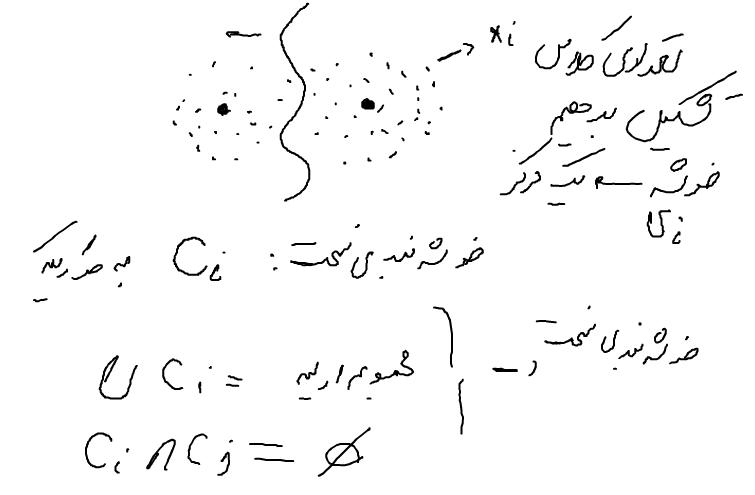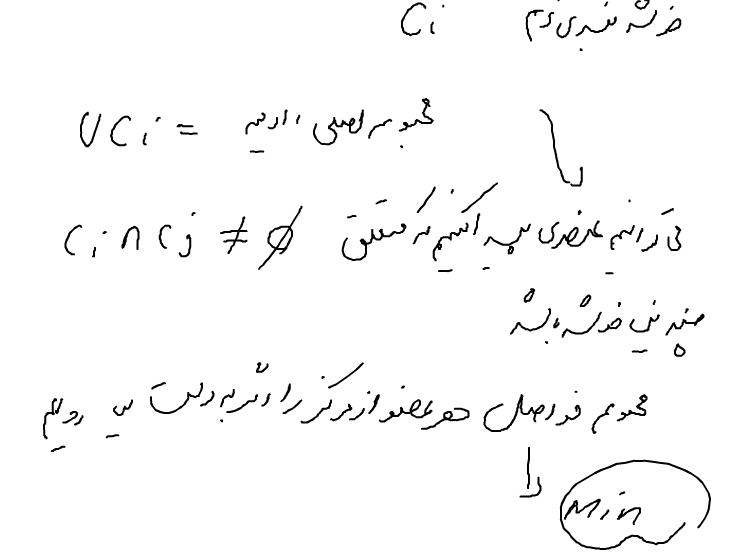May 312014
درخت تصمیم
FCL
خوشه بندی فازی
با استفاده از روال های آموزشی یک سری قوانین را تشخیص می دهند
ژنتیک و شبکه عصبی درابتدا باید در یک بازه آموزشی Learn شوند و if then rule ها را بسازند
درخت تصمیم : فرض کنیم ماشینی طراحی کردیم که می خواهد سیب ها را از پرتقال ها
جدا کند بر اساس ۴ مشخصه ( قند – رنگ – سفتی – وزن چگالی)
از این چهار خصوصیت ، دو خصوصیت برتر را مشخص می کنیم ( بهره اطلاعاتی )
مثلا خصوصیت سفتی بهره اطلاعاتی بیشتری دارد
سپس خصوصیتی که بهره اطلاعاتی بعدی را دارد شاخه های بعدی را تشکیل می دهند
بر این اساس درخت ایجاد شده بدست می آید
حالا بر اساس برگ های درخت Rule ها ایجاد شده اند
احتمال درست بودن هریک از برگ ها به صورت فازی مشخص می شوند
حالا که بر اساس داده های Train درخت تصمیم را ساختیم
مرحله بعدی داده های Test را به آن می دهیم
ممکن است بعضی از اطلاعات به صورت Crisp باشد و برخی دیگر به صورت Fuzzy
– اگر تعداد خصوصیت ها زیاد باشد درخت تصمیم خیلی بزرگ می شود
از تکنیک های هرس باید استفاده کنیم
و یا راهکار feature Selection استفاده می کنیم
—————-
برای تمرین یک سری داده بیاورد که از روی آن درخت تصمیم بسازیم
—————–
انواع درخت های تصمیم خیلی زیاد هستند ( C4 , C5 , Kart, ID3
در اینجا از درخت تصمیم نوع FID3 استفاده می کنیم
هرخصوصیت را A1 تا An می گیریم
هر خصوصیت می تواند چند تا مقدار داشته باشد A1mو A2m و A3m
بهره اطلاعاتی با از A1 تا An می سنجیم (می توان با استفاده از آنتروپی شانون بهره اطلاعاتی را سنجید)
و همچنین با روش زیر : کاردینالیتی مجموعه های فازی – که کل مقادیر تعلق را با هم جمع می کنیم )
به ازای هر کلاس Ti را تعریف می کنیم که به آن می گوییم اطلاعات ترکیبی تکمیلی
Cardinality
بهره اطلاعاتی : میزان اطلاعاتی که با توجه به آن خصوصیت بدست می آید
در این جدول مثال ۴ خصوصیت داریم که
برای A1 سه حالت داریم
برای A2 سه حالت داریم
برای A3 دو حالت داریم
و برای A4 دو حالت داریم
برای خروجی B1 هم سه حالت داریم
در این جدول مثلا ۱۰۰۰ رکورد اطلاعات داریم که با ۳۰۰ تای آن درخت تصمیم را می سازیم ( شکل می دهیم ) و با ۴۰۰ تای آن تست می کنیم
ابتدا ریشه درخت را بر اساس خصوصیتی که بهره اطلاعاتی بیشتری دارد می سازیم
پس در اولین مرتبه بهره اطلاعاتی I(B|A1) و I(B|A2) و I(B|A3) و I(B|A4) را محاسبه می کنیم
ماکزیمم آن ها را به عنوان ریشه درخت در نظر میگیریم
هرس :
می توانیم شاخه های درخت را هرس کنیم
معیار هرس : اگر درصد یکی از کلاس ها یک مقداری کمتری بود( minimum support ) دیگر آن شاخه را ادامه نمی دهیم
اگر بدون هرس کردن بخواهیم درخت تصمیم را بسازیم خیلی بزرگ می شود
هر چقدر بخواهیم دقیق تر باشد بتا را بیشتر می کنیم
اگر فرکانسی جواب با f نمایش می دهیم کمتر از ۰/۲۵ باشد ادامه نمی دهیم
گفتیم که به ازای تک تک برگ های درخت تصمیم قانون بوجود می آید
در این درخت مثال ۲۷ قانون بدست آوردیم
شیوه بدست آوردن Bi را اینجا آورده شده است
خلاصه درس پایگاه داده پیشرفته – دکتر شیری ۹۳/۰۲/۲۹
انواع بن بست
بن بست حالتی است که دو یا بیش از دو تراکنش هر کدام منتظر پایان دیگریست
دو راه حل برای بن بست وجود دارد
۱- روشهای کشف بن بست
۲- روشهای جلوگیری از بن بست
روشها اغلب بد بینانه هستند و فرض می کنند اغلب بن بست پیش می آید و سعی می کنند از وقوع بن بست جلوگیری کنند.
استفاده از نظم خاص با استفاده از مهر زمانی
استفاده از الگوریتم عدم انتظار و انتظار محتاطانه
داده های مورد نیاز خود را قفل می کنند و عملیات را روی داده ها انجام میدهند تا مشکلی ایجاد نشود
۲- استفاده از مهر زمانی برای حل مشکل بن بست
مهر زمانی مقدار منحصر به فردی است که سیستم برای هر تراکنش در نظر می گیرد که می تواند ترکیبی از ID و زمان شروع تراکنش باشد
هر زمانی تراکنش Ti را با Ts(Ti) نشان می دهیم
دو الگوریتم در این رابطه مطرح می کنیم
۱- الگوریتم منتظر گذاشتن و پس راندن :
اگر Ts(Ti)<Ts(Tj) و Ti خواهان قفل کردن داده ای Tj ۀنرا قفل کرده و منتظر می ماند که کار Tj تمام شود . در غیر اینصورت طرد می شود
۲- الگوریتم زخمی کردن و منتظر گذاشتن :
اگر Ts(Ti)<Ts(Tj) و Ti خواهان قفل کردن داده ای است که Tj قفل کرده ، Ti زخمی می شود ( طرد می شود ) و داده از آن گرفته می شود و در اختیار Ti قرار می گیرد . در غیر اینصورت باید منتظر بماند
۳- عدم انتظار :
اگر ترامنشی ، داده مورد نیاز خود را نتواند قفل کند ، بدون درنگ ( بدون انتظار ) طرد می شود
۴- انتظار محتاطانه :
اگر تراکنش Ti خواهان قفل کردن داده ای است که Tj آنرا قفل کرده اگر Tj خود منتظر باز شده قفلی داده ای نباشد Ti منتظر می ماند ، در غیر اینصورت طرد می شود
————————————–
روشهای کشف مشکل بن بست
این روش های خوشبینانه هستند
فرض می کنند بن بست به ندرت رخ میدهد و اجازه می دهند تراکنش ها آزادانه اعمال خود را انجام دهند و اگر احساس کردند که لن بست رخ داده آنرا کشف و برطرف می کنند
۱- مهلت زمانی :
سیستم یک مهلت زمانی تعیین می کند و اگر تراکنش نتوانست در این مهلت زمانی به داده مورد نظر خود را قفل کند ، طرد می شود
۲- بررسی متناوب درخواست های قفل گذاری
در این روش سیستم به منظور کشف بن بست به طور متناوب درخواستهای قفل گذاری تراکنش ها را بررسی می کند
این کار را با رسم گراف انتظار انجام میدهد
گراف انتظار یک گراف جهت دار است که رئوس آن تراکنش ها هستند و یال جهت دار Ti–>Tj در این گراف وجود دارد .
اگر Ti خواهان قفل داده ای باشد که Tj قفل کرده باشد
اگر در این سیکل یا دور وجود داشته باشد یعنی بن بست رخ داده و سیستم باید بن بست را رفع کند (با طرد بعضی از تراکنش ها )
——————————-
سیاست های مختلفی برای طرد تراکنش هست
– تراکنشی که کمترین کار را انجام داده، طرد شود
– تراکنشی که زمان بیشتری تا پایان آن مانده، طرد شود
– تراکنشی که باعت loop شده
– تراکنشی که بیشترین داده را قفل کرده
——————
روش مهر زمانی
برای کنترل همروندی
در این روش غیر از مهر زمانی تراکنش ها که با Ts (T) نشان میدهیم برای هر فقره داده مانند D دو نوع مهر زمانی داریم
مهر زمانی خواندن Ts-r (D) که برابر است با بزرگترین مهر زمانی تراکنش ها مه داده D را خواندن
مهر زمانی نوشتن : Ts-W(D) برابر است با بزرگترین مهر زمانی که تراکنش هایی که داده D را تغییر داده یا نوشته
پروتکل To
۱- در عمل خواندن ، تراکنش Ti دستور R(D) صادر می کند آنگاه
الف ) اگر زمان مهر این تراکنش کوچکتز ار زمان مهر نوشتن داده D بود
Ts(Ti)>Ts-W(D) درخواست رد می شود و تراکنش طرد می شود
ب) در غیر اینصورت درخواست به سایت می شود
Ts-R(D)=Max{Ts-R(D),Ts(Ti){
۲- در عمل نوشتن ترانش Ti دستور W(D) را صادر می کند
در این حالت
الف ) Ts(Ti)<Ts-RD) درخواست رد می شود و تراکنش طرد می شود
ب) اگر Ts(Ti)<Ts-W(D) درخواست رد می شود و تراکنش طرد می شود چون نتیجه از دست رفته رخ میدند
ج) در غیر اینصورت درخواست اجابت می شود و قرار میدهیم
Ts-W(D)=Max {Ts-W(D), Ts(Ti)}
کتاب روحانی رانکوهی جلد دوم سیستم های مدیریت پایگاه داده ، یا حق جو – جلد دوم ، یا دیت – جلد دوم را بخوانید
سوال در این روش کدام یک از مشکلاتی ک مطرح شد رخ می دهد
۱- تضعیف همروندی
۲- طرد تسلسلی
۳- مشکل بن بست
۴- مشکل گرسنگی یا قحطی زدگی
۵- آیا این روش همروندی را تضمین می کند ؟
پروتکل مهر زمانی نوع دوم برای همروندی
یک زمان مهر ساختگی برای تراکنش با کمی اختلاف ایجاد کنیم
در اینصورت ممکن است خیلی از طرد شدن ها برطرف شود مشکل این اختلاف چقدر بگیریم
پروتکل مهر زمانی شدید برای همروندی
در عمل نوشتن دیدیم که اگر Ts(Ti)>Ts-R(D) عمل توشتن اجرا می شود
در این پروتکل این اجازه را وقتی می دهد که تراکنش داده را خوانده به ترتیب برسد
خلاصه درس مبانی محاسبات نرم – ۹۳/۰۲/۲۷
فصل۱۱ :
Fusion of Fuzzy system
نرون های تک یاخته ای
ارتباط بین نرون ها شکل های مختلفی را تشکیل میدهد
رفتار تابعی داخل نرون ها قابل بررسی هستند
خروجی های شبکه عصبی می توانند با خروجی قابل انتظار برابر باشد
شبکه عصبی MLP Multilayer Percpetron
شبکه های عصبی می تواند تمام الگو ها را شناسایی کند
اسلاید ۱۳ Convergence problem
اسلاید ۱۴ و ۱۵
امکان پیاده سازی شبکه های عصبی با متلب
اسلاید ۱۸ :
ارتباط شبکه عصبی با منطق فازی
– شبکه عصبی امکان یادگیری دارد ولی منطق فازی امکان یادگیری ندارد
– با استفاده از شبکه عصبی یک سری ار دانش هایی که کامل مشخص
نیست امکان represent را به ما می دهد
شبکه های عصبی شکل لغت های زبانی می توانند به خودشان بگیرند
شبکه های فازی امکان یادگیری را ندارد
Fuzzy Network= Fusion
۱) یک فازی سیستم را با مجموعه شبکه عصبی supervised ترکیب
می کنیم
۲) شبکه های عصبی را با استفاده از فازی می سازیم
۳)درجه عضویت های فازی را می توانیم با شبکه های عصبی شناسایی کنیم
۴) فازی سیستم ها را می توانیم پشت سر هم بیاوریم
—————————————————-
Neural Fuzzy
معمولا ترکیبی از خصوصیات شبکه عصبی و فازی سیستم است
یک سری نود نیاز داریم که زبان فازی را بتوانند ترجمه کنند
پس input variable ها را به صورت شبکه عصبی تعریف می کنیم
linguestic term ها را به عنوان ورودی داریم
اسلاید ۲۴ :
در لایه L1 نرون های شبکه عصبی را داریم
اسلاید ۲۵ : پیک سیستم neural Fuzzy معروف در لایه اول همه
Acivation ها خطی هست
و در لایه دوم lingustic term داریم
در لایه سوم – درباره مقدم ها کار می کنیم ، از قوانینی که برای یکپارچه
سازی قوانین فازی داشتیم استفاده می کنیم
در این حالت وزن های سیناپسی بین مرحله دوم و سوم را مقایسه می
توانیم بکنیم
در لایه چهارم – بخش تالی با توجه به ورودی های فازی ، خروجی را می
توانیم
در لایه پنجم هم می توانیم defuzzification انجام دهیم
————————-
آموزش درشبکه های neuro fuzzy
با استفاده از ابزار های مختلف ، فرم خطا را محاسبه می کنیم
تفاوت بین مرکز ها و تفاوت بین پهنه چپ
نوع اول : اگر بتوانیم به صورت حقیقی مقدار استفاده کنیم ارتوابع خطی
می توانیم استفاده کنیم
نوع دوم : تشخیص توپولوژی های شبکه عصبی که با منطق فازی پیاده
سازی می کنیم ( مثلا چند تا نرون لازم داریم )
اسلاید ۳۴ : شبکه عصبی های در هم تنیده داریم
fuzzy classifier های مناسب کدام هستند ؟
fuzzy rule ها
.
.
.
اسلاید ۳۷ :
مجموعه دیتای تست
سومین نوع :
شبکه هایی که بتوانین membership function را خوب تعریف کنیم
گام اساسی :
دلتا ها با توجه به خصوصیت فازی بودن آنها تقسیم بندی آنها هم فازی
هست
در هر بخش یک شبکه عصبی به کار برده می شود تا بتواند rule های آن
بخش را داشته باشد
یک شبکه عصبی ۳ لایه می تواند تمام neural fuzzy ها را پیاده سازی
کند
——————–
اسلاید ۴۷ :
آخرین نوع Fusion با استفاده از شبکه عصبی ، سیستم فازی را ارزیابی
کنیم
structure of the emulator
خلاصه درس پایگاه داده پیشرفته – دکتر شیری ۹۳/۰۲/۲۲
۲pl قفل گذاری دو مرحله ای
تضعیف همروندی : کند شدن همروندی
طرد تسلسلی
مشکل بن بست : دو یا چند تراکنش منتظر پایان یافتن تراکنش دیگری است
قحطی زدگی ( گرسنگی )
۲pl محافظه کار
صفحه ۱۰ – قفل های انحصاری
————————–
۲pl جسورانه :
قفل کردن داده ها را در لحظه نیاز انجام می دهد
تضعیف همروندی نداریم
طرد تسلسلی داریم
بن بست هم داریم
قحطی زدگی هم دچار می شود
————————–
۲pl دقیق
قفل گشایی کلیه قفل ها هم انحصاری و هم اشتراکی را در لحظه پایانی انجام می دهد
تضعیف همروندی +
طرد تسلسلی –
بن بست +
قحطی زدگی +
————————–
کلاس جبرانی : چهارشنبه کلاس حضوری ساعت ۳:۳۰ تا ۵:۳۰
———————-
همروندی – قسمت دوم
مشکل بن بست در ۲pl ها پیش می آمد
پیش بینی و اجتناب
روش خوشبینانه
—————–
برای هر تراکنش به مهر زمانی اختصاص می دهیم time stamp
مهر زمانی می تواند ترکیبی از چند چیز باشد
۱- ID تراکنش
۲- زمان شروع تراکنش
….
بنابراین هر time stamp منحصر به فرد است
بر اساس این مهر زمانی می توانیم نظمی ایجاد کنیم که بر اساس این نظم تراکنش ها همل کنند تا مشکل بن بست رخ ندهد
FLC
– ورودی ها defuzzification interface
– خروجی ها
قوانین کنترلی
—————
اینترفیس فازی گشایی
– Mean of Maximum Method ( MOM)
– Center of Area Method (COA) ترکیب درجه عضویت ها
مساحت محصور بین …
– Bisector of Area ( BOA)
اگر هردو مساحت سفید و مشکی برابر باشد z0 مساوی می شود
برخی زمان ها ممکن است به صورت زمان پرتی سیستم باشد
که از lookup table ها استفاده می کنیم
control Variable ها در یک ستون جدول و input Variable
ها در ستون دیگر می گذاریم
طراحی پروسیژر فازی کنترل های منطقی FLC
۱- determination of state variables and Control
Variables
۲- determination of interface method
۳- روش های مختلفی را می توانیم پیاده سازی کنیم
۴- گسسته سازی و یا پیوسته سازی بهتر است ؟
۵- بخش بندی فضای متغیر ها
۶- شکل توابع فازی ، نوع اعداد فازی مهم هستند
۷- روی پایگاه دانش چه قوانینی را پیاده سازی کرده ایم
۸- استراتژی های مختلفی را می توانیم مشخص کنیم
۹ – با هر سیستم کنترلی احتیاج به تست دارد
۱۰- ساخت lookup table از خروجی های متغیرهای کنترل
Fuzzy Expert Systems
می تواند دانش بشری را در غالب فازی به خدمت بگیرد
Knowledge Base
Input interface
output Interface
ماژول Schaduler – بر اساس ارتباظ
تفاوت FLC با FXS
فازی کنترل ها به زبان سیستم ها نزدیکند
fuzzy expert system به زبان انسان نزدیکند و کنترل مرکزی
داریم
اسلاید ۲۸ :
تشابه FLC با FXS
در هر دو
موتور استنتاج
پایگاه دانش وجود دارد….
Interface Engine ( Decision Making Logic )
در حوزه اسنتتاج تمرکز بر این است که بتوانند در حوزه ورودی ها
بتوانند ارزیابی کنند و بهترین تصمیم را اتخاذ کنند
اسلاید ۳۱ :
Linguistic Approximation
اسلاید ۳۲:
Scheduler
مدیریت و کنترل همه فرایند ها را انجام میدهد
تعداد بسیار زیادی ممکن است rule داشته باشیم که هر کدام در جایگاه خودشان اهمیت پیدا می کند که این کار Scheduler است
پروژه خودتان را بر اساس fuzzy expert system معرفی کنید
خلاصه درس تدریس یار مبانی محاسبات نرم – دکتر رییسی
خوشه بندی با استفاده از سیستم فازی
هر خوشه یک مرکز دارد که با Mi نشان می دهیم
تفاوت خوشه بندی نرم با خوشه بندی سخت
[image 1 , 2]
داده ای مثل Xi با خوشه ای مثل Ci داریم
در خوشه بندی سخت : اشتراک بین خوشه ها برابر تهی است
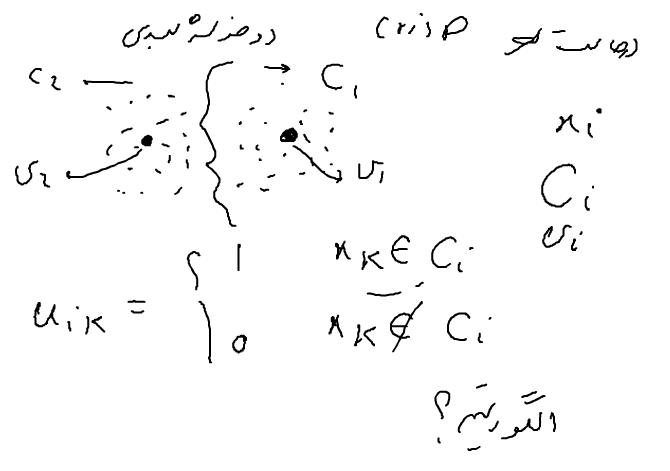
الگوریتم خوشه بندی :
معروفترین الگوریتم در حالت کریسپ k-means است
مرحله اول به هر داده یک خوشه را نسبت می دهیم ( به صورت رندوم )
برای هر خوشه با استفاده ار فرمول زیر مرکز را محاسبه می کنیم

میانگین داده ها را به عنوان مرکز خوشه معرفی می کنیم
در k-means از ابتدا باید تعداد خوشه ها مشخص باشد
در C1 داده های مشخصی عضو می شوند و مرکز C1 هم مشخص می
شود
داده های C2 هم مشخص هستند و مرکز C2 هم مشخص می شود
با توجه به مراکز جدید داده ها را مجددا خوشه بندی می کنیم
تا جایی که داده ها در خوشه ها ثابت شوند و دیگر تغییری در خوشه ها
نداشته باشیم
ولی می دانیم که همیشه داده ها ممکن است به یک خوشه تعلق
نداشته باشند و درصدی به خوشه دیگری هم تعلق داشته باشد
که این درجه عضویت مفهوم فازی را تداعی می کند.
FCM : Fuzzy Clustering Method
[img 6]
روی چه چیزی قید بگذاریم ؟
هدف کلی از کلاسترینگ : فاصله بین داده های تا مرکز خوشه مینیمم
باشد ( یعنی norm 2 )
و فاصله بین خوشه های مختلف ماکزیمم باشد
هر چه m در فرمول بزرگتر شود از حالت فازی فاصله می گیریم و
خوشه بندی ها به سمت کریسپ میل می کند
قید داریم که مجموع درجه عضویت ها برای هر داده به خوشه های
مختلف برابر ۱ است
قبل از پردازش خوشه بندی نیاز است که داده های پرت را دریک پیش
پردازش حذف کنیم
روش لاگرانژ :
به تعداد داده ها قیدی داریم که ضریب می خورند بنام لاندا k
.
.
.
کنفرانس انجمن کامپیوتر ایران – فردوسی مشهد را شرکت کنید
http://iccke2014.um.ac.ir/index.php
همروندی :
اگر تراکنش ها به صورت متوالی انجام شوند
در سیستم چند کاربره بایستی بصورت همروند انجام شود
که باید کنترل شود
مشکلات همروندی :
۱- نتیجه از دست رفته
۲- خواندن داده ناجور
۳- تحلیل ناسازگار
استفاده از تکنیک قفل کردن
قفل : امتیازی است برای دستیابی به
اندازه واحد داده قفل شدنی باید متفاوت باشد تا تراکنش ها بر اساس
نیازشان داده را قفل کنند
انواع قفل :
۱- قفل دوگانه Binary
۲- قفل چندگانه
هر تراکنش می تواند داده را Lock و یا UnLock کند
نکته : قفل دوگانه بسیار محدود کننده است
قفل چندگانه :
۱- قفل خواندن (اشتراکی) : تراکش ها همزمان می توانند داده ها را
بخوانند
۲- قفل نوشتن (انحصاری ) : برای تغییر یا نوشتن داده لازم است
ایا قفل چند گانه همروندی را تضمین می کند ؟
خیر تضمین نمی کند ، در واقع همان سه مشکلی که مطرح کردیم پیش
می آید
قفل دو مرحله ای پایه :
انواع قفل دو مرحله ای
۱- ۲pl محافظه کار
۲- ۲pl جسورانه ( تا زمانی که به داده نیاز ندارد قفل نمی کند )
ولی ۴ مشکل دیگر مطرح می شود
۱- تضعیف همروندی
۲- بن بست
۳- طرد تسلسلی
۴- گرسنگی یا قحطی زدگی
خلاصه درس مبانی محاسبات نرم ۹۳/۰۲/۱۳
فازی برای سه اصل اساسی تدریس می شود
۱- کنترل های فازی
۲- Expert system ها
۳- DFS تصمیم گیری فازی
———————
Fuzzy Logic Controller(FLC)
یک سری از متغیر ها state هستند که وابسته به شرایط مساله هستند
تمیزی یا کثیفی یک لباس بستگی به چربی و … می شود اظهار نظر کرد
متغیر های یک کنترل مشابه خروجی هست
تابع کنترلر هم با توجه به state ها خروجی مشخص می شود
معمولا با توجه به هدف گذاری
با توجه state ها می توانیم برای متغیر های اظهار نظر کنیم که چه
موقع چه مقادیری را می توانند به خود اختصاص دهند
FLC یک تقلیدی از نحوه تصمیم گیری انسان است
مثال : سود بانکی ، FLC می توانند مشابه افراد تصمیم گیری کنند
appoximatry deciding
در حیطه آموزش
برای مسایلی که برای کنترل آنها قوانین زیادی وجود دارد انسان تواناییش
پایین می آید و می توانیم از تعداد زیادی FLC به صورت AND و
OR شده استفاده کنیم
WHY FLC ?
۱- Parallel or distributed Controlکنترل های توزیع شده
موازی
۲-Linguistic Control
۳- Robust Control
آیا سیستم های فازی درصد خطای زیادی دارند ؟
درصد rubustnes دست خودمان است ، با منطق فازی در هر دو
حوزه بسیار مناسب می توانیم عمل کنیم
fis در تمامی جاهایی که عدم قطعیت داریم استفاده می شود
معماری FLC
[image flc architecture]
خروجی می تواند به صورت غیر فازی باشد که از Fuzzification
interface استفاده می کنیم ( حاشیه چپ و راست اضافه می کنیم
که شکل ذوزنقه ای بشود )
خروجی FLC می تواند به صورت فازی باشد که ممکن است برای
کنترل زیاد مناسب نباشد بنابر این از Defuzzification interface
استفاده می کنیم
یک FLC خوب ، بررسی state های قبلی را داشته باشد
از روی KB بتواند به تصمیمات مقتضی دست پیدا کند
interface های فازی سازی :
می خواهیم اعداد کریسپ را به فازی تبدیل کنیم
باید شناختی روی مساله وجود داشته باشد
پایگاه دانش : مجتمعی است از تمامی قوانین
ممکن است تمامی قوانین قابل ردیابی نباشد
۱- Discretization
۲- Normalization برای سنجش شباهت
۳- Classifier های بخش بندی کننده فازی برای دسته بندی
۴- Membership function of primary fuzzy set
قوانین چون قرار است از انسان آموخته شود بنابراین روش های مختلفی
را می توانیم برای fuzinnes استفاده کنیم
مثال Discetization :
یک سری اعداد داریم از -۲٫۴ تا +۱٫۴ که اندیس گذاری می کنیم
مثال پارتیشن بندی فازی :
در حالتی که classifier های خوبی نداشته باشیم می توانیم از روش
های خبرگانی استفاده کنیم
مثال Membership
کافیست برای اعضا جدول درجه عضویت را تعریف می کنیم
Rule Base
عصاره دانش خبرگانی است که در قالب if then rule در می آید
قوانینی که در پایگاه دانش جمع آوری میشود می تواند به صورت فازی و
یا غیر فازی باشد
خروجی ها هم می تواند مستقل از ورودی ها باشد و یا وابسته به ورودی
ها باشد
مثال اسلاید ۱۷ :
روی محور x قوانین با توجه به ورودی های A1 تا An
و روی محور y قوانین با توجه به ورودی های B1 تا Bn
نکته: ممکن است قوانین متفاوتی داشته باشیم که ورودی ها در آنها
صدق کند
جلسه بعد متد های ممدانی و لارسن و Tksumato و TSK را روی
FLC ها بررسی می کنیم