الگوریتم SVM در Clementine
SVM معمولا برای داده های بزرگ به کار می رود
SVM – Support Vector Machine از خانواده یادگیری ماشین و هوش مصنوعی هست
معمولا زمانی از این روش استفاده می کنیم که حجم داده ها خیلی زیاد باشد
مثلا راجع به داده های پزشکی ، سلولهای سرطانی کاربرد دارد
در اینجا مثالی که در Clementine هست کار می کنیم به نام Cell_samples
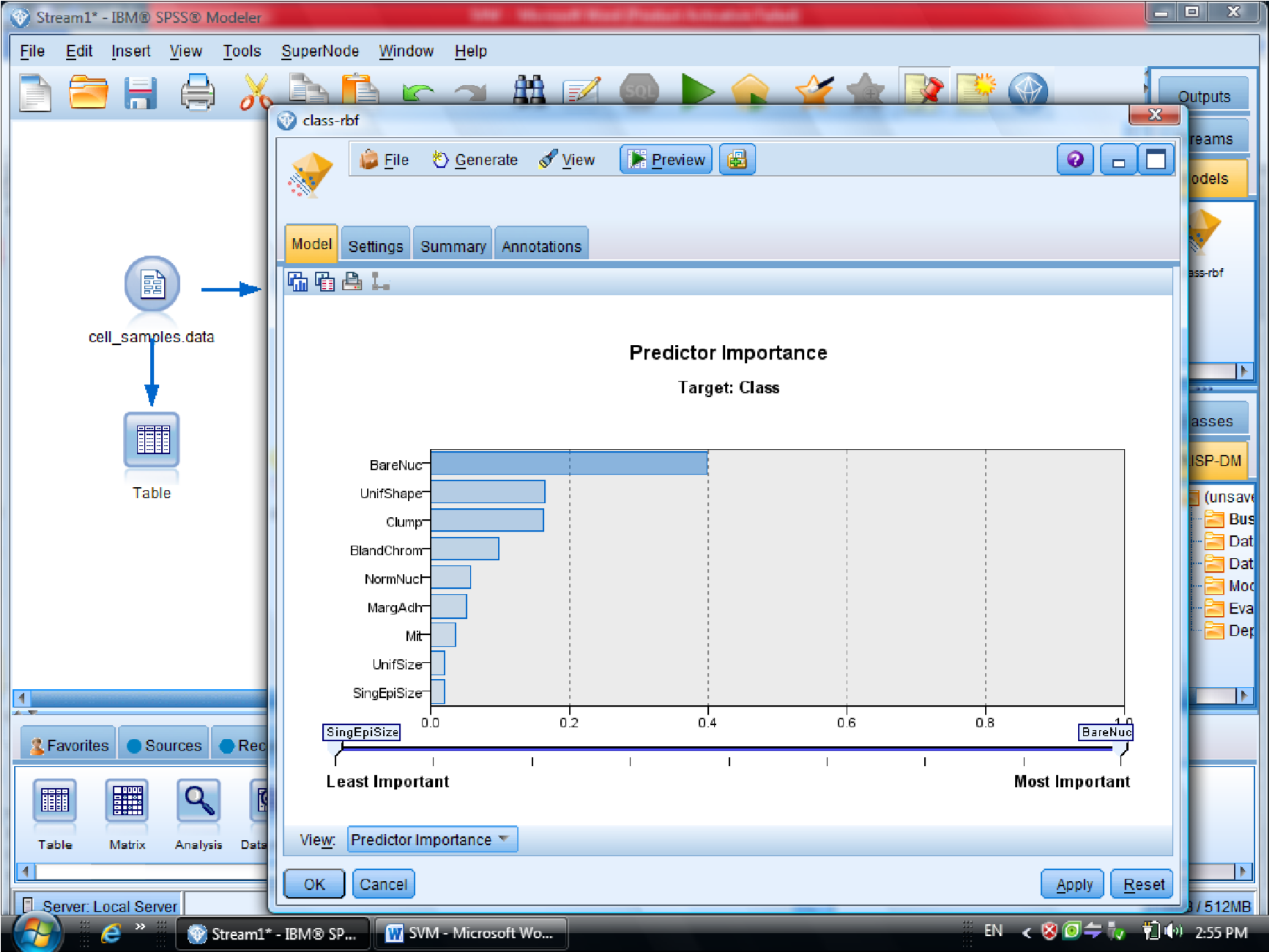
در این مثال متغیر Clump مشخص کننده سرطانی بودن سلول هست
متغیر ها به عنوان اندازه، شکل ، رنگ , آورده شده است و متغیر های دیگر همچنین فیلد خوش
خیم بودن سلول یا بدخیم بودن آن
که برای سلول های خوش خیم و بدخیم اطلاعات را دسته بندی می کنیم
برای این کار داده های آماده در کلمنتاین به نام Cell Samples Data که از نوع fixfile است ، می
آوریم
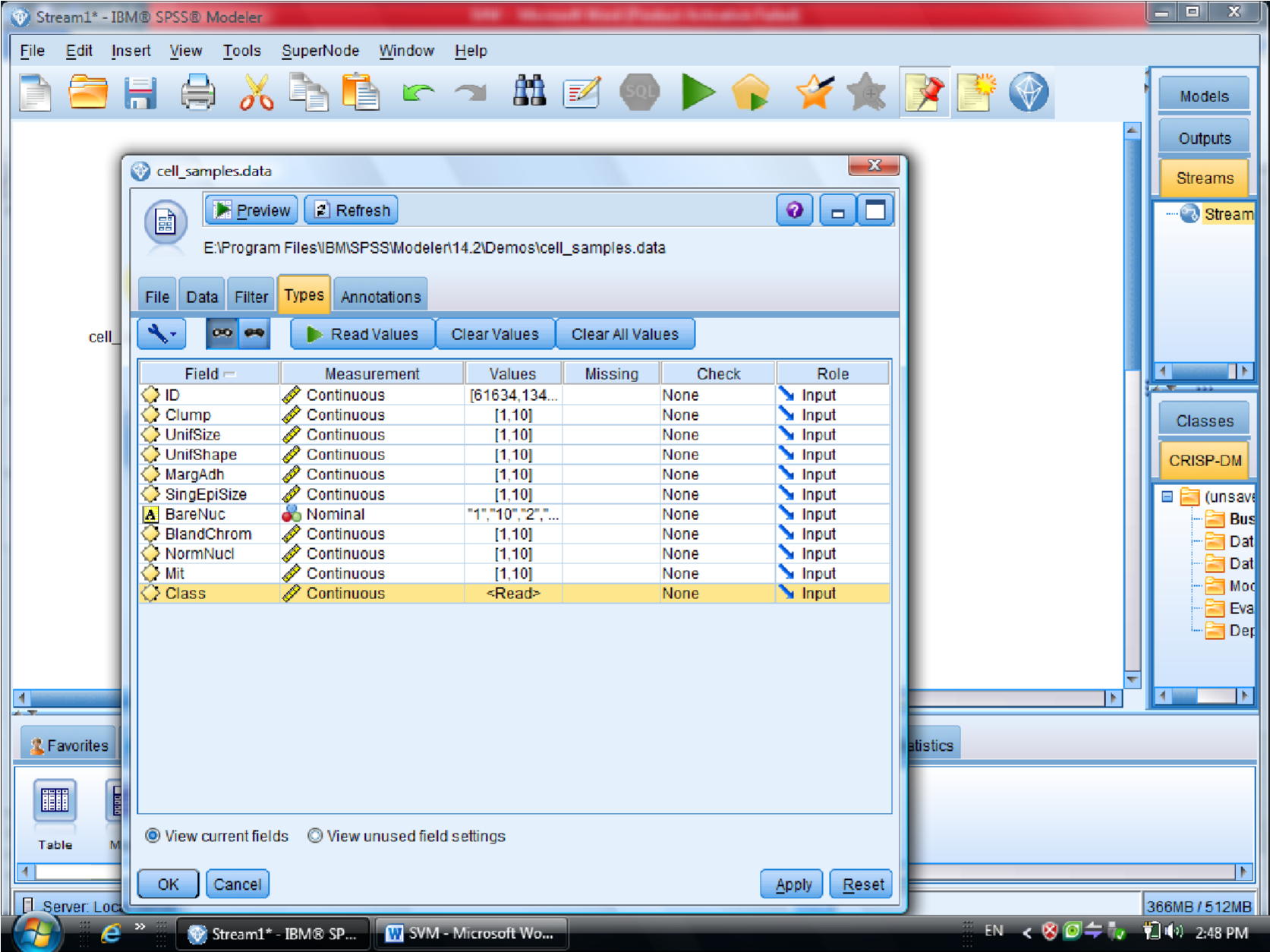
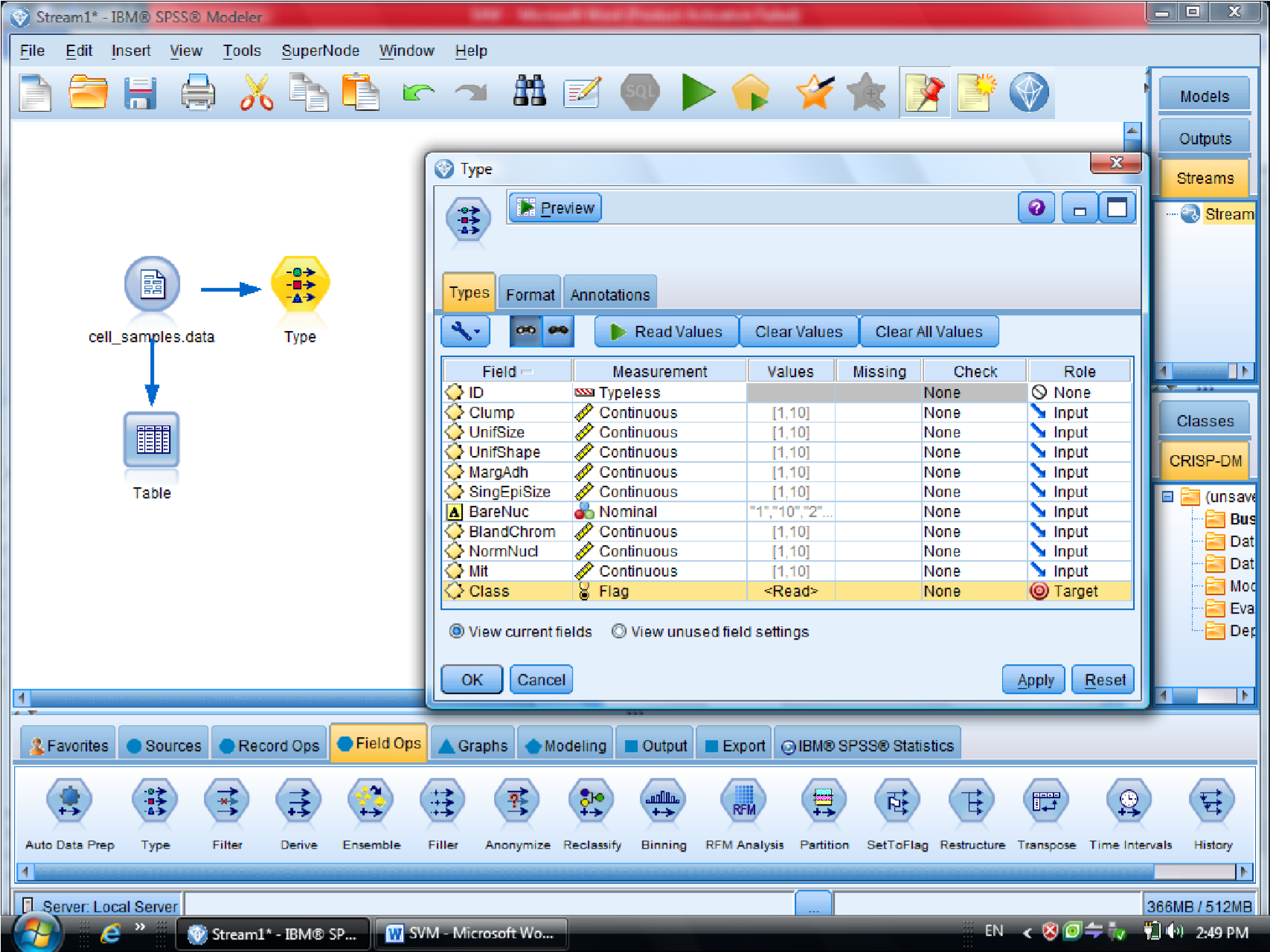
در این دیتا ست ، فیلد ID چون جزو متغیر های موثر نیست آن را فیلتر می کنیم (ID رو Typeless
کردیم)
متغیر class را به عنوان Target معرفی می کنیم (فیلدی که خوش خیم بودن سلول را مشخص می
کند )
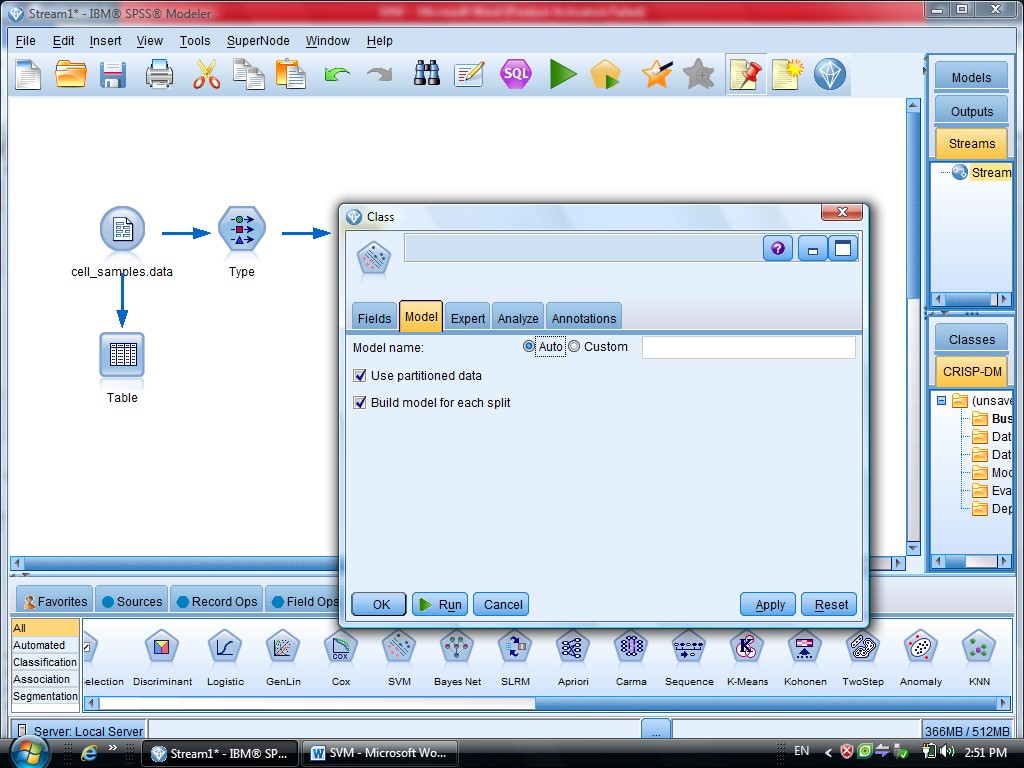
بعد از Type مدل SVM را قرار می دهیم
در گزینه type – SVM – Field متغیر های مستقل هستند ، همه متغیر های دیگر دخیل هستند
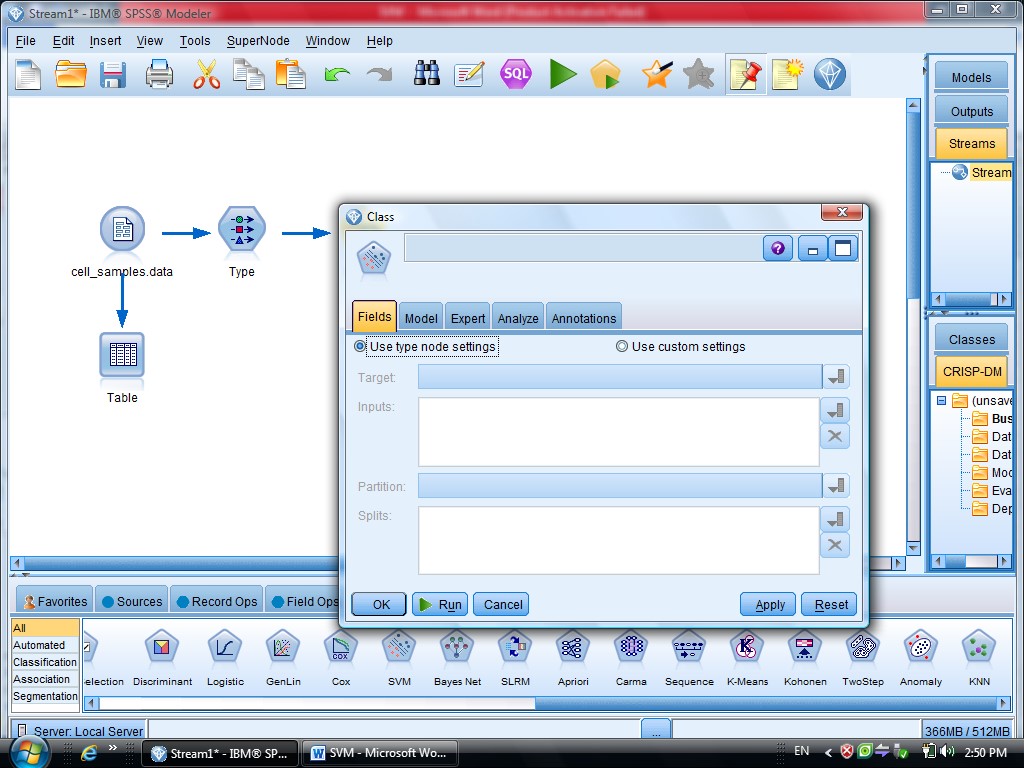
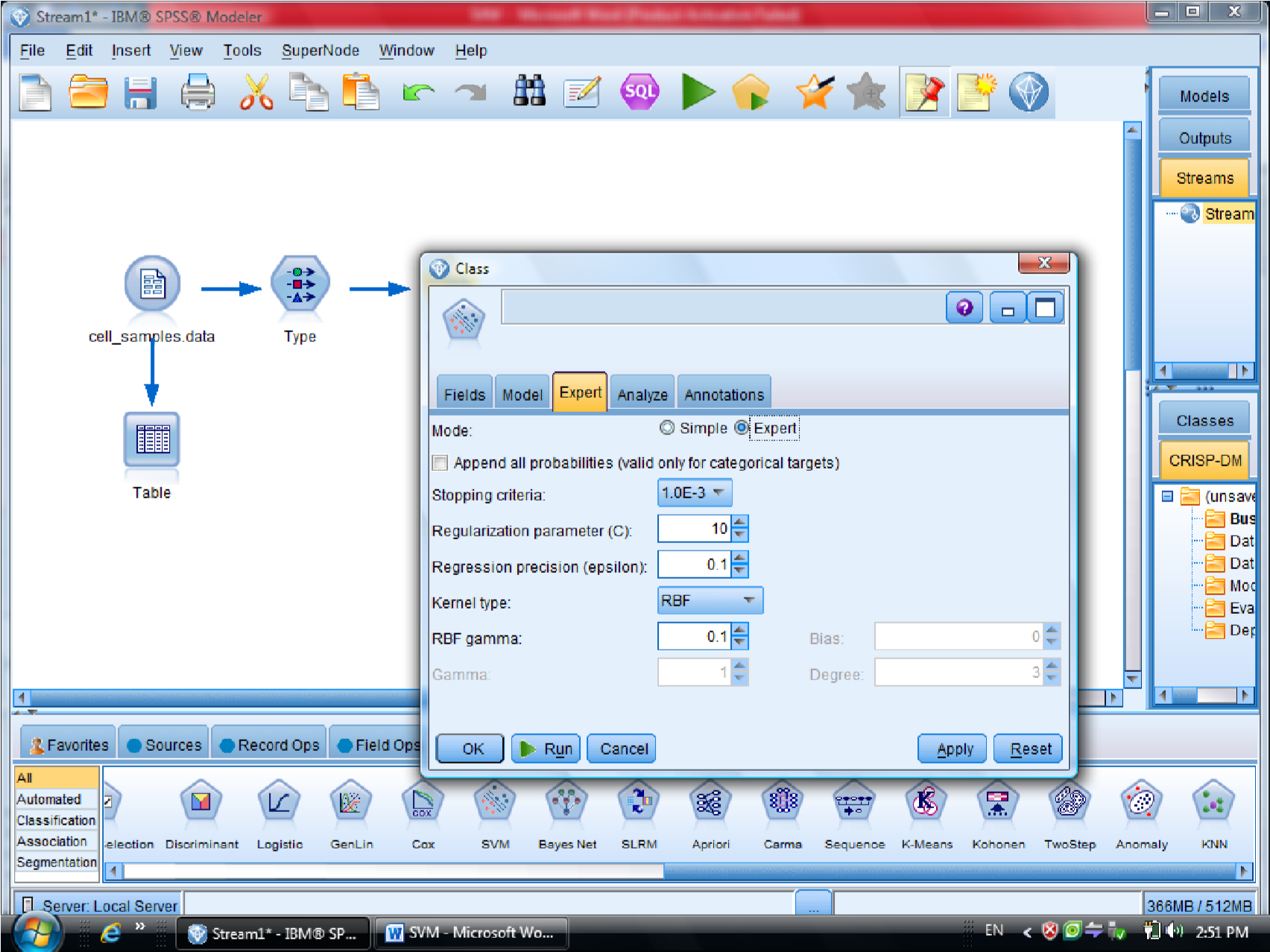
گزینه Expert در متد SVM دو گزینه sample , Expert را داریم
که ما از گزینه Expert استفاده می کنیم برای اینکه بتوانیم چند روش برای دسته بندی داده
استفاده کنیم
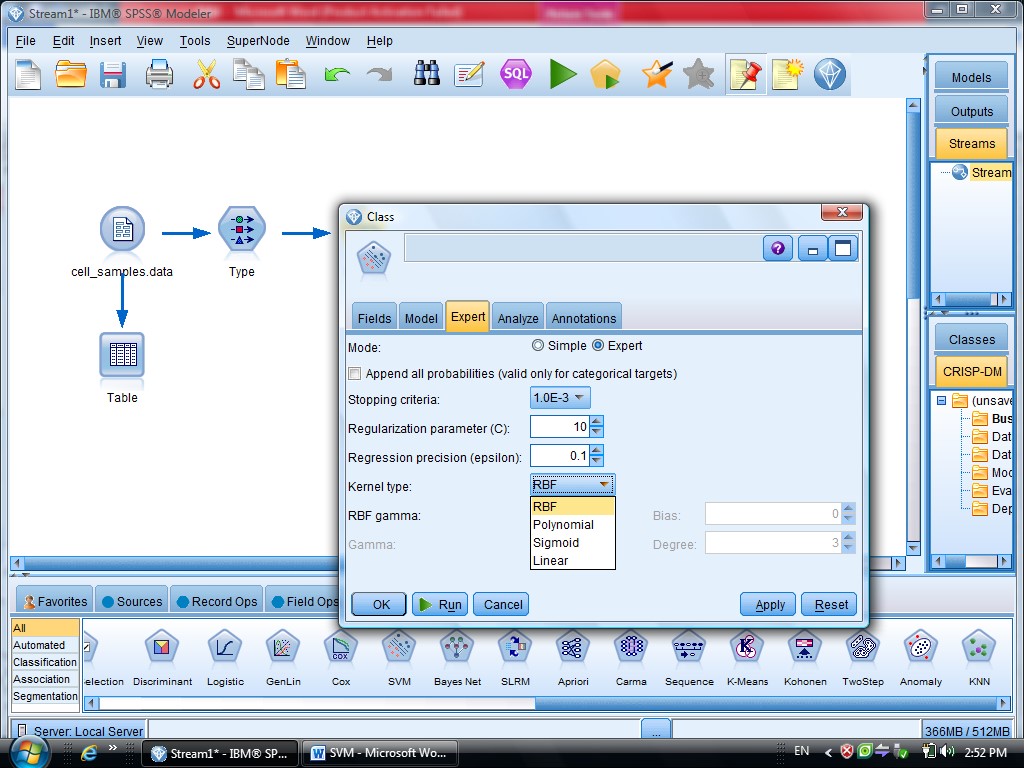
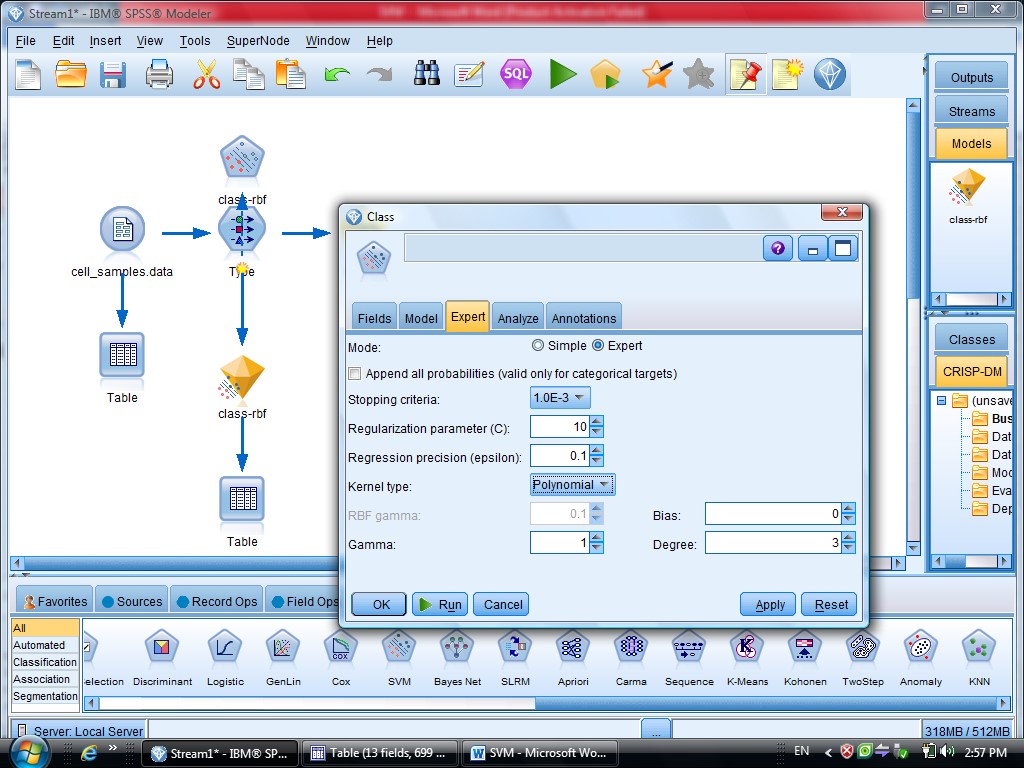
در SVM از تابع Kernel استفاده می شود
درجه وابستگی متغیر ها را می توانیم با SVM مشخص کنیم
گزینه Model مربوط به مدل آیا دیتا های ما از چند قسمت تشکیل شده اند یا خیر
کرکره Expert دو گزینه دارد (Simple , Expert)
یاد آوری می شود روش های SVM از تابع کرنل هست
ممکنه روشهای مختلفی استفاده کنیم
با انتخاب گزینه Expert می توانید از توابع Kernel استفاده کنیم
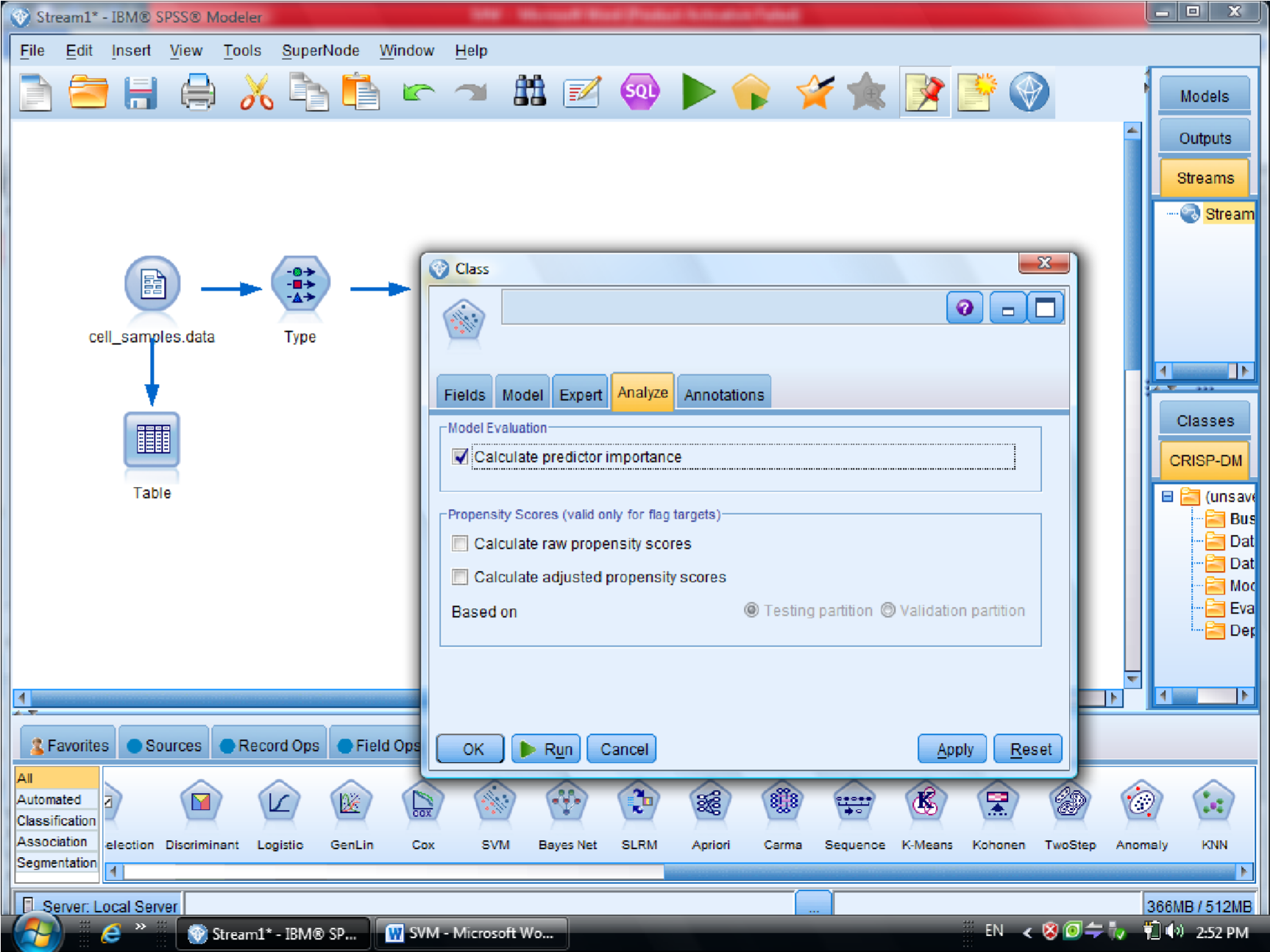
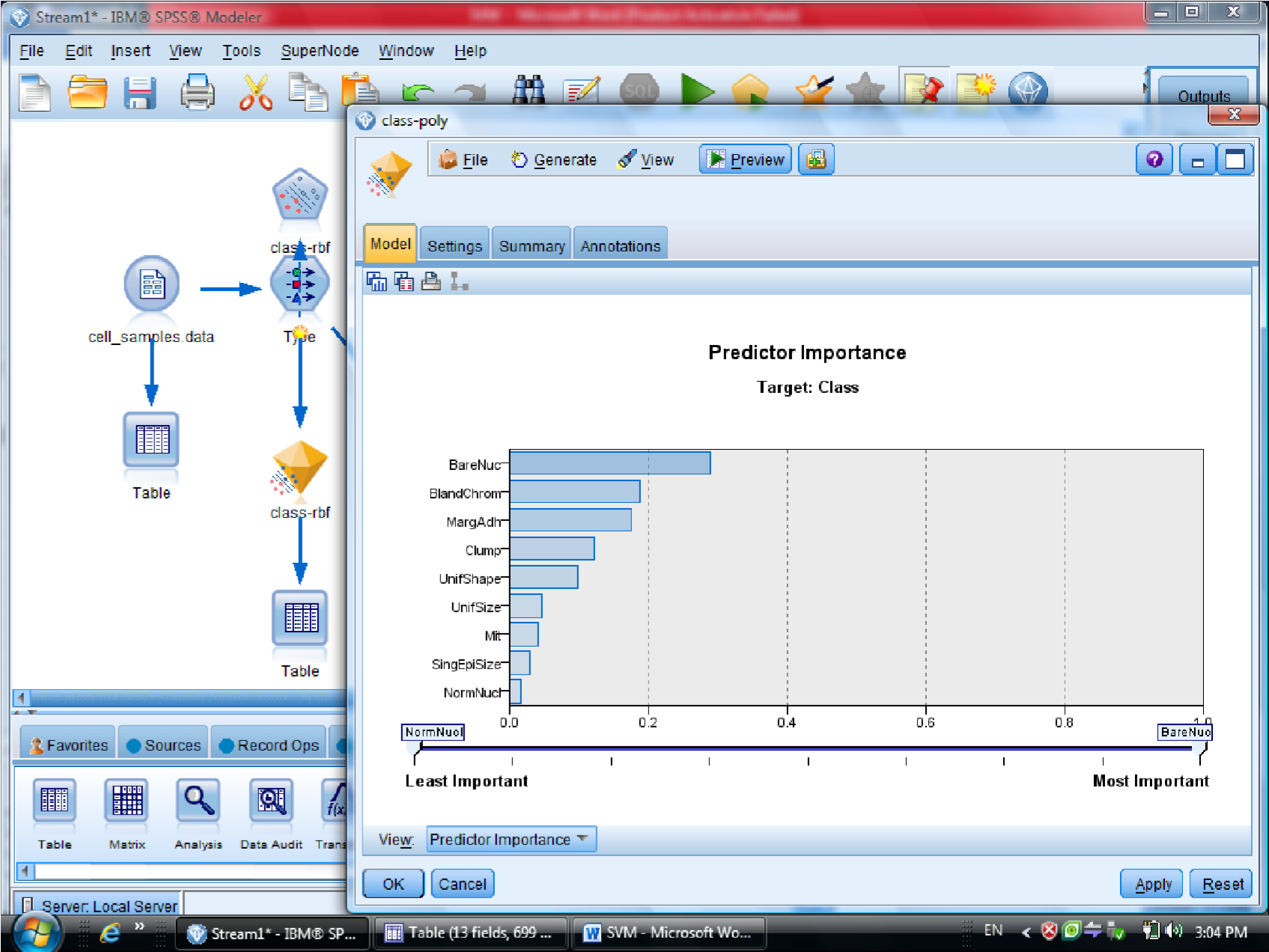
در قسمت اول متغیر ها را بر اساس درجه اهمیت نشان می دهد
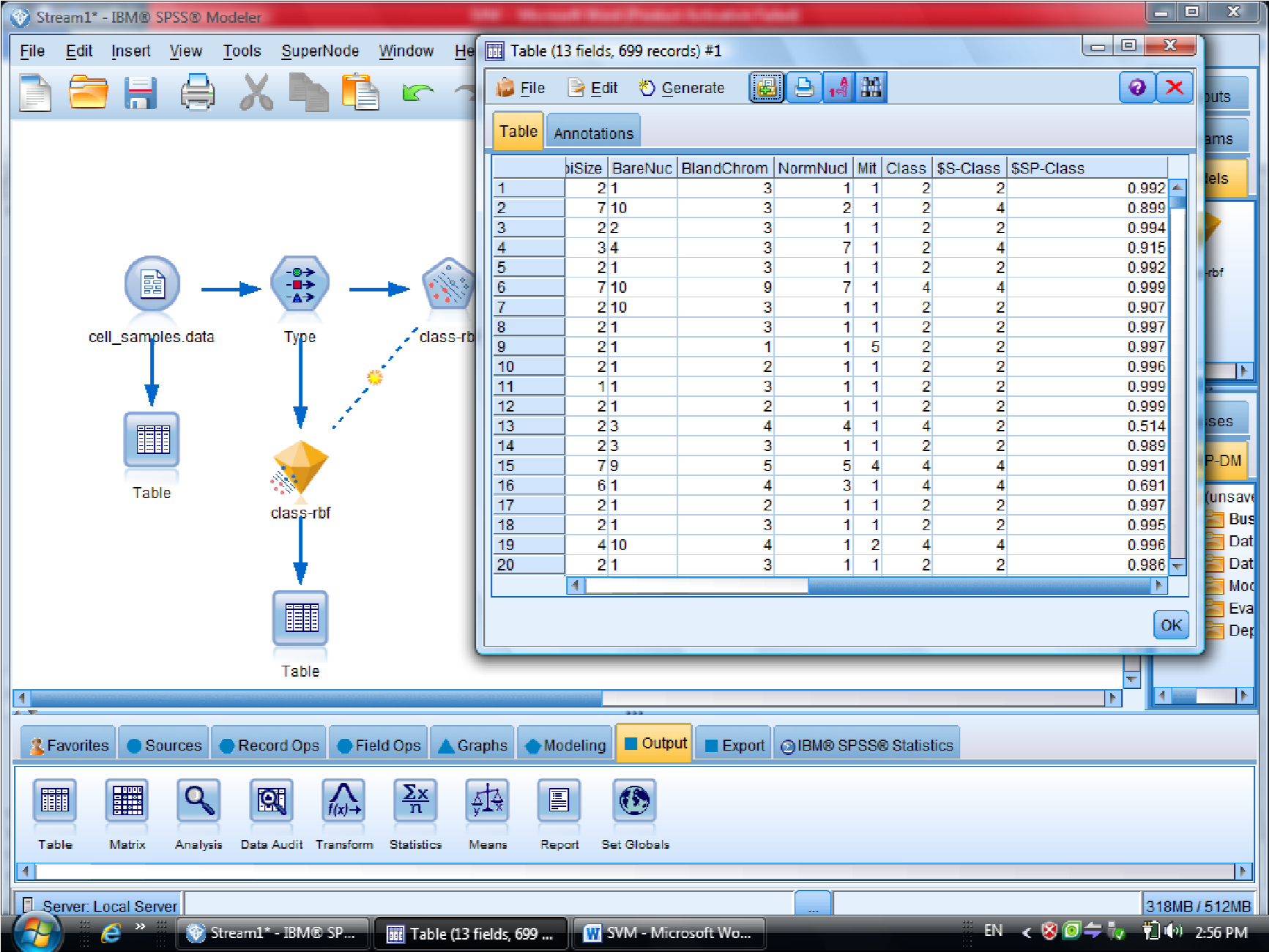
احتمال برای درست پیش بینی شدن را می دهد
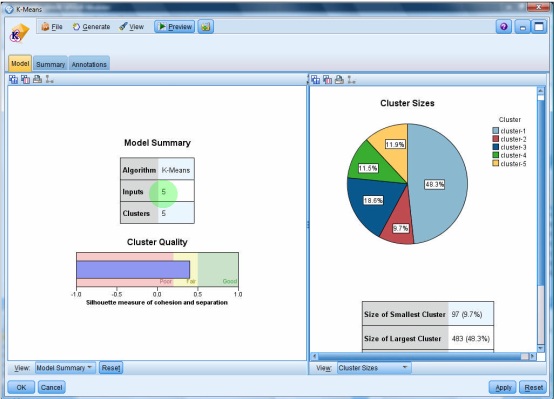
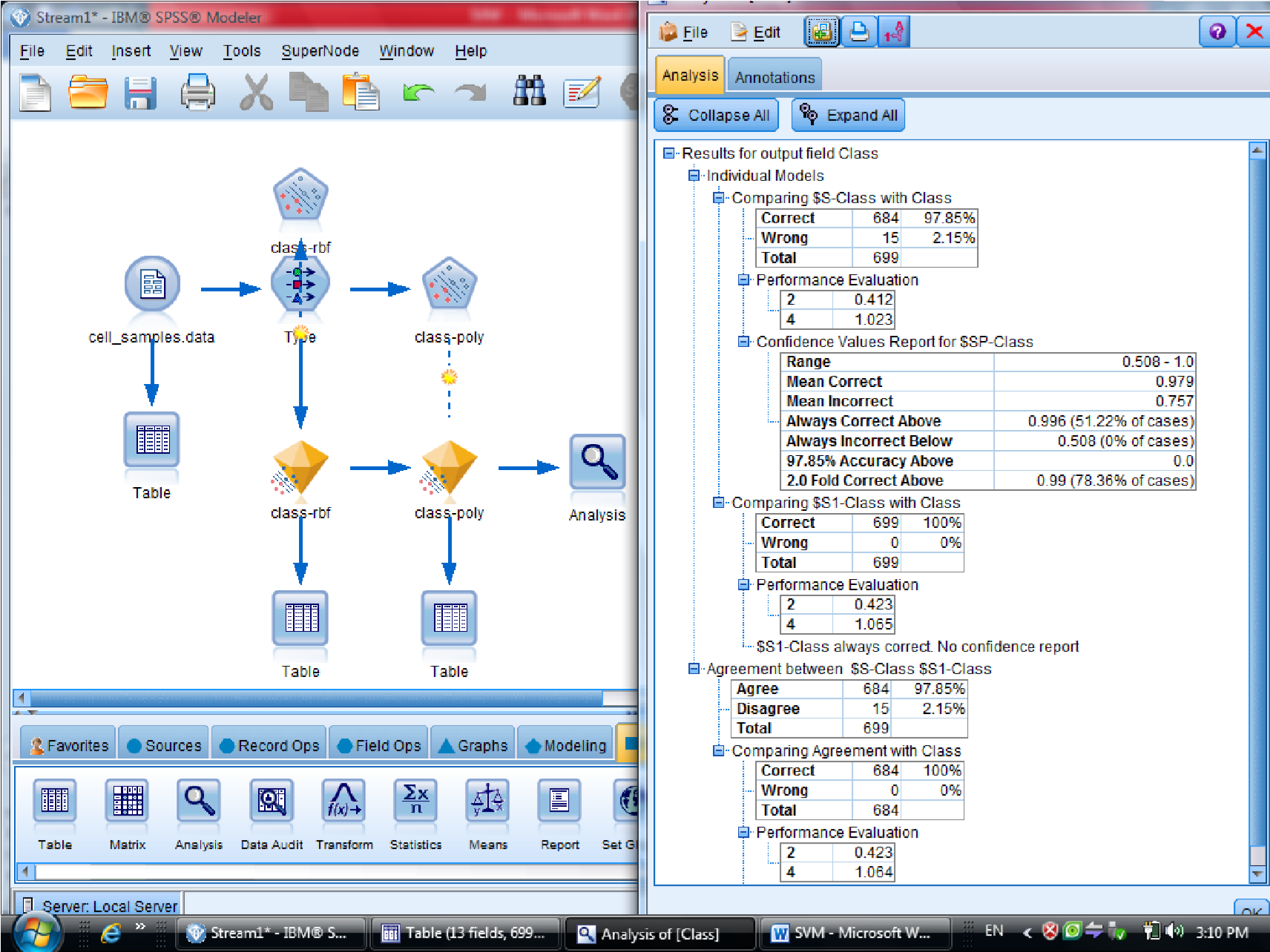
یکبار به روش RBF خروجی گرفتیم
این مقدار احتمال ها ممکن است خیلی به ۱ نزدیک باشد
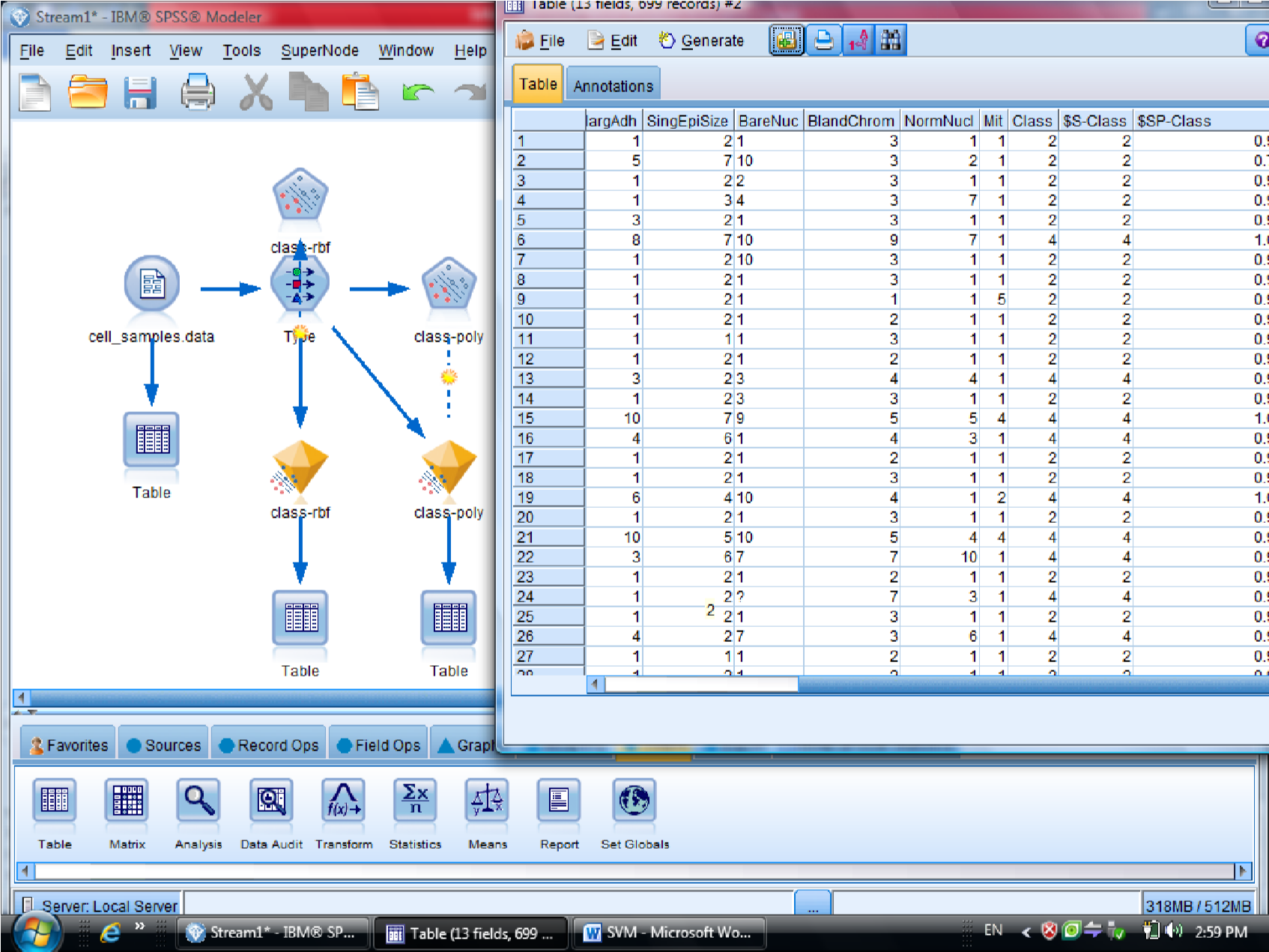
به روش Polynomial (چند جمله ای )، خروجی مربوطه برای متغیر هایی که این فرم را دارند
میزان دقت polynomial صد در صد هست
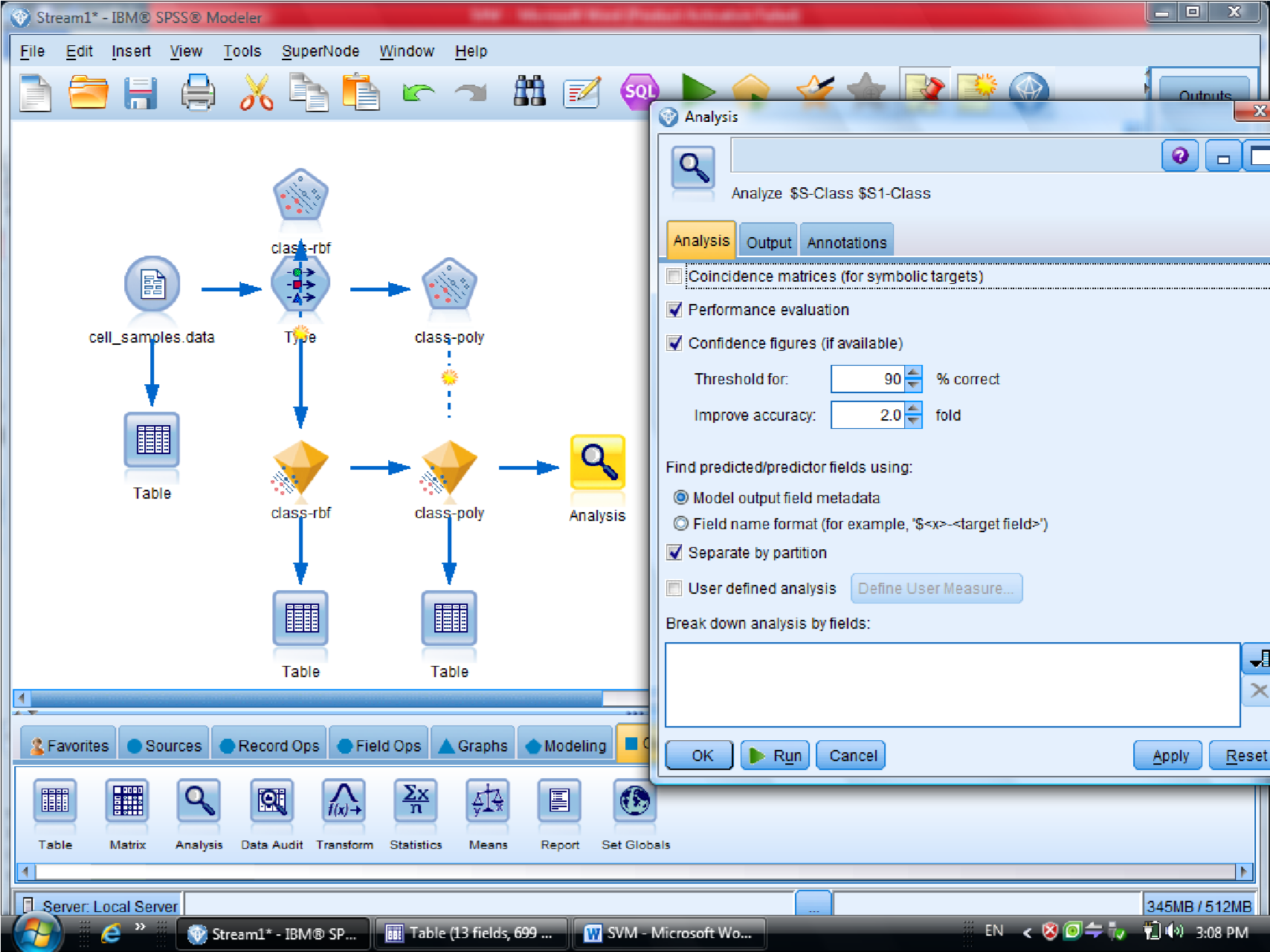
برای مقایسه دو نتیجه دو تا الماس زرد را با هم مرتبط می کنیم ( با F2 )
و به Analysis وصل می کنیم تا مقایسه این دو نود را ببینیم
در نهایت متدی که به ۱۰۰ نزدیک تر هست ، روش مناسب تری هست
درصد دیتاهایی که درست تشخصی داده را ۰٫۹۷۹ هست
سلول های سرطانی خوشخیم که با ۲ علامت گذاری شده هست ، با احتمال اشتباه بیشتری
هست
در روش دوم ( polynomial ) میزان دقت سلول سرطانی ۱۰۰% هست
ولی برای سلول های سرطانی خوشخیم درجه احتمال بیشتری را خواهد داشت
پس بین این دو روش polynomial بهتر است
این مثال در فصل هشتم داده کاوی و کشف دانش گام به گام با Clementine خانم علیزاده هست
fine
داده کاوی و کشف دانش گام ب گام با نرم افزار Clementine علیزاده د.خواجه نصیر
یکی از روشهای مورد استفاده از متد های شبکه عصبی در داده کاوی هست
مثلا رگرسیون ارتباط متغیر های وابسته به متغیر های مستقل نشان می دهد
مثلا شرکت ها چقدر بدهی داشته باشند
سوالات :
سوال اول تعریفی است
مثلا desicion Tree
الگوریتم هایی که استفاده می کنید
درجه اطمینان و میزان پشتیبانی
روشهای خوشه بندی – kmeans خوشه بندی کنید
با Complete Linckage یا Average Linkage
آزمون تمام مطالب سر کلاس هست
 Continue reading »
Continue reading »