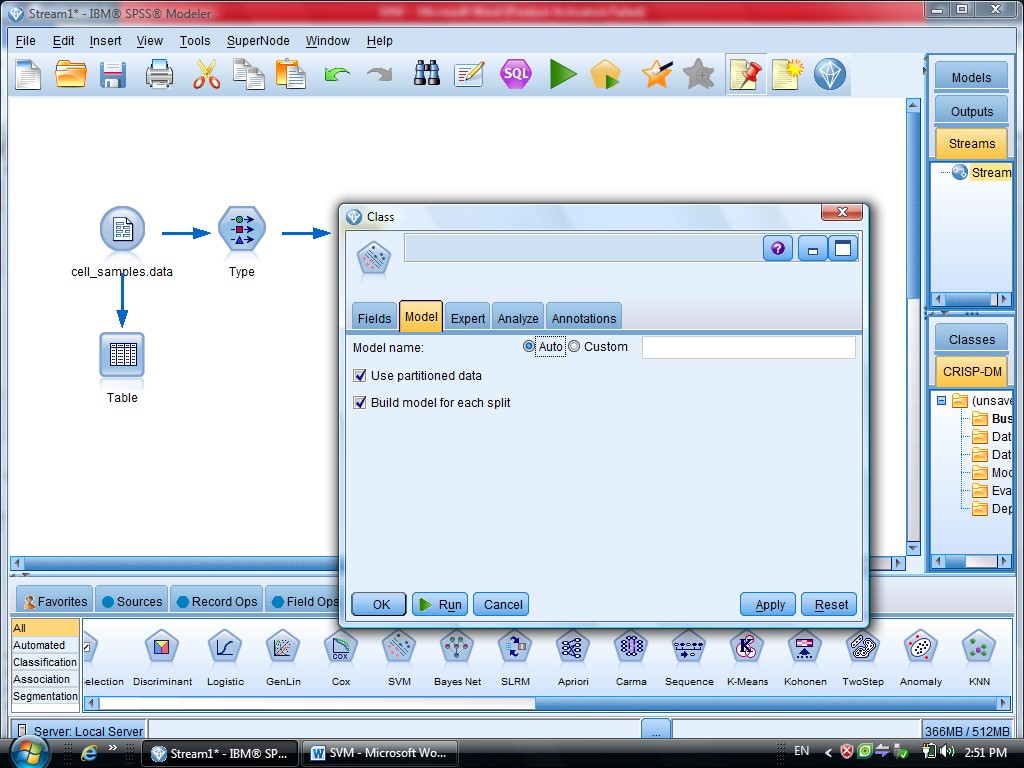
گزینه Model مربوط به مدل آیا دیتا های ما از چند قسمت تشکیل شده اند یا خیر
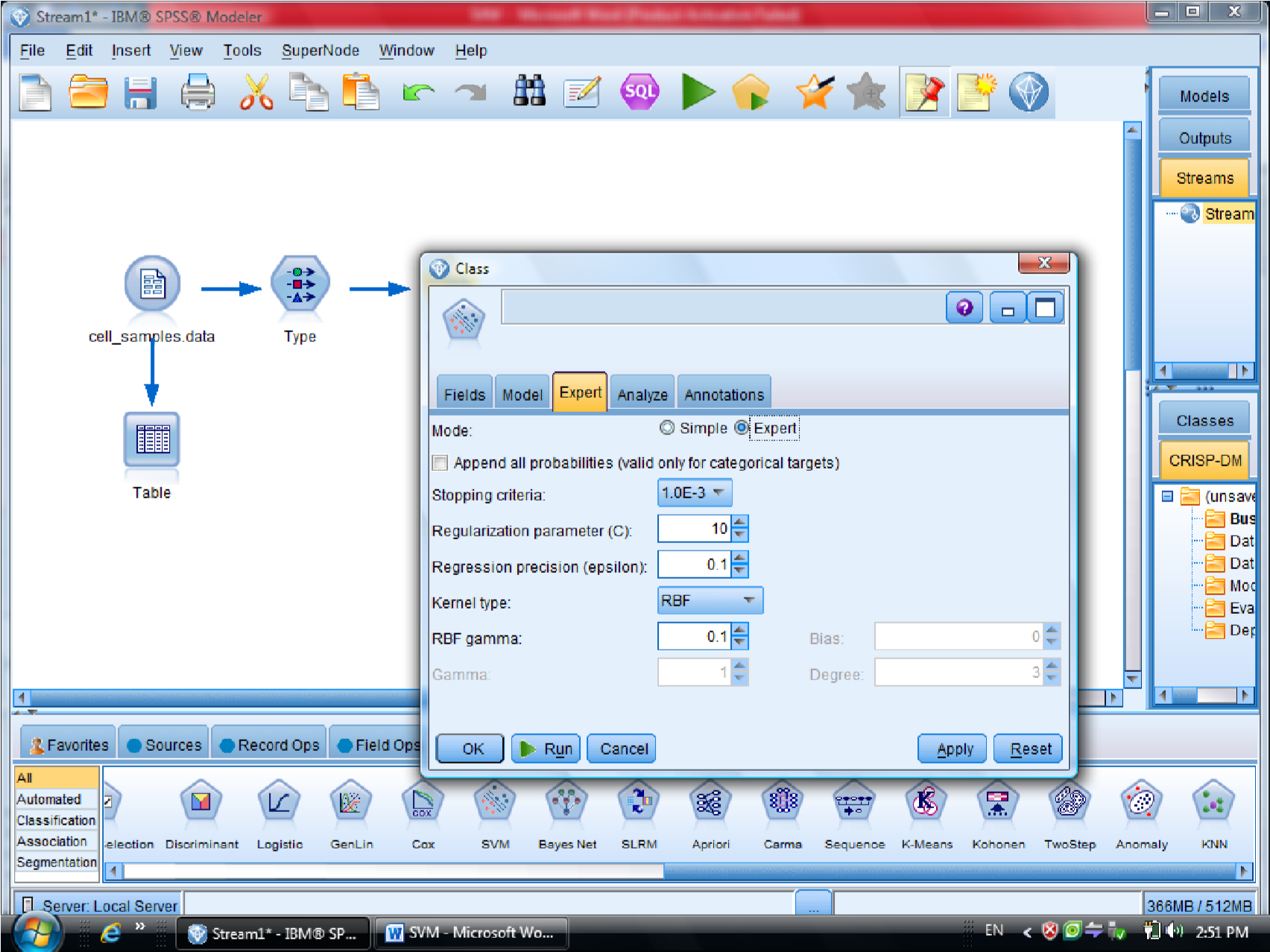
کرکره Expert دو گزینه دارد (Simple , Expert)
یاد آوری می شود روش های SVM از تابع کرنل هست
ممکنه روشهای مختلفی استفاده کنیم
با انتخاب گزینه Expert می توانید از توابع Kernel استفاده کنیم
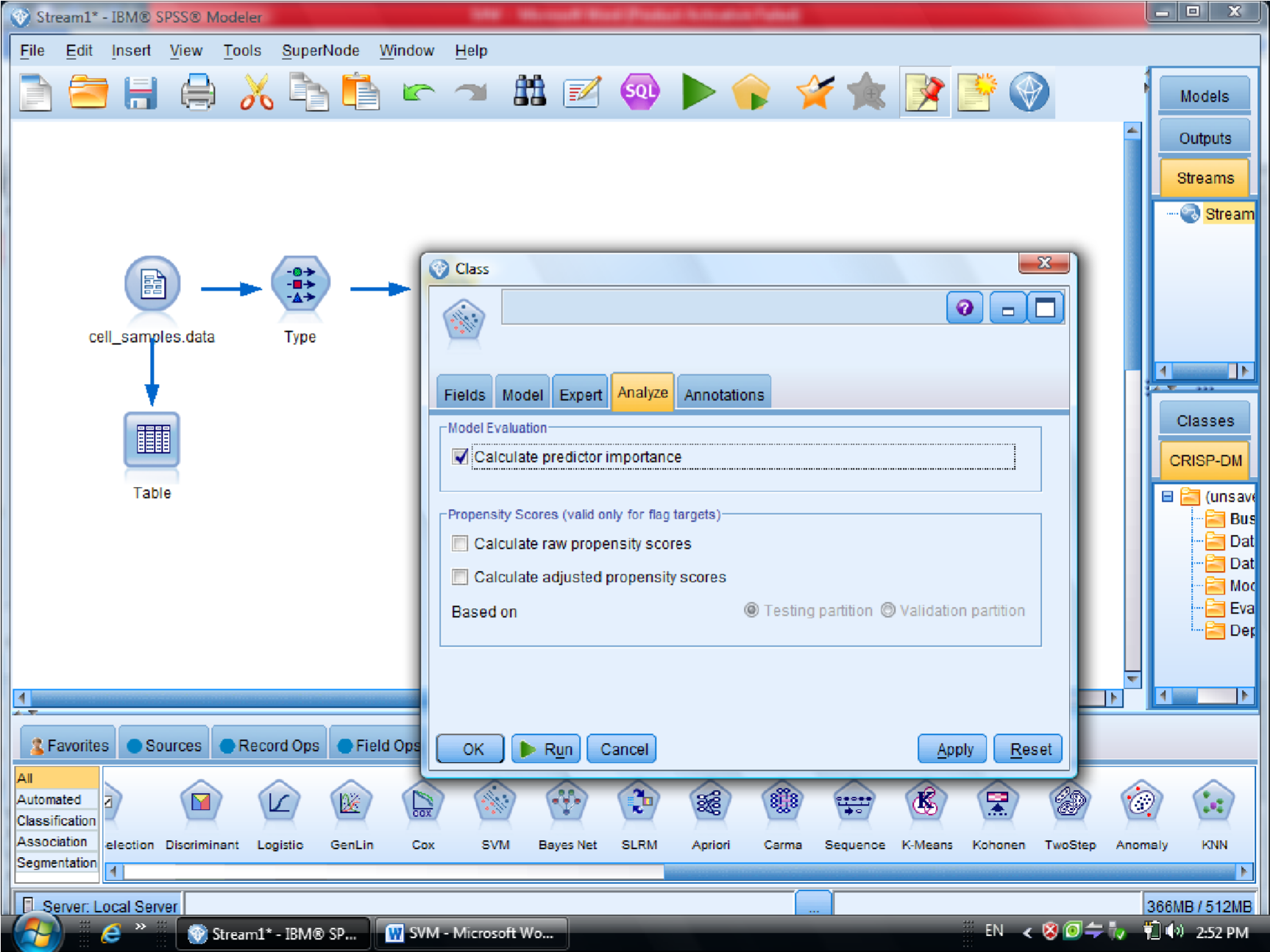
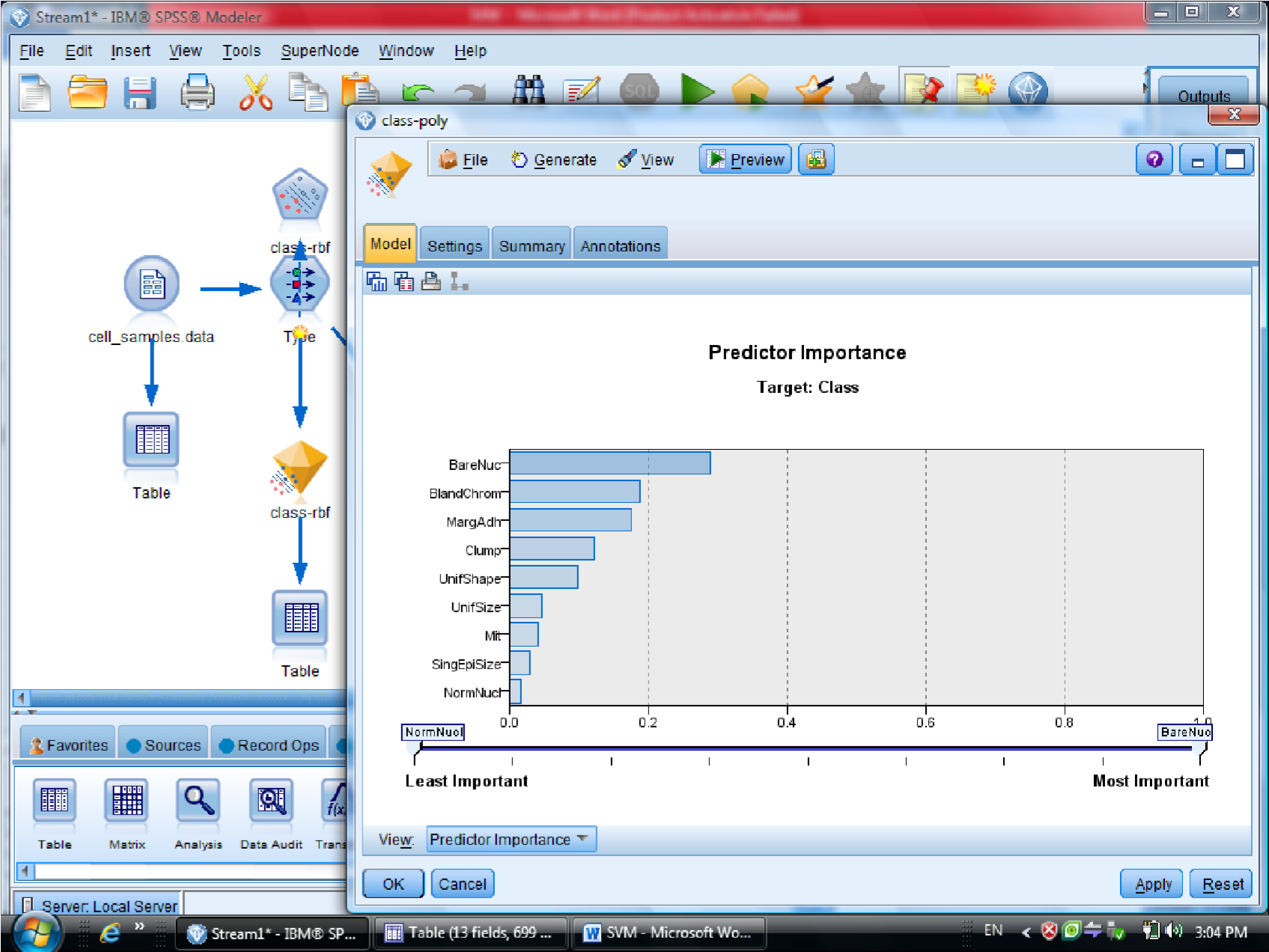
در قسمت اول متغیر ها را بر اساس درجه اهمیت نشان می دهد
احتمال برای درست پیش بینی شدن را می دهد
یکبار به روش RBF خروجی گرفتیم
این مقدار احتمال ها ممکن است خیلی به ۱ نزدیک باشد
به روش Polynomial (چند جمله ای )، خروجی مربوطه برای متغیر هایی که این فرم را دارند
میزان دقت polynomial صد در صد هست
برای مقایسه دو نتیجه دو تا الماس زرد را با هم مرتبط می کنیم ( با F2 )
و به Analysis وصل می کنیم تا مقایسه این دو نود را ببینیم
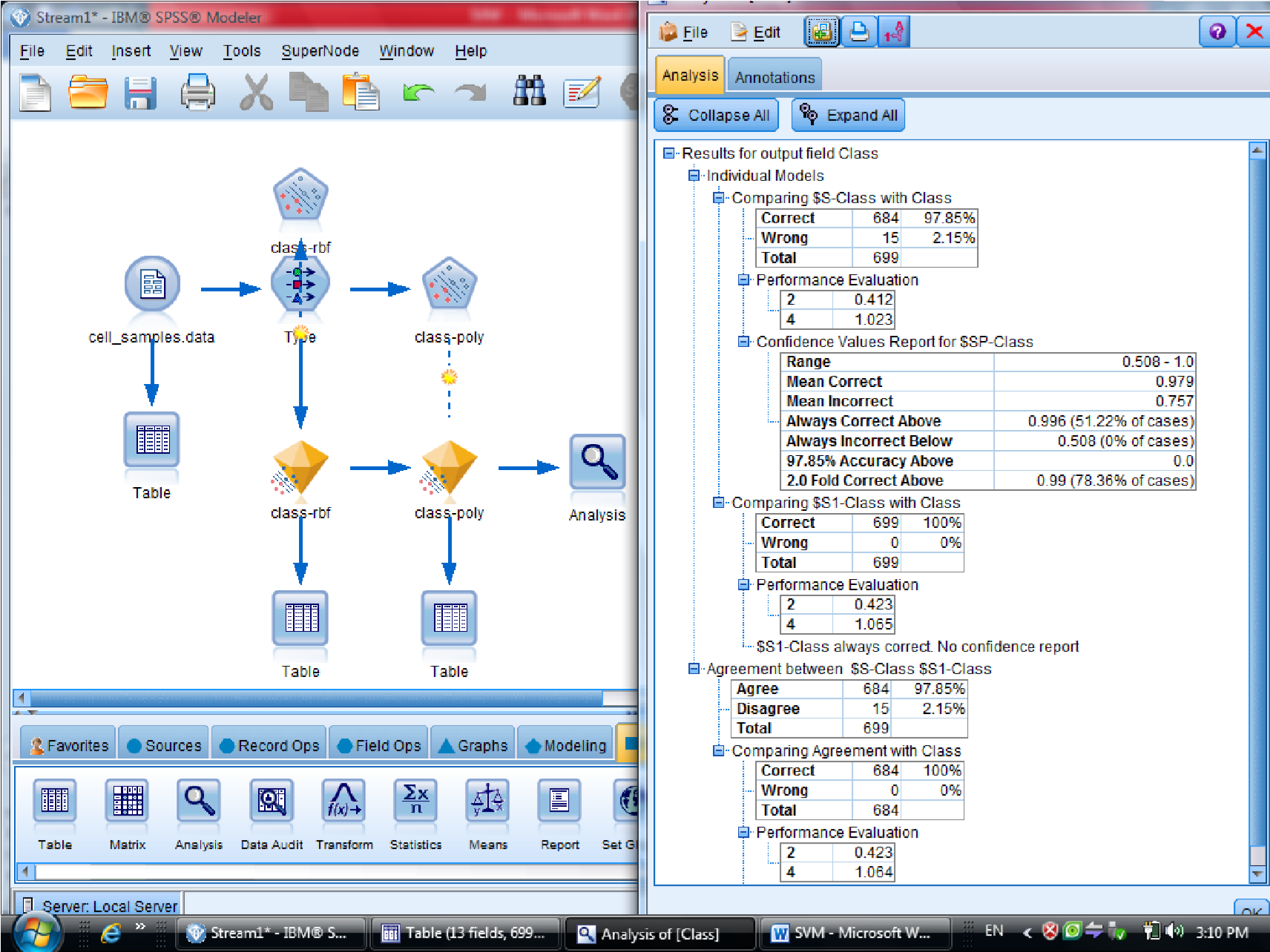
در نهایت متدی که به ۱۰۰ نزدیک تر هست ، روش مناسب تری هست
درصد دیتاهایی که درست تشخصی داده را ۰٫۹۷۹ هست
سلول های سرطانی خوشخیم که با ۲ علامت گذاری شده هست ، با احتمال اشتباه بیشتری
هست
در روش دوم ( polynomial ) میزان دقت سلول سرطانی ۱۰۰% هست
ولی برای سلول های سرطانی خوشخیم درجه احتمال بیشتری را خواهد داشت
پس بین این دو روش polynomial بهتر است
این مثال در فصل هشتم داده کاوی و کشف دانش گام به گام با Clementine خانم علیزاده هست
fine
داده کاوی و کشف دانش گام ب گام با نرم افزار Clementine علیزاده د.خواجه نصیر
یکی از روشهای مورد استفاده از متد های شبکه عصبی در داده کاوی هست
مثلا رگرسیون ارتباط متغیر های وابسته به متغیر های مستقل نشان می دهد
مثلا شرکت ها چقدر بدهی داشته باشند
سوالات :
سوال اول تعریفی است
مثلا desicion Tree
الگوریتم هایی که استفاده می کنید
درجه اطمینان و میزان پشتیبانی
روشهای خوشه بندی – kmeans خوشه بندی کنید
با Complete Linckage یا Average Linkage
آزمون تمام مطالب سر کلاس هست
 Continue reading »
Continue reading »
نوشته های تدریس یار درس خوشه بندی استاد حمیدرضا برادران کاشانی
دوستان عزیز لطفا همه توجه کنند و هیچ کامنتی نگذارند
۴ نوع تمرین است
هر کسی بایستی تمرین گروه خود را بصورت مستقل انجام دهد.
یعنی هرگز کار گروهی نیست
گروه ها را بصورت رندوم انتخاب کرده ایم.
تمرین در هر گروه بر اساس بهترین تمرین در آن گروه و بصورت نسبی ارزیابی می شود.
دوستان امروز صدا نداریم.
بنابراین گروه آسان یا سخت نداریم. یا تمرین آسان و سخت
اهمیت این تمرین که در واقع بصورت یک مینی پروژه است از سایر تمرین ها بیشتر بوده
بنابراین دوستانی که در تمرین های گذشته کارشان به نظرشان اشکالات یا کاستی های داشته می توانند در این مینی پروژه جبران نمایند.
باز هم تاکید می کنم که بهترین فردی که در هر گروه بهترین و کاملترین گزارش در آن
گروه را ارائه دهد معیاز ارزیابی آن گروه می باشد.
ضمنا تمرین فیشر را نیازی نیست کسی نجام دهد
این تمرین را به عنوان آخرین تمرین درس در نظر گرفته ایم.
لطفا تمرین را دانلود کنید همه چیز اعلام شده
پیاده سازی نمی خواهد فقط گزارش کامل
روش هایی که هدفشان تمایز بین داده های دو یا چند کلاس است مثل فیشر دیگر چه روش هایی داریم
در مورد تمرین سوالی نیست؟
روش VQ
, Kmeans
چه روش های مشابهی وجود دارند
در تمامی گروه ها هدف بیان توابع cost function جدید است
اسم تمرین در سایت shw2 است
دوستان اگر با تمرین کمی کار کنند
بعد می توانند سوالاتشات را از طریق ایمیل clustering_1391 – yahoo بپرسند

کلاس حضوری داده کاوی – ۹۲/۰۹/۲۱
آقای مهندس حائری – مرکز افکار سنجی جهاد دانشگاهی
دموی تمام الگوریتم ها را ببینید
در داده کاوی ممکن است یکی از کار های بخواهیم
توصیف
مقایسه کردن ( با استفاده از الگوریتم های t , z , Anova , Manova امکان پذیر است )
بررسی رابطه (ضریب همبستگی یا ضرایب پیوند – انواع رگرسیون )
رده بندی و خوشه بندی (درخت تصمیم – درخت رگرسیونی)
پیش بینی (time series)
پروژه ها را شروع کنید
تا آخر بهمن احتمالا وقت هست برای تحویل پروژه
جواب نمونه سوالات ترم گذشته
سوال ۱ :
a) درست است
b) نادرست است (تحلیل مولفه های اصلی نیست – اصلا به تعداد کلاسها توجهی ندارد )
c) نادرست ( EM در GMM بود و در سلسه مراتبی نیست )
d) درست است
e) درست است
f) اشتباه است
سوال ۲ :
a) در PCA مولفه های موثر در را مشخص می کند
b ) فیشر – خطی بودن
c) رسم نقاط – با روش فیشر حل می کنیم
SW^1(mu1-mu2)
سوال ۳ :
a) برچسب داشته باشد بهتر است
b) تعداد داده های اشتباه تقسیم بر تعداد کل مشاهدات
برای بهتر شدن و جلوگیری از Overfitting از CrossValidation میشه استفاده کرد
c) هزینه محاسباتی زیاد است – برای کاهش بعد
ابتدا باید similarity را باید حساب کنیم ( بجای محاسبه distance )
نمونه جدید را داریم
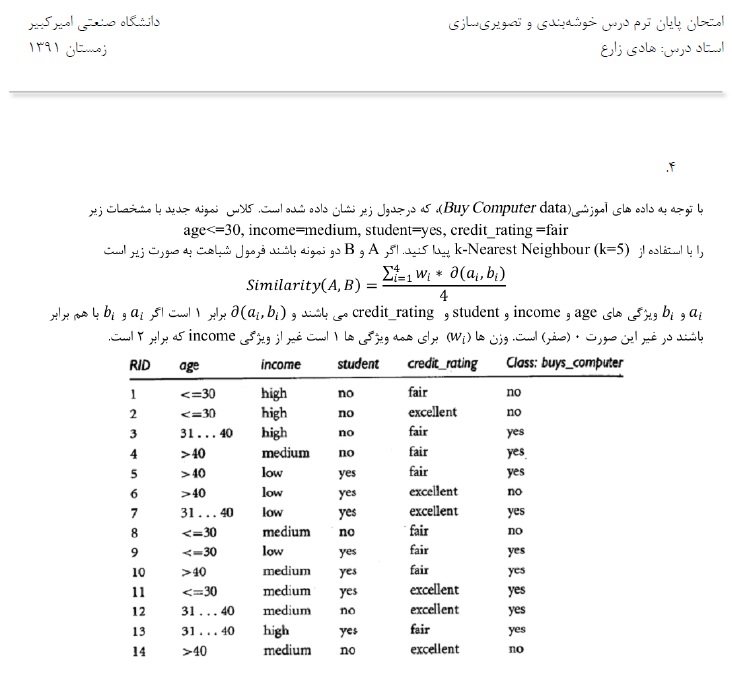
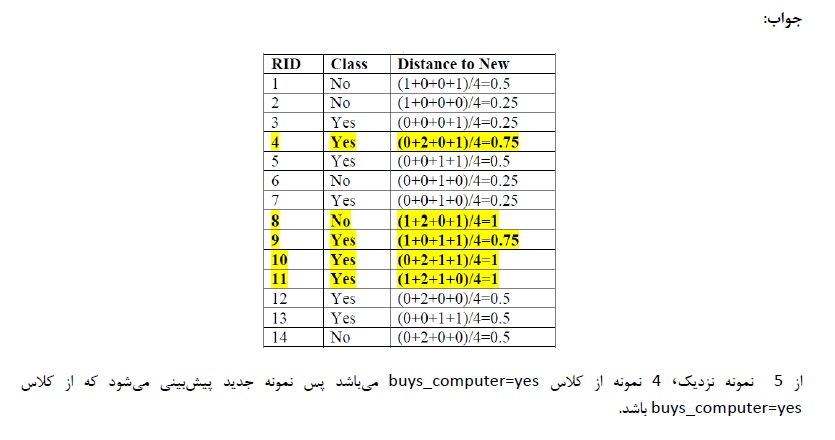
نونه سوال ترم پیش : نمونه سوال خوشه بندی – دکتر زارع

————-
ارائه خانم مهندس شیخیان
روش خوشه بندی Cure
یک روش خوشه بندی سلسله مراتبی است
سلسله مراتبی ها
خوشه ها از بالا به پایین خوشه ها مشخص تر هستند ولی انباشتگیشون بیشتر است
تمرکز خوشه بندی یک نقطه هست و بر اساس میانگین خوشه ها می تواند با هم merge شوند
مزیت Cure نسبت به سایر روشهای سلسله مراتبی تشخیص خوشه های کروی و غیر کروی را می تواند
انجام دهد
مزایای Cure حساس نبودن به شکل هست
وبه Outlier حساس نیستند چون خوشه بندی را بر اساس میانگین انجام می دهند و نه بر اساس فاصه
نقطه ها
یک الفا بین صف و یک تعریف می شود
و هر چه به صفر نزدیک تر باشد بر اساس تمام نقاط ورودی
و هر چه به یک نزدیک شود بر اساس یک نقطه انجام می دهد
در هر خوشه که تعدای نقاط را داریم
بر اساس Merge شدن نقاط هست
بقیه نقاط در مراحل بعدی با هم Merge می شوند
این روش ار random Sample استفاده می کند
خوشه بندی در دو مرحله صورت می گیرد
دیتا های ورودی پارتشین می شود
خوشه بندی ناقص انجام می شود
outlier های حذف می شود
خیلی مهم است که اندازه random Sample درست محاسبه شود.
چون ممکن است حجم محاسبات زیاد شود و یا اینکه خیلی داده ها دیده نشوند
شرط خاتمه این الگوریتم نسبت n به q هست
در سرعت این الگوریتم (Sample size و تعداد Partition ها ) بسیار مهم است
مهمترین خاصیت »: خوشه های غیر کروی هم می تواند انجام دهد
قابلیت محاسبه big data دارد
استفاده از Partitioning
———————————————————
ارائه خانم مهندس قربانی
الگوریتم Birch
برای Big Data – استفاده از الگوریتم های ساده امکان پذیر نیست
قبلا بر اساس احتمال ( یادگیری ماشین ) و یا بر اساس آمار ( روش های فاصله ) کار می کنند.
در روشهای اماری هزینه IO خیلی زیاد است
ولی روش Birch مشکلات روش های قدیم را ندارد
تراکم خوشه ها حول جرم را نشان می دهد
اگر دو خوشه را در نظر بگیریم ۵ تا معیار داریم
با استفاده از این ها فاصله اقلیدسی یا فاصله منهتن را محاسبه کنیم
با استفاده از فرمول به فاصله خوشه ها می رسیم
یک درخت به نام CF Tree می سازد
تا بتواند خوشه ها را با هم ادغام کند
در مثال آخر LS و SS مشخص شده اند
LS : مجموع خطی داده ها ست
SS : جمع مربعات n داده هست
هر کدام از پارامتر ها یک ارتفاعی دارند
که درخت CF انها را بالانس می کند
بردار CF ذخیره می شود و داده ها ذخیر نمی شود
و با کم کردن اطلاعات داده ها از هزینه های جابجایی جلوگیری می کند
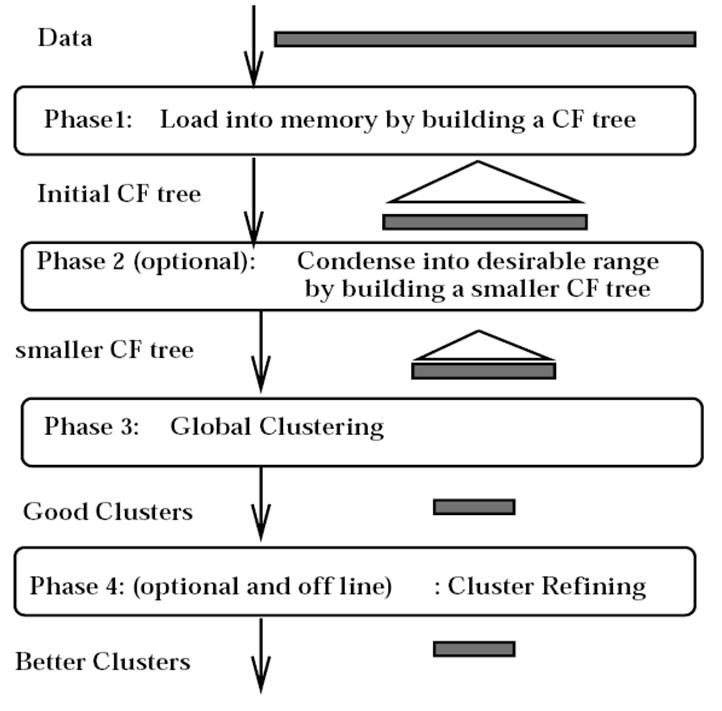
منبع : کتاب Mining of Massive Dataset
ایده کلی : تفاوت مهم Random Sampling بود
ولی birch نقاط را تبدیل به Future می کرد
دانلود رکورد کلاس حضوری دکتر محمد پور
خلاصه جلسه داده کاوی – حضوری – دکتر محمد پور
کاری که PCA انجام می دهد تعداد متغیر ها را کم می کند
ایراد های عمده PCA :
۱- مفهوم متغیر ها را عوض می کند
( ماتریس واریانی – کواریانس )
ماتریس واریانس را حساب می کنیم با ترانهاده اش ماتریس واحد شود
اگر بردار وِیژه را بدست بیاوریم ماتریس متعامد را بدست می آوریم
نتیجه : متغیر ها وابستگی به هم ندارند
بدی PCA داده های برست آمده ترکیب شده هستند
درPCA های مختلف مقایسه کار سختی است
دومین اشکال PCA : باید بردار ویژه و مقدار ویژه را پیدا کنیم
بعضی مواقع متغیر ها بسیار زیاد است محاسبه بردار وِیژه و مقدار ویژه کار بسیار سختی می شود
اشکال سوم PCA : داده ها
Uncorrolocated می شود
رابطه خطی با هم ندارند
مزیتهای PCA :
۱- بر اساس واریانس عمل می کند
به اندازه مقدار ویژه به خودش اختصاص می دهد
———————–
برای کلاسترینگ هیچ وقت از PCA استفاده نمی کنیم – فقط برای کاهش بعد استفاده می کنیم
——————————
روش Random Projection :
مزیتها :
۱- هزینه محاسباتی ناچیز است
۲- فاصه نقاط را حفظ می کند
آیا می توانید روشی را ارائه دهید که هم بعد را کم کند و دقت کاهش پیدا نکند
Stable Random Projection پایان نامه دکتر زارع
هر توزیعی یک نرمی را حفظ می کند
در روش های آماری جایی باشد که دیگر دقت کم نشود
تغییر ظرح نمونه گیری می گوییم
بعضی وقتها حجم نمونه
نحوه نمونه افراد را تغییر دهیم
واریانس این بر آورد گر نصف قبلی می شود
روش مکنتایر – در استرالی بر آورد محصول گندم را بدست آورد
در مساله کلاسترینگ یک نوع مثال بیاورید که داده ها را بعدش را کم کنیم و دقت کاهش نیابد
Ranked Set Sampling
———————
سوالات امتحان :
– Association Analysis
Clustering فارسی با فصل ۱۴ کتاب سلسه مراتبی تقریبا یکی است
DataMining-Tan-SolutionManual.pdf – سوال ۵ نمی آید
———————-
ICA
BSS :
سه نفر به سه میکروفن حرف بزنند ، صحبت ها قاطی می شود
Blind Source Seperation
جدا سازی منابع کورکورانه
مثلا یک سیگنال داریم که سیگنال اصلی را نداریم
چطور با استفاده از X بتوانیم S را بسازیم
فرض می کنیم معادله خطی بوده S=AX
ممکنه نویز هم داشته باشد S=AX+e
خلاصه کلاس حضوری مهندسی تجارت الکترونیک دکتر هاشمی ۹۲/۰۹/۲۰
نمودار فرایند کلی مهندسی و ایجاد سیستم های تجارت الکترونیک
در تمرین ها به یاد داشته باشید :
در تجارت بین خریدار و فروشنده تعامل وجود دارد
عملی تجاری محسوب می شود که رقابت در آن باشد.
مقالاتی در مورد :
در بحث توصیه گر ها
قیمت ها
ترتیب نمایش کالا ها
طراحی ابزار های کاربری در ECS
ایجاد کمپین تبلیغاتی در وب سایت های دیگر
مراحل طراحی سیستم تجارت الکترونیکی
– طراحی محتوای الکترونیکی ECS
– طراحی ابزار های کاربری
– طراحی شبکه ارتباطی و خدمات دسترسی
– طراحی خدمات الکترونیکی
– طراحی زیر ساخت پردارشی
– طراحی سناریو های خدمت رسانی به کاربران
ابزار کاربری تاثیر گذار بر شکل و نحوه ایجاد محتوا برای موضوعات نیاز کاربران
طراحی ابزار کاربری در بیشتر موارد شامل انتخال از بین ابزار های موجود می دانیم
– موبال / اندروید / با صفحه نمایش ۷٫۷ / ۳G –> سیار و همراه کاربر + محدودیت نمایش محتوا
– کامپیوتر رومیزی / Win 7 / صفحه نمایش ۱۵اینچ / شبکه ۱Gig –> ثابت + عدم محدودیت در نمایش محتوا
می توانیم چند ابزار هم استفاده کنیم
مراحل طراحی ابزار کاربری
۱- تعریف شرایط والزامات هر کاربر در درسترسی به محتوای مورد نیاز
۲- بررسی و تعیین طیف ابزار های کاربری موجود و قابل استفاده
۳- انتخاب ابزار مناسب برای هر دسته نیاز کاربران تجاری
خلاصه درس حمل و نقل هوشمند – دکتر قطعی – ۹۲/۰۹/۱۹
الگوریتم بهترین مسیر بین دو گره
تلاش های متفاوتی در این زمینه انجام شده
ولی زمان زیادی می برد
باید در زمان معقول بدست بیاید
بهترین مقدار w را پیدا می کنیم
میو = ۱٫۵ پیشنهاد شده
دوباره برای این مسیر Cp و Tp را محاسبه کردم
خط جدیدی بدست آمده
فضای w که کران پاین با رنگ آبی نمایش داده شده ایت
لاگرانژ برابر ۲ شده در ضریب لاگرانژین گذاشتیم
مقدار لاگرانژین بهینه همان ۲ بدست می آید
بنابر این با ۲ بار تکرار لاگرانژ مساوی دیگر الگوریتم را متوقف می کنیم
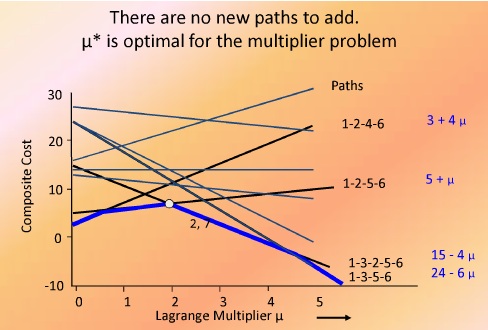
[image lagrange ]
سوال : ایا لاگرانژین ربطی به LP هم دارد یا نه
یک تئوری :
فرض می کنیم یک تابع خطی داریم که می خواهیم شبیه سازی کنیم
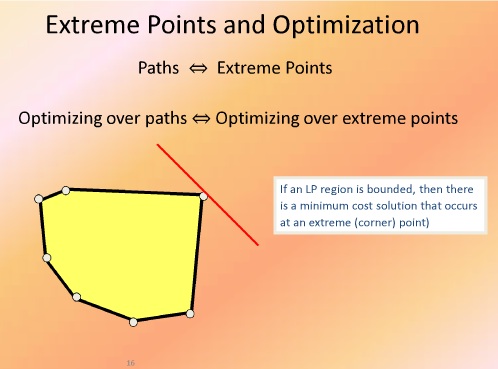
یا این مساله جواب بهینه دارد یا ندارد
اگر جواب بهینه داشته باشد مثلا عدد ۱۰۰ یا ۲۰۰ باشد
این امکان هست که یک نقطه گوشه ای وجود دارد که جواب بهینه باشد
[image extreme points and optimization]
در مسایل شبکه نقاط گوشه ای جایشان را می دهند به مسیر ها
بنابراین ما مسیر ها را مانند گوشه ها در نظر می گیریم
در شبکه ها هم جواب بهینه مانند نقاط گوشه ای پیدا می شود مانند LP
در مسایل ITS انتخاب هایی گسسته داریم
یا به صورت Integer
پس فضای شدنی و فضای جواب به صورت چند وجهی نیست بلکه مانند نقاط گسسته داخل فضا هست
در شکل خارجی ترین نقاط را به هم وصل می کنیم تا شکل چند وجهی محدب بست بیاید
این چند وجهی به ما کمک می کند که جواب بهینه تقریبی را بدست بیاوریم
پس یک ارتباط دو طرفه برقرار می شود
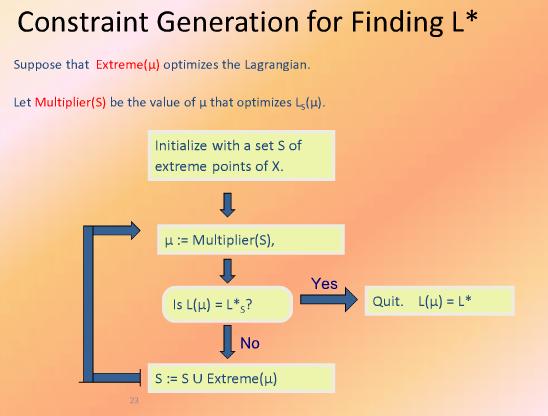
در تئوری می توان ثابت کرد x1 تا xn نقاط راسی ما باشند بقیه نقاط به صورت ترکیبی از نقاط قابل نوشتن هست

Convex Hulls
در لاگرانژین مینیمم سازی cx
مساله لاگرانژ تبدیل به مساله لاگرانژ روی نقاط راسی تبدیل می شود
در این حالت یک کران بالا برای w ها پیدا می شود
بهترین مقدار w با این شرایط محاسبه می شود
مقدار بهینه *L پیدا می شود
مقدار بهینه لاندا ها پیدا می شود
البته مسایل لاگرانژین بخاطر کاربرد های متنوعی که در بهینه سازی دارد خیلی ها به دنبال راهکار هایی برای بهبود هستند که الگوریتم های لاگرانژین محکم و مستدل هستند
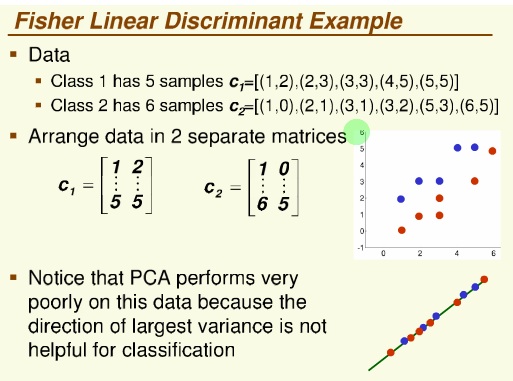
روش فیشر
پراکنش داده ها
داده ها را از دو بعد به یک بعئ می خواهیم map کنیم
فقط جهت بردار مهم است
معیار یا جهت مناسب ، جهتی است که جدا پذیری دو کلاس زیادباشد
و تقسیم بر پراکنش درون کلاسی هم می کنیم (که هر چه کمتر باشد بهتر است )
نام این مساله : مساله مقدار ویژه تعمیم یافته
این نمونه معمولا در امتحان می آید
یا مفهوم این که Fisher با PCA جه فرقی می کند
نمونه ای که ممکن است در امتحان بیاید
معمولا دوستان در اینورس کردن ماتریس اشتباه می کنند
جهتش هم می خواهیم که رسم کنید
——————————–
روش های خوشه بندی
فرض می کنیم دستگاهی برای دسته بندی و بسته بندی ماهی داریم
برای تفکیک ماهی ها از روش های خوشه بندی می خواهیم استفاده کنیم
اولین قدم data Gathering هست – طبقه بندی اطلاعات اولیه جمع آوری شده
خیلی از مسایل خوشه بندی تعبیر Geo metric دارند
اگر بتوانیم Rule برایش تعریف کنیم
آقای فیشر اولین بار مساله pattern Recognition را حل کرد و داده های IRIS رو مطرح کرد

قانون که می گذاریم باید برای داده های بعدی هم خوب کار کند
هر چه مدل ساده تر باشد احتمال اینکه برای داده های بعدی هم کار کند محتمل تر است
over fitting
به صورت simple از هم جدا کنیم
Predictive Accuracy
صحت پیش بینی
Accuracy صحت : تعداد صحیح ها تقسیم بر تعداد کل نمونه ها
خطا : تعداد اشتباهات تقسیم بر تعداد کل نمونه ها
روش k-fold :
داده ها را به دو قسمت تقسیم می کنیم
داده های train و داده های test
یک مدل را بر اساس داده های Train می سازیم و test را با آن آزمایش می کنیم
داده ها را به k قسمت مساوی تقسیم می کنیم
قدم اول : مدل را می سازم و با قسمت k ام خطای مدل را بدست می آوریم
قدم دوم : k-1 را Train در نظر می گیریم و باز خطا را بدست می آوریم
یک مقاله به صورت تجربی (imperical ) بخش ها را به ۱۰ قسمت تقسیم کردند
و ما هم اکثر مسایل رو ۱۰-fold می گوییم
Nearest Neighbor Classifier
هر داده جدیدی که آمد فاصله اش را با کل داده های قبلی حساب کن ، سپس sort کن
کمترین فاصله ها اکثریت را پیدا می کنیم
جزء روش های Lazy محسوب می شود چون خیلی هزینه بر هست ( با محاسباتی زیاد
هست )
جلسه بعد nearest neghbor را می گوییم
خلاصه مباحث درس مهندسی تجارت الکترونیک – خانم قوامی پور
فاز دوم تمرین تا هفته دیگه مهلت دارد
مقاله : اونهایی که آپلود کردند
برای پروژه تحقیقاتی معمولا تا بعد از امتحان فرصت دارید
PGFD را به صورت پیوست بفرستید
مقاله در مورد hidden markov chain کسی کار کرده ؟ ( از بچه های کلاس کسی کار نکرده بود )
خروجی فعالیت های بازار یابی : خروجی حاصل عمل بازاریابی – علاقه مندی هر کالا چه چیزی هست
توضیحات روی فاز دوم تمرین :
در شیت اول ماتریس جریان کار ، هر کدام از ستون های برای چه هدفی ایجاد شده اند
مراحل انجام فعالیت جزء به جزء نوشته می شود
برای تکمیل شیت دوم بهتر است که PGFD را از قبل کشیده باشید
برای ۵ تا فعالیت که PGFD دارید این شیت دوم را کامل کنید
نوع جریان : داده ، کالا ، مالی می تواند باشد
موضوع جریان :
ابزار جریان : وسیله ای که توسط آن جریان اتفاق می افتد ، مثلا داده در چه فرمی ارسال شده ، یا کالایی که توسط خط هوایی ارسال شده
می توانید فعالیت ها را جدا در نظر بگیرید یا اینکه در یک شیت بکشید
برای فعالیت هایی که تمام الکترونیکی یا نیمه الکترونیکی هستند را بیاورید ، چون فعالیت های غیر الکترونیکی کمکی به سیستم شما نمی کند.
مثلا یک مشتری keyword وارد سیستم می کند
از کاربر به ECS – نوع جریان : داده – موضوع محتوای جریان
حتما موضوع مقاله را بفرستید
دانشجویان گرامی:
ارزیابی دروس از طریق وب از تاریخ ۹۲/۰۹/۱۶ تا ۹۲/۱۰/۰۲ اجرا می گردد. دفتر نظارت و ارزیابی توجه دانشجویان محترم را به نکات زیر جلب مینماید.
دقت در پاسخگویی به سئوالات، مشارکت همه جانبه و ارائه پیشنهادات سازنده در بهبود کیفیت آموزش و امر تدریس دانشگاه بسیار مؤثر می باشد.
نظرات شما بدون ثبت اطلاعات فردی ذخیره و مورد ارزیابی قرار خواهد گرفت.
خواهشمند است شخصاً اقدام به انجام ارزیابی نمایید.
تذکر: ارزیابی کلیه دروس ثبت نامی برای تمامی دانشجویان الزامی میباشد و در صورت عدم انجام، مشاهده کارنامه در پورتال آموزشی امکانپذیر نخواهد بود.
از همکاری شما متشکریم
دفتر نظارت و ارزیابی و برنامه ریزی دانشگاه