با سلام،
احتراما پیرو مذاکره با سرکار خانم دکتر مولایی و نگرانی برخی دوستان به استحضار می رساند تمامی ایمیل های ارسالی جهت مشخص کردن موضوع پروژه تا قبل از پایان سال بررسی می گردد.
با احترام
دولت کیا
با سلام،
احتراما پیرو مذاکره با سرکار خانم دکتر مولایی و نگرانی برخی دوستان به استحضار می رساند تمامی ایمیل های ارسالی جهت مشخص کردن موضوع پروژه تا قبل از پایان سال بررسی می گردد.
با احترام
دولت کیا
با سلام،
به دلیل مشکل سایت دانشگاه کلاس مورخ ۲۵-۱۲-۹۲ تشکیل نمی گردد.
الگوریتم CANDIDATE-ELIMINATION را بر روی اطلاعات زیر انجام دهید و فرضیه نهایی را تولید نمایید.
– لطفا جواب تمرین را تا روز شنبه مورخ ۲۴-۱۲-۹۲ به آدرس somayeh.molaei@gmail.com ارسال نمایید.
خلاصه درس مبانی محاسبات نرم – دکتر قطعی – ۹۲/۱۲/۱۷
اسلاید ۱۷ :
سوپریمم
می توانیم روش را توسعه بدهیم
یکی از بهترین تکنیک های بهینه سازی چند معیاره می توانیم را انجام دهیم
در این الگوریتم روی اینترنت تحقیق کنید
اسلاید ۱۸ :
ماکزیمم سازی تابع f
اسلاید ۲۲ :
ماکزیمم سازی روی مجموعه های کریسپ
امکان بهینه بودن نقطه را چک می کند
فضای شدنی هم می توانیم میو D x استفاده کنیم
پس x می خواهیم که امکان شدنی بودن بالا باشد و درجه عضویت یا امکان …
اسلاید ۲۳ :
مثال :
این ایده برای فازی دامین هم می توانیم استفاده کنیم
و ممکن ترین بهینه را
هر چه X به مرکز دایره نزدیک تر باشد ، جواب بهتر است
هر چه از مرکز فاصله بگیریم از هدف دورتر می شویم ( میو کمتر می شود )
اسلاید ۲۵ :
مثال از x0 به بالا
دو تابع مخالف هم هستند
یک نقطه بهینه پیدا می شود که اگر از آن فاصله بگیریم میو Dx یا میو Mx از این دو کمتر می شود
*************** حل مسایل بهینه سازی در حالت عدم قطعیت ***************
اسلاید ۲۶ :
mio Mx در بازه ۰ و pi
و mio در بازه ۰ و pi
یک تک نقطه مشترک داریم
ولی در بازه pi , 2 pi
در نقطه ۲pi هر دو تابع به درجه عضویت ۱ رسیدیند
نقطه بهینه سراسری نقطه ۲pi هست
——————————————
اسلاید ۲۷ :
اگر خود تابع هدف مقدارش فازی باشد
آیا می توانیم از توابع فازی مشتق و انتگرال بگیریم ؟
تعریف انتگرال تابع فازی f :
یک کات را تهیه می کنیم
یک طرف f مثبت را داریم و یک طرف f منفی داریم
به ازای هر کدام از درجه عضویت های آلفا ….
دو انتگرال را با هم جمع می کنیم
این روش منحصر به فرد نیست
به روش های متنوی می توانیم انتگرال بگیریم و بستگی به کاربرد آن دارد
اسلاید ۲۹ :
مثال
کافی است در آلف داده شده ۰٫۷ ببینم کدام یک از توابع در این بازه هستند
تنها f 2 x در این بازه است
که مقدار ۷/۳ را به ما بر می گرداند
اسلاید ۳۰
در آلفا کات ۰٫۴ سه تابع داریم که درجه عضویت آنها بزرگتر مساوی ۰٫۴ هست
که در اینصورت برای تمام توابع انتگرال گیری را انجام می دهیم
————–
پس برای انتگرال گیری هم مشابه مفاهیم ریاضی کلاسیک می توانیم استفاده کنیم
*** ما در حوزه انتگرال گیری با توجه به نیاز ها توابع را تعریف می کنیم ***
به عنوان نمونه :
بر اساس اصل توسیع زاده : یک بازه فازی داده اند ، مینیمم میو A , میو B
به ازای هر Z دلخواه
انتگرال را با استفاده از مفاهیم انتگریال غیر فازی و اصل توسیع زاده
به دو فاز
به ازای Z داده شده میو …
ماکزیمم را انتخاب می کنیم
Fuzzy interval …
اسلاید ۳۲ :
می خواهیم در بازه مقادیر مختلف z 0 و۲و۴و۶ خواهد بود
که با مقادیر مختلف
فعلا دو نوع انتگرال گیری گفتیم
حالت ۱ – : به درجه عضویت خوشان انتگرال می گرفتیم
حالت ۲- حالت مقدار تابع f را به ما دادند که انتگرال آن در بازه فازی را می خواهند
نوع سومی هم می توانیم تعرریف کنیم بر اساس اصل توسیع زاده :
چون مشتق برعکس انتگرال هست می توانیم انتگرال را بگیریم
اسلاید ۳۴ :
مثال :
تابع x^3 مقادیر مختلفی که در مشتق حضور دارند ۳ تا سناریو داریم
اسلاید ۳۵
مثال : دیفرانسیل گیری
از هر کدام از توابع به صورت مستقل مشتق بگیریم
می توانیم روی درجه عضویت های مختلف کار کنیم
اگر مشتق را در نقطه داده شده x0 محاسبه بخواهند کافیست هر کدام از تابع ها را در درجه عضویت خاص محسبه کنیم
صورت تمرین : از روی یک ماتریس رابطه به چه صورت می توان به تعدی بودن ( Transitive ) آن پی برد
و از روی یک ماتریس رابطه مانند R به چه صورت می توان بستار تعدی آنرا ساخت
جواب :
تعریف رابطه تعدی (Transitive )
اگر عضوی با عضو دوم و عضو دوم با سوم و اول با سوم ارتباط داشته باشد
با استفاده از ماتریس :
بستار بازتابی Transitive Closure : کوچکترین رابطه ای هست مثل ‘R که شامل R هست و یک رابطه را کم دارد تا بازتابی شود
حداقل رابطه ای شامل R هست و شامل رابطه اولیه باشد

فصل اول:
اصطلاح پایگاه دادهها یکی از رایجترین اصطلاحات در دانش و فن کامپیوتر است. همچنین خیلی اوقات بجای این واژه از اصطلاح معادل بانک اطلاعات استفاده میشود. بطور خیلی ساده پایگاه داده محلی است برای نگهداری داده و علم پایگاه دادهها کلیه عملیات و مفاهیم مرتبط در این خصوص را شامل میشود. اما سوالی که در همین ابتدا پیش میآید این است که منظور از نگهداری داده چیست؟ بعبارتی نوع این نگهداری یک ذخیره پایدار (مانند فایل) است یا یک ذخیره موقت در حافظه (مانند آرایهها و …)؟ برای پاسخ به این سوال باید بگوییم که سیستم مدیریت بانک اطلاعات همانند سیستم فایل یکی از سیستمهای ذخیره و بازیابی اطلاعات است. سوال دومی که ممکن است برای افرادی که تجربه کار با فایلها را دارند پیش بیاید این است که چه تفاوتی میان فایل و پایگاه داده وجود دارد. در این فصل، ضمن معرفی مفاهیم اولیه تفاوت این دو سیستم را مورد بحث قرار خواهیم داد.
تعاریف اولیه:
سیستم ذخیره و بازیابی اطلاعات:
هر سیستمی که به کاربر عادی یا برنامه نویس امکان دهد تا اطلاعات خود را ذخیره، بازیابی و پردازش کند.
تعریف داده:
تعریف اول- هر مجموعهای از داشته ها (دانستنیها)
تعریف دوم- نمایش ذخیرهشده اشیاء فیزیکی، چیزهای مجرد، داشتهها، رویدادها یا چیزهای قابل مشاهده که در تصمیمسازی بکار میآیند.
تعریف سوم- دانستنیهای خام که معنای اندکی دارند؛ مگر اینکه به صورت منطقی سازماندهی شده باشند.
تعریف چهارم (از دیدگاه ANSI) – نمایش پدیدهها، مفاهیم یا شناختهها به طرزی صوری و مناسب برای برقراری ارتباط، تفسیر یا پردازش توسط انسان یا بطور خودکار
البته تعاریف دیگری هم برای داده ارائه شده است که به همین موارد اکتفا میکنیم.
تعریف اطلاعات (اطلاع)
بطور خیلی ساده اطلاعات، داده پردازششده است. یعنی بر خلاف داده خام، اطلاعات داده سازمان یافتهای است که شناختی را منتقل میکند و برای تصمیمگیری نیز بکار میرود.
تعریف پایگاه دادهها (بانک اطلاعات)
مجموعهای است از دادههای ذخیره شده و پایا، به صورت مجتمع(یکپارچه) (نه لزوما فیزیکی، بلکه حداقل به طور منطقی)، بهم مرتبط، با کمترین افزونگی، تحت مدیریت یک سیستم کنترل متمرکز. پایگاه داده میتواند مورد استفاده یک یا چند کاربر به طور همزمان و اشتراکی قرار گیرد.
تعریف سیستم مدیریت پایگاه دادهها (DBMS)
یک نرمافزار واسط بین محیط فیزیکی ذخیره و بازیابی اطلاعات و محیط منطقی برنامهسازی در سیستم بانک اطلاعات است که هرگونه ارتباط بین کاربر و داده را کاملا کنترل و مدیریت میکند.
DBMS به کاربر امکان میدهد تا پایگاه دادههای خود را تعریف کند، در پایگاه دادههای خود عملیات انجام دهد و روی پایگاه دادههای خود تا حدی کنترل داشته باشد.
پایگاه داده در مقابل فایل
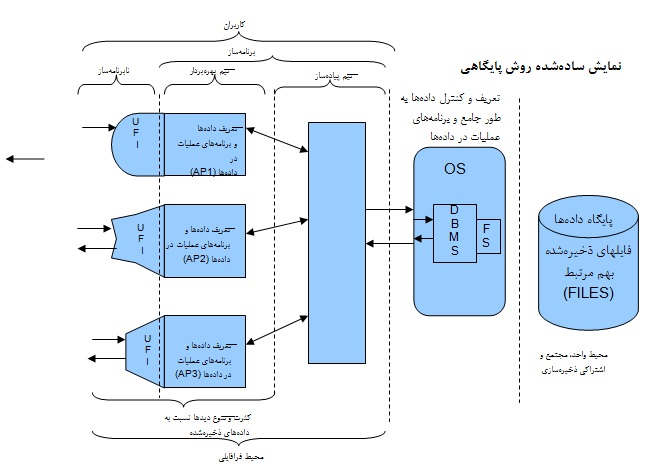
برای ایجاد یک برنامه کاربردی دو روش وجود دارد. روش اول همان روش سنتی یا اصطلاحا فایلینگ است. در این روش، با استفاده از دستورات موجود در یک زبان برنامه نویسی، عملیات ایجاد فایل، خواندن و نوشتن اطلاعات در فایل، حذف فایل و … انجام میشود. در واقع در یک برنامه، ساختاری توسط برنامه نویس تعریف میشود، فایلی با آن ساختار بر روی دیسک ایجاد شده و این فایل جهت عملیات ذخیره و بازیابی اطلاعات مورد استفاده قرار میگیرد. مدیریت و کنترل اجرای عملیات روی فایل برعهده بخشی از سیستم عامل بنام سیستم فایل است. سیستم فایل تنها بخش مدیریتی است که در این روش بر روی عملیات کنترل دارد. اما این کنترل یک کنترل ضعیف است و همچنین محدودیتهایی را برای استفاده همزمان کاربران ایجاد میکند که در ادامه به آنها اشاره خواهیم کرد.
اما روش دوم روش پایگاهی است. در این روش از پایگاه دادهها جهت ذخیره و بازیابی دادهها استفاده میکنیم و عملیات خود را تحت کنترل یک سیستم مدیریتی قدرتمند بنام سیستم مدیریت بانک اطلاعات (DBMS) انجام میدهیم.
سوال مهمی که در اینجا باید به آن پاسخ داد این است که مگر اطلاعاتی که می خواهد بر روی دیسک ذخیره شود در قالب فایل ذخیره نمیشود؟ پس پایگاه داده چه فرقی با فایل دارد؟ پاسخ این است که بله، درست است که هر چیزی که می خواهد ذخیره شود، در نهایت بصورت فایل ذخیره می شود. اما تفاوت اینجاست که در روش فایلینگ ما مستقیما با فایل کار میکنیم و فایل ما دقیقا همان ساختاری را دارد که ما در برنامه تعریف میکنیم. اما در هنگام استفاده از سیستم مدیریت بانک اطلاعات، ما از طریق یک واسط، ساختار دادههای مورد نظر خود را تعریف میکنیم. بعد از آن، این سیستم مدیریت بانک اطلاعات است که داده های ما را پس از نگاشتهای مختلف در فایلهایی ذخیره میکند که استفاده از محتوای آن فایلها فقط از طریق خود DBMS امکان پذیراست.
برای روشنتر شدن بحث، در ادامه مهمترین تفاوتهای این دو نوع سیستم ذخیره و بازیابی را شرح می دهیم.
معایب روش فایلینگ (پرونده ای) نسبت به روش پایگاهی
۱- عدم وجود محیط مجتمع ذخیرهسازی اطلاعات و عدم وجود سیستم یکپارچه
در سیستم فایلینگ، یک ساختار واحد و یکپارچه برای ذخیره تمام فایلهای مورد نیاز وجو ندارد و فایلهایی که تعریف میشوند، بصورت مجزا بر روی دیسک ذخیره میشوند. اما در روش پایگاهی اطلاعات بصورت یکپارچه و مرتبط ذخیره میشوند.
۲- افزونگی داده و عدم وجود سیستم کنترل متمرکز
در روش فایلینگ یک سیستم مدیریتی قدرتمند، متمرکز و یکپارچه برای کنترل عملیات وجود ندارد و تنها مرجع کنترلی بخش سیستم فایل از سیستم عامل است. اما سیستم مدیریت پایگاه داده، یک سیستم مدیریت یکپارچه است که کنترل عملیات بر روی کل دادههای بانک اطلاعات را بعهده دارد. حتی اگر دادهها بر روی یک شبکه توزیع شده باشند.
از آنجا که در روش فایلینگ خیلی اوقات امکان استفاده همزمان چندین کاربر از یک فایل وجود ندارد، در بعضی موارد ناگزیریم که یک فایل مشخص را در چندین محل مختلف (برای چند کاربر) ذخیره کنیم. ذخیره یک داده مشخص در چند جای مختلف (بجای یک محل) اصطلاحا افزونگی نامیده میشود. پدیده افزونگی غیر از مصرف فضای اضافی بر روی دیسک مشکلات مهمتری نیز دارد. مثلا در صورت نیاز به تغییر تغییر بخشی از داده مجبوریم آن تغییر را در تمام جاهایی که آن داده ذخیره شده اعمال کنیم. اما سیستم DBMS امکان استفاده همزمان کاربران متعدد از دادهها را بصورت کاملا کنترل شده فراهم میآورد.
برای مثال، یک نرم افزار اتوماسیون دانشگاه را در نظر بگیرید که شامل قسمتهای مختلف، مانند بخش آموزش، امور مالی و امور رفاهی است. هریک از این بخشها در یکی از قسمتهای دانشگاه توسط توسط کاربر جداگانهای استفاده می شود. واضح است که هریک از این بخشها نیاز دارند به اطلاعات دانشجویان دسترسی داشته باشند. بنابراین اگر از روش فایلینگ استفاده شود، یک فایل برای ذخیره اطلاعات دانشجویان در هریک از این بخشها نیاز است. پس هر بخش فایل اطلاعات دانشجویان را بصورت تکراری و نیز تعدادی فایل مربوط به خود دارد که فایلهای بخشهای مختلف ارتباطی با یکدیگر ندارند و تحت کنترل یک مدیریت واحد نیز قرار نمیگیرند. اما در روش پایگاهی، اطلاعات دانشجو تنها یکبار ذخیره میشود و کل اطلاعات سیستم نیز بصورت یکپارچه و تحت مدیریت کامل DBMS ذخیره می شوند. شکل ۱و۲ ارتباط بین برنامه کاربردی و دادهها را در دو نوع سیستم نشان می دهند.
نوع دیگری از افزونگی از آنجا ناشی میشود که ساختار فایلها از هم مجزا هستند و نمیتوان بین آنها ارتباطی برقرار کرد. بنابراین، اگر در ساختار یک فایل نیاز به بخشی از داده های یک فایل دیگر داشته باشیم، گاهی ناگزیر میشویم آن داده ها را مجددا در این بخش هم داشته باشیم.

۳- عدم وجود ضوابط ایمنی کارا و مطمئن
یکی از نگرانیهای اصلی کاربر هنگامی که دادههای خود را در یک فایل معمولی ذخیره میکند، بحث عدم امنیت دادهها و امکان استفاده افراد غیر مجاز از دادهها میباشد. سیستمهای مدیریت بانک اطلاعات، از قابلیتهای امنیتی قدرتمندی برخوردار است. امکان تعریف سطوح دسترسی مختلف برای کاربران مختلف بر روی هر بخشی از دادهها و استفاده از روشهای رمزگذاری پیشرفته بر روی اطلاعات موجب میشود که تنها راه استفاده از دادههای ذخیره شده بر روی دیسک از طریق DBMS باشد. در نتیجه امنیت اطلاعات در سطح بسیار بالایی تضمین میشود.
همچنین بر خلاف سیستم فایل، سیستمهای مدیریت بانک اطلاعات معمولا از امکانات ویژهای جهت پشتیبان گیری دادهها برخوردارند. عملیات پشتیبان گیری خودکار نیز معمولا وجود دارد تا در صورت بروز حادثهای که منجر به از بین رفتن اطلاعات یا خرابی دادهها میشود، نسخههای پشتیبان را در اختیار داشته باشیم. همچنین در صورت خرابی دادهها خود DBMS اقدام به ترمیم دادهها میکند که این کار با استفاده از دادههای پشتیبان و نیز فایل حاوی گزارش تراکنشهای صورت گرفته بر روی دادهها (فایل log) صورت میگیرد.
۴- خطر بروز پدیده ناسازگاری دادهها (عدم مدیریت تراکنش)
تراکنش به عملیاتی اطلاق می شود که می خواهد روی داده های بانک اطلاعات پردازشی انجام دهد. یکی از وظایف مهم DBMS مدیریت تراکنشها است بنحویکه چهار ویژگی اصلی زیر همواره برای تراکنشها حفظ شود:
– یکپارچگی (Atomicity): هر تراکنش می تواند خود از یکسری عملیات جزئیتر تشکیل شده باشد. گاهی یک تراکنش در حالیکه تنها چند دستور اول آن اجرا شده، بدلیلی (مانند قطع برق) اجرای ادامه دستوراتش متوقف میشود. در روش فایلینگ و حتی در پایگاه دادههای فاقد DBMS در چنین مواقعی داده ها دچار ناهمخوانی می شوند و عملا دادهها نامعتبر میگردند. برای مثال فرض کنیم در یک نرم افزار بانک دستوری را اجرا کردهایم که قرار است ۱۰۰۰۰ تومان از حسابی به حساب دیگر منتقل کند. در اینجا تراکنشی داریم که شامل ۲ عملیات اصلی است. اول کسر ۱۰۰۰۰ تومان از حساب اول و سپس افزودن آن به حساب دوم. حال اگر بعد از اجرای دستور اول و قبل از اینکه دستور دوم اجرا شود برق قطع شود، چه اتفاقی میافتد؟ روشن است که اطلاعات ما دچار اشکال می شوند. اما DBMS با مکانیزمهای مطمئن خود تضمین می کند که یک تراکنش یا بطور جامع اجرا شود و یا اینکه اصلا اجرا نشود (در واقع تغییرات اعمال شده طوری خنثی گردد که گویی تراکنش اصلا اجرا نشده است).
– همخوانی (Consistency): اجرای صحیح یک تراکنش باید سیستم را همواره از یک حالت صحیح به حالت صحیح دیگری ببرد.
– انزوا (Isolation): اجرای همروند چند تراکنش نباید تاثیری روی یکدیگر داشته باشد. در واقع اجرای دو تراکنش بطور همروند همان نتایجی را باید داشته باشد که اجرای پشت سرهم آنها خواهد داشت.
– مانایی (Durability): نتایج اجرای یک تراکنش بر روی دادهها نباید موقتی باشد و بایستی پایدار بماند.
۵- عدم امکان اشتراکی شدن دادهها
سیستم فایل، در صورتیکه یک کاربر (یا برنامه) در حال نوشتن در یک فایل باشد، هیچ برنامه دیگری نمیتواند به فایل دسترسی داشته باشد و باصطلاح تا پایان کار آن برنامه فایل قفل میشود. اما همانطور که قبلا هم اشاره شد، سیستم DBMS امکان استفاده همزمان کاربران متعدد از دادهها را بصورت کاملا کنترل شده فراهم میآورد. در واقع DBMS از روشهای قفلگذاری پیشرفتهتری استفاده میکند. بعنوان مثال، از چندین نوع قفل مختلف استفاده میکند که این قفلها حالت سلسله مراتبی دارند. خیلی اوقات، DBMS بجای قفلگذاری بر روی کل فایل، بخش کوچکی از دادهها را که در حال تغییر است، قفل میکند.
۶- حجم زیاد برنامهسازی
در روش فایلینگ برای ساده ترین عملیات هم نیاز به کدنویسی نسبتا زیادی داریم. بعنوان مثال، برای تغییر نام یک دانشجو در فایل اطلاعات تعدادی دانشجو علاوه ب دستورات اولیه مربوط به باز کردن فایل و بردن مکاننما به ابتدای آن باید در یک حلقه رکوردهای فایل را یکی یکی بخوانیم تا به رکورد مورد نظر برسیم. سپس آنرا به حافظه بیاوریم، قسمت نام آن را تغییر دهیم و مجددا به محل مربوطه در فایل رفته و آنرا در فایل بنویسیم. میبینیم که همین عملیات ساده به نوشتن چندین خط برنامه نیاز دارد.
اما در سیستمهای پایگاه داده با توجه به اینکه از زبانهای نسل جدیدتری برخوردارند که بسیار نزدیک به زبان طبیعی است، تنها با یک دستور شبیه به زبان طبیعی به DBMS می گوییم که نام فلان دانشجو را به این نام جدید تبدیل کن.
۷- وابستگی برنامههای کاربردی به محیط ذخیرهسازی دادهها
قبل از توضیح این مطلب و بحث در مورد استقلال دادهای در پایگاه داده، معماری سیستم پایگاه دادهها را معرفی میکنیم.
معماری پشنهادی ANSI برای پایگاه دادهها یک معماری سه لایه است. این سطوح در حقیقت به دیدهای مختلفی مربوط میشود که بر روی پایگاه داده وجود دارد که شامل سه نوع دید داخلی، ادراکی و خارجی است.
دید خارجی
۱- دید یک کاربر خاص نسبت به دادههای ذخیرهشده در پایگاه داده است و بنابراین از کاربری به کاربر دیگر می تواند متفاوت باشد. بعنوان مثال در شکل ۲ دیدیم که سه نوع کاربر مختلف با سیستم اتوماسیون دانشگاه کار می کردند. با توجه به اینکه حیطه کاری هر کاربر متفاوت است، دیدی متفاوت نسبت به دادهها دارد. در واقع دید هر کاربر یک دید جزئی روی بخشی از داده های بانک می باشد. به مجموع دید تمام کاربران، سطح خارجی بانک اطلاعات گفته میشود.
دید ادراکی (مفهومی)
۱- دید طراح پایگاه دادهها نسبت به ساختار دادههای ذخیرهشده است. بر مبنای این دید است که طراح ساختارهای مورد نیاز برای دادهها را تعریف و بانک اطلاعات را بوجود میآورد. طراح بانک، دیدی کامل نسبت به ساختار کل بانک اطلاعات دارد و در حقیقت دید طراح جامع دید همه کاربران است. ساختار دادهها در این سطح شمای ادراکی نامیده میشود. سازنده شمای ادراکی طراح بانک اطلاعات است.
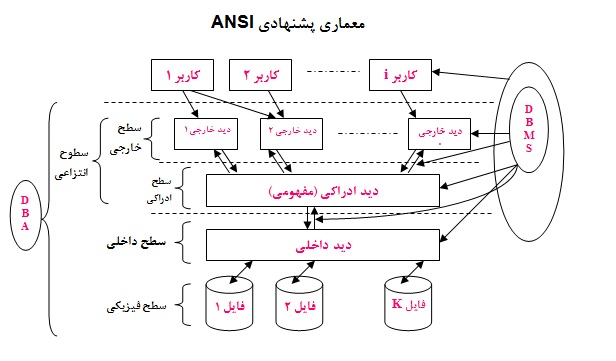
دید داخلی
این دید در سطح فیزیکی و محیط ذخیره سازی مطرح می شود. در این سطح به دادهها با دیدی سطح پایینتر نگاه میکنیم و مسائلی از قبیل شکل دادههای ذخیره شده بر روی دیسک، نحوه خوشه بندی، نوع شاخصگذاری، روش رمزگذاری و … در این سطح مطرح است. ساختار دادهها در این سطح شمای فیزیکی نامیده می شود که توسط DBMS ساخته میشود.
از آنجا که DBMS واسط بین کاربران و محیط فیزیکی است، این دید در درجه اول مخصوص خود DBMS است که وظیفه نگاشت دادهها از یک سطح به سطح دیگر را بعهده دارد. طراح پایگاه داده نیز ممکن است چنین دیدی داشته باشد؛ اما معمولا ضرورتی ندارد.
استقلال دادهای
استقلال دادهای یعنی وابسته نبودن برنامههای کاربردی به دادههای ذخیرهشده. برای ذخیره دادهها در فایل، ابتدا ساختاری در خود برنامه تعریف می شود و سپس فایلی با این ساختار ساخته میشود. در این حالت ساختار دادهها از محیط برنامه مجزا نیست و هر تغییری در ساختار داده ناگزیر در داخل خود برنامه بایستی صورت گیرد. اما در سیستم بانک اطلاعات داده از برنامه جداست. ساختار دادهها (همان شمای ادراکی) در محیط بانک اطلاعات تعریف میشود. سپس از طریق برنامه با ساختارهای تعریف شده ارتباط برقرار میگردد.
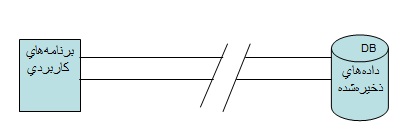
انواع استقلال دادهای
– استقلال دادهای فیزیکی
عبارتست از مصونیت دیدهای کاربران و برنامههای کاربردی در قبال تغییرات در سطح داخلی-فیزیکی پایگاه دادهها (شمای فیزیکی). بعنوان مثال، اگر نوع رسانه ذخیره سازی و یا محل ذخیره سازی عوض شود، این تغییر نباید تاثیری در دید کاربر برنامه (دید خارجی) داشته باشد. از آنجا که در سیستمهای بانک اطلاعات کاربران مستقیما با شطح فیزیکی ارتباطی ندارند، این نوع استقلال دادهای کاملا وجود دارد.
– استقلال دادهای منطقی
عبارتست از مصونیت دیدهای کاربران و برنامههای کاربردی در قبال تغییرات در شمای ادراکی پایگاه دادهها. یعنی اگر طراحی منطقی پایگاه دادهها شمای ادراکی تغییری ایجاد شود (که البته منجر به تغییر در شمای فیزیکی نیز خواهد شد) نباید تاثیری در دیدهای خارجی داشته باشد.
نقطه ضعف سیستم پایگاه داده نسبت به سیستم پرونده ای:
ایجاد هر مزیت و خدماتی مستلزم هزینه است. دستیابی به مزایایی که برای سیستم پایگاه داده و سیستم مدیریت پایگاه داده نام برده شد، مسلما بدون هزینه میسر نیست. بدلیل ساختار سه لایه ای پایگاه داده (نگاشتهایی که برای انجام هر عملیات بایستی بین لایه ها انجام گردد) و همچنین با توجه به کنترلهایی که سیستم مدیریت پایگاه داده برای تضمین جامعیت داده ها و تراکنشها، امنیت و … انجام می دهد، عملیات کاربر شامل سربارهای زمانی می شود و لذا برنامه های کاربردی ممکن است کندتر شوند. اما در کنار تمامی مزایای ارزشمند ذکرشده برای سیستم پایگاه داده این نقطه ضعف که البته محسوس و آزاردهنده نیست را می توان تحمل کرد.
زبانهای کار با بانک اطلاعات
برای برنامه نویسی بانک اطلاعات دو رده از زبانها مورد استفاده قرار میگیرند:
۱) زبان میزبان (HL)
یکی از زبانهای برنامهسازی متداول مانند کوبول، PL1، فرترن، پاسکال، C، C# و زبانهایی مثل ADA، LISP، JAVA و نیز زبان اسمبلی است. پس زبان میزبان را از قبل میشناسیم و چیز جدید و نامتعارفی نیست. اما تنها چیزی که ممکن است سوال برانگیز باشد این است که به چه دلیل در این مبحث به آنها زبان میزبان میگوییم؟! جواب این سوال بعد از معرفی نوع دوم زبانهای کار با بانک اطلاعات مشخص خواهد شد.
همانطور که میدانیم، زبانهای میزبان زبانهای خاص منظوره نیستند، بلکه معمولا زبانهای چند منظوره هستند. مثلا زبان C در زمینههای مختلف از جمله برنامه نویسی سیستمی، برنامه نویسی گرافیکی، برنامه نویسی بانک اطلاعات و … کاربرد دارد.
زبانهای میزبان در دسته بندی زبانهای برنامه نویسی از دسته زبانهای رویهای میباشند. دلیل این نامگذاری این است که برای هر عملیاتی که در این زبانها می خواهیم انجام دهیم، باید رویه انجام آنرا با جزئیات کامل ذکر کنیم.
۲) زبان دادهای فرعی (DSL)
زبانهایی هستند که بر خلاف زبانهای میزبان تک منظوره هستند؛ یعنی فقط شامل دستوراتی برای کار با پایگاه داده میباشند و اساسا به همین منظور ساخته شدهاند.
این زبانها نسل بعدی زبانهای رویهای هستند که به زبانهای توصیفی معروفند. این نوع زبانها خیلی به زبان طبیعی نزدیک هستند و هنگامی که می-خواهیم عملیاتی را اجرا کنیم بر خلاف زبانهای رویهای، فقط انجام آن عملیات را درخواست میکنیم و به روش و جزئیات مراحل انجام آن کاری نداریم. بعنوان مثال، برای بازیابی لیست دانشجویان که در بانک اطلاعات ذخیره شده، بجای نوشتن یک دستور حلقه که یکی یکی اطلاعات دانشجویان را خوانده و نمایش دهد، با یک دستور شبیه به زبان طبیعی (و البته با ساختار خاص آن زبان) میگوییم لیست دانشجویان را بازیابی کن.
زبانهای DSL بر حسب نوع دستوراتشان سه نوع مختلف میتوانند باشند:
۱- زبان تعریف دادهها (DDL): این زبانها شامل دستورات لازم جهت تعریف و کار با ساختارهای دادهای میباشند.
۲- زبان عملیات روی دادهها (DML): این زبانها شامل دستوراتی هستند که برای کار با دادههای بانک اطلاعات استفاده میشوند و به ساختار بانک اطلاعات کاری ندارند. عملیات اصلی DML عبارتند از: ورود داده جدید، ویرایش دادههای قبلا وارد شده، حذف دادهها و بازیابی دادهها.
۳- زبان کنترل دادهها (DCL): این زبانها شامل دستورات کنترلی هستند که برای کنترل صحت دادهها، جامعیت عملیات روی دادهها و … استفاده میشوند.
البته برخی از زبانهای DSL نیز هستند که هر سه نوع امکانات را شامل میشوند. SQL معروفترین و متداولترین زبان DSL است که شامل هر سه نوع این دستورات میباشد.
حال باید ببینیم که آیا زبانهای DSL نیز مانند زبانهای میزبان محیط برنامه نویسی خاص خودشان را دارند یا نه. بر این اساس، زبانهای DSL به دو دسته تقسیم میشوند:
۱- توکار (E.DSL): دستورات این ربانها بطور مستقل قابل اجرا نیست؛ بلکه باید برنامه ای به یک زبان میزبان نوشته شده باشد و در متن ن برنامه در جایی که نیاز هست، دستوری از زبان DSL (بصورت توکار) قرار داده شده باشد. مثل زبان Btrieve در C یا SQL در دلفی.
با این تعریف، دلیل نامگذاری زبانهای میزبان به این نام هم مشخص شد. در واقع این زبانها میزبان زبانهای DSL هستند.
۲- مستقل (I.DSL): این زبانها به زبان میزبان نیاز ندارد و به صورت مستقل استفاده میشوند. مثل زبان Foxpro که دارای یک محیط برنامه نویسی مستقل است و در آن می توان برنامههای کاربردی بانک اطلاعات را بدون نیاز به زبان دیگری بوجود آورد.
البته برخی از زبانهای DSL هم هستند که می توانند به هردو صورت مستقل و توکار بکار روند.
زمانی که در یک برنامه زبان میزبان دستورات زبانهای DSL بصورت توکار استفاده شده، عمل کامپایل دستورات اصلی زبان میزبان و دستورات زبان DSL بصورت جداگانه توسط کامپایلرهای خاص هریک از این دو زبان انجام میشود. اما در نهایت نتایج این دو عملیات کامپایل با هم تلفیق میشوند تا برنامه بطور یکپارچه اجرا شود. مراحل کامپایل این نوع برنامهها در شکل *** نشان داده شدهاست.
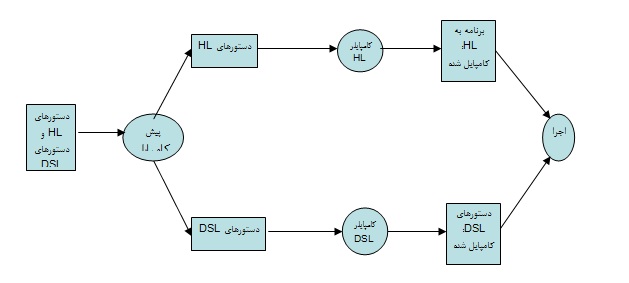
در شکل ** قسمتی از یک برنامه نوشته شده به زبان C# آورده شده است. کار این قطعه کد این است که اطلاعات ذخیره شده تمام دانشجویان را از بانک اطلاعات بازیابی کند. در خط سوم، یک دستور SQL در بطن دستور C# و در قالب یک رشته نوشته شده است. ساختار دستورات SQL در بخش ۵ بطور کامل مورد بحث قرار خواهد گرفت. در این مثال زبان میزبان C# و زبان DSL زبان SQL است که بصورت توکار استفاده شده است. برای تست کردن این برنامهها از لحظ نحوی، کامپایل کردن صرف کافی نیست. با توجه به اینکه دستور SQL بصورت رشته در یک زبان میزبان استفاده میشود، در کامپایلر زبان میزبان تنها دستورات خود زبان بررسی میشوند. اما با اجرای برنامه، دستور SQL به DBMS مربوطه ارسال میشود تا در آنجا با استفاده ازکامپایلر خودش کامپایل و در صورت صحت، اجرا گردد.
Conn.Open() ;
DataTable tbl = new DataTable() ;
SqlDataAdapter da = new SqlDataAdapter(“Select * From Students”,conn) ;
Da.Fill(tbl);
Conn.Close();
اجزای DBMS
DBMS از قسمتهای مختلفی تشکیل میشود که هر بخش وظیفه خاصی را انجام میدهد. اصلیترین اجزای تشکیل دهنده DBMS عبارتند از:
کاتالوگ سیستم شامل اطلاعات جامع در مورد سیستم پایگاه داده ها از قبیل حق دسترسی کاربران مختلف، مشخصات کاربران، تاریخ ایجاد و تغییر داده ها، سایز جداول و … است. دیکشنری دادهها نیز جزئی از کاتالوگ سیستم است. دیکشنری داده ها شامل تمام نامهایی است که برای اشیاء مختلف در سیستم انتخاب می شود. به کاتالوگ سیستم اصطلاحا فراداده (متادیتا) گفته می شود؛ زیرا کاتالوگ سیستم شامل خود دادههای اصلی ما نیست، بلکه شامل اطلاعاتی است در مورد دادههای اصلی (فراداده یعنی داده در مورد داده)
هر تغییری که در ساختار و کلیات پایگاه داده ایجاد میکنیم (مثلا هنگام تعریف یک کاربر جدید)، باید این تغییر در کاتالوگ سیستم ثبت شود. این وظیفه بعهده catalog manager می باشد.
نمای بیرونی (سادهشده) DBMS
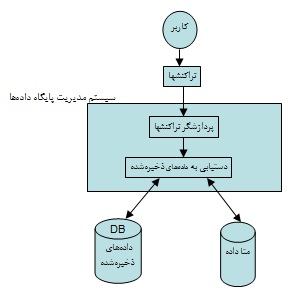
با توجه به قابلیتهایی که در این بخش برای DBMS ها برشمردیم، باید این نکته را نیز خاطرنشان سازیم که همه سیستم های پایگاه داده معروفی که تامنون تولید شدهاند، از یک سیستم مدیریتی قوی برخوردار نیستند؛ بلمه صرفا دارای یک رابط کاربر برای اجرای دستورات او بر روی دادهها میباشند. اما وظایف مهمی از قبیل کنترل جامعیت اجرای تراکنشها یا ایجاد امکان استفاده همزمان کاربران زیاد از دادهها را انجام نمیدهند. از معروفترین DBMS ها میتوان از MS SQL Server، MySQL و Oracle نام برد. اما پایگاه دادههای معروفی مانند Access و Foxpro در واقع DBMS نیستند و فقط یک سیستم بانک اطلاعاتی ساده تلقی میشوند.
——————————————————————–
فصل دوم:
دادههایی که قرار است در پایگاه داده ذخیره شوند، ابتدا باید با یک دید سطح بالا از لحاظ معنایی و مفهومی مدلسازی شوند. حاصل عملیات مدلسازی معنایی، ساختار منطقی بانک اطلاعات و در واقع همان شمای ادراکی است.
مدلها و روشهای مختلفی برای مدلسازی معنایی دادهها وجود دارند که از معروفترین آنها میتوان از مدل موجودیت- ارتباط (ER)، مدل Niam، مدل زبان یکپارچه مدلسازی (UML) و تکنیک مدلسازی شیئی (OMT) نام برد.
مدل ER و نمودار ER
مدل ER در اواسط دهه ۸۰ میلادی در دانشگاه MIT توسط فردی بنام چن پیشنهاد شد. این مدل بمرور زمان پیشرفت کرد و کم کم به EER (ER توسعه یافته) معروف شد. اما هنوز هم در خیلی جاها با همان نام ER از آن نام برده میشود. در این فصل به شرح کامل این مدل می پردازیم.
در مدل ER سه مفهوم اصلی وجود دارد که عبارتند از: موجودیت، صفت و ارتباط. نمودار ER هم نموداری است برای مدلسازی معنایی دادهها بر پایه مدل ER و در واقع سه مفهوم اساسی مدل ER، یعنی نوع موجودیت، صفت و ارتباط را بصورت شماتیک نمایش میدهد. قبل از هرچیز بهتر است با این سه مفهوم آشنا شویم.
تعریف موجودیت
مفهوم کلی شیئ، پدیده و به طور کلی هر آنچه که میخواهیم در موردش اطلاعاتی در بانک اطلاعات داشته باشیم و با استفاده از آن اطلاعات شناخت خود را در موردش افزایش دهیم.
بعنوان مثال، برای یک سیستم آموزشی که قرار است در یک دانشگاه استفاده شود، موجودیتهای دانشجو، استاد، دانشکده و درس را میتوان نام برد.
همانطور که میبینیم موجودیت یک مفهوم کلی و یا یک نوع داده مجرد است. اما هر موجودیت میتواند نمونه هایی داشته باشد. نمونههای یک موجودیت، مصداقهای آن موجودیت هستند و در واقع نمونهها هستند که وجود خارجی دارند. بعنوان مثال، درس پایگاه دادهها با یکسری ویژگیهای خاص خودش یک نمونه از موجودیت درس است.
اولین گام در مدلسازی معنایی بانک اطلاعات، شناسایی موجودیتهای مساله است. اما سوالی که ممکن است پیش بیاید این است که مثلا در مثال فوق، چرا خود دانشگاه را بعنوان یکی از موجودیتها در نظر نگرفتیم؟ یا بطور کلی بر چه اساسی اقدام به شناسایی موجودیتها میکنیم؟
یک قانون ساده برای تشخیص اینکه یک مفهوم خاص را آیا موجودیت به حساب بیاوریم یا خیر، این است که آن مفهوم بتواند شامل چند نمونه متمایز در حوزه مساله ما باشد. به بیان ساده، چیزی موجودیت تلقی میشود که بخواهیم لیستی از آن را در سیستم نگه داریم. در مثال فوق، دانشگاه را موجودیت بحساب نمیآوریم؛ چون سیستم قرار است اطلاعات دانشجویان یک دانشگاه را مدیریت کند. در اینجا دانشگاه خود حوزه اصلی مساله است که شامل موجودیتهای نامبرده شده میباشد. اما اگر صورت مساله را اینطور عوض کنیم که میخواهیم اطلاعات آموزشی دانشجویان سراسر کشور را از طریق این سیستم ذخیره و بازیابی کنیم، آنگاه دانشگاه هم یک موجودیت خواهد بود.
نکته دیگر در مورد موجودیتها این است که یک موجودیت معمولا بیش از یک ویژگی دارد که باید ذخیره شود. اما همانطور که خواهیم دید، این قانون همیشه صادق نیست.
در نمودار ER هر موجودیت در قالب یک مستطیل ساده نمایش داده میشود.
موجودیت مستقل و وابسته
موجودیت مستقل (قوی)، موجودیتی است که مستقل از هر موجودیت دیگر و به خودی خود، در یک محیط مشخص مطرح باشد. موجودیت وابسته (ضعیف)، موجودیتی است که وجودش وابسته به یک نوع موجودیت دیگر است. در واقع هر نمونه موجود از یک موجودیت ضعیف به یکی از نمونههای یک موجودیت قوی وابسته است. به این نوع ارتباط بین یک موجودیت ضعیف با یک موجودیت قوی وابستگی وجودی گفته میشود.
بعنوان مثال، فرض کنید کارمند و فیش حقوقی دو موجودیت در یک سیستم پرسنلی باشند. پس اطلاعات تعدادی کارمند و نیز تعدادی فیش حقوقی (بعنوان نمونههای دو موجودیت) در سیستم ذخیره شدهاند. اگر یک کارمند را از سیستم حذف کنیم، وجود فیشهای حقوقی مربوط به او دیگر مفهومی ندارد و منطقا باید حذف شوند. پس در این مثال، کارمند یک موجودیت مستقل و فیش حقوقی یک موجودیت وابسته است. اگر اطلاعات افراد خانواده کارمندان (عائله کارمند) نیز بعنوان یک موجودیت دیگر در این سیستم ذخیره شده باشد، آن نیز یک موجودیت وابسته به موجودیت کارمند میباشد.
برای تمایز موجودیتهای وابسته از موجودیتهای مستقل، در نمودار ER موجودیتهای وابسته با دو خط نشان داده میشوند.
تعریف صفت خاصه
خصیصه یا ویژگی یک نوع موجودیت است. هر نوع موجودیت مجموعهای از صفات خاصه دارد. هر صفت یک نام، یک نوع و یک معنای مشخص دارد. در نمودار ER هریک از صفات خاصه یک موجودیت با یک بیضی نشان داده شده و به موجودیت متصل میشوند.
انواع صفت خاصه
۱- صفت ساده یا مرکب
صفت ساده صفتی است که مقدار آن از لحاظ معنایی تجزیهنشدنی یا اتومیک است.
صفت مرکب صفتی است که از چند صفت ساده تشکیل شده است و به هر جزء آن بتوان بطور مستقیم دسترسی داشت.
صفت آدرس که خود شامل صفات جزئیتر شهر، خیابان و … است، میتواند یک صفت مرکب باشد، در صورتیکه ساختار آن در شمای ادراکی بهگونهای باشد که بتوان به این اجزا بطور مجزا و مستقیما دسترسی داشت. اما اگر ویژگی آدرس برای یک موجودیت بصورت یک رشته معمولی در نظر گرفته شود، دیگر یک صفت مرکب محسوب نمیشود؛ چون دسترسی مستقیم به هر جزء آن نداریم.
در بانک اطلاعات رابطهای امکان تعریف صفات مرکب وجود ندارد و همه صفات باید ساده باشند. پس اگر بخواهیم به اجزای یک صفت مانند آدرس دسترسی داشته باشیم چه باید بکنیم؟ راه حل کلی برای این مساله این است که در صورتی که چنین ضرورتی وجود دارد، بجای تعریف یک صفت خاصه بنام آدرس برای موجودیت، اجزای آن را بطور جداگانه (چند صفت ساده بجای یک صفت) در نظر بگیریم.
۲- صفت تکمقداری یا چندمقداری
صفت تکمقداری، صفتی است که برای یک نمونه از یک نوع موجودیت حداکثر یک مقدار از دامنه مقادیر را میگیرد.
صفتی که برای بعضی از نمونههای موجودیت ممکن است بیش از یک مقدار داشته باشد، یک صفت چندمقداری است. بعنوان مثال، صفت شماره دانشجویی، نام خانوادگی و … برای موجودیت دانشجو صفات تک مقداری محسوب میشوند؛ چون هر دانشجو تنها یک نام خانوادگی و یک شماره دانشجویی دارد. اما صفتی مانند شماره تلفن برای موجودیت دانشجو یک صفت چند مقداری است. زیرا بعضی از دانشجویان بیش از یک شماره تلفن دارند.
نمایش صفات چندمقداری در نمودار ER بصورت زیر است.
در بانک اطلاعات رابطهای امکان تعریف صفات چندمقداری وجود ندارد. پس اگر بخواهیم صفتی چندمقداری مثل شماره تلفن داشته باشیم چه باید بکنیم؟ راه حل کلی برای این مساله این است که برای هر صفت چندمقداری جدولی جداگانه طراحی کنیم و کلید موجودیت اصلی (مثل دانشجو) را بعنوان کلید خارجی در آن قرار دهیم.
۳- صفت کلید یا غیرکلید
صفت کلید یا شناسه موجودیت صفتی است که یکتایی مقدار دارد. بعبارت دیگر مقدار این صفت بین نمونههای مختلف تکرار نمیشود. بعنوان مثال، شماره دانشجویی برای موجودیت دانشجو یک صفت کلید است.
در مدلسازی معنایی، برای هر موجودیت باید یک شناسه مشخص کرد. اما یک موجودیت ممکن است بیش از یک شناسه داشته باشد. مثلا، کد ملی نیز یک شناسه دیگر برای موجودیت دانشجو است. در چنین حالاتی، یکی از شناسهها را باید بعنوان شناسه اول (اصلی) مشخص کرد. صفت دیگر نیز میتواند بعنوان شناسه دوم (فرعی) معرفی شود.
صفتی که قرار است بعنوان شناسه اصلی یک موجودیت (وجه تمایز اصلی بین نمونههای موجودیت) استفاده شود بهتر است حتی الامکان طول مقادیرش کوتاه باشد.
در نمودار ER شناسه اول یک موجودیت با کشیدن یک خط و شناسه دوم با کشیدن دو خط در زیر عنوان آن مشخص میشود.
گاهی اوقات، یک موجودیت صفت تکرار ناپذیری ندارد تا بعنوان کلید آن در نظر گرفته شود. یک راه برای حل این مشکل استفاده از کلیدهای ترکیبی است. یعنی باید ترکیبی از صفات را بیابیم که آن ترکیب بین نمونههای آن موجودیت تکرار نشود. مثلا فرض کنیم موجودیت دانشجو اصلا صفاتی بنام شماره دانشجویی و کد ملی نداشت. در این حالت با این فرض که ترکیب سه صفت نام، نام خانوادگی و شماره شناسنامه بین دانشجویان امکان تکرار ندارد، میتوان ترکیب این سه صفت را بعنوان کلید موجودیت دانشجو معرفی کرد. به چنین کلیدهایی کلید ترکیبی گفته میشود. روش نمایش کلیدهای ترکیبی در نمودار ER بصورت زیر است:
در فصل بعد، مفاهیم مربوط به کلید بطور کاملتر مورد بحث قرار خواهد گرفت.
۴- صفت هیچمقدارپذیر یا ناپذیر
هیچ مقدار یعنی مقدار ناشناخته، مقدار غیرقابل اعمال یا مقدار تعریف نشده که معمولا با واژه Null نشان داده میشود.
اگر مقدار یک صفت در یک یا بیش از یک نمونه از یک موجودیت، بتواند برابر با هیچمقدار باشد، آن صفت هیچمقدارپذیر است.
هیچ مقدار پذیر بودن یا نبودن هر صفت خاصه توسط طراح بانک اطلاعات و معمولا با توجه به اهمیت آن صفت تعیین میشود. مثلا نام خانوادگی دانشجو بدلیل اینکه مهم است که برای هر دانشجو مقدارش مشخص باشد، بهتر است هیچ مقدار پذیر نباشد. اما صفتی مثل شماره تلفن بدلیل اهمیت کمتر و نیز به این علت که ممکن است دانشجویی شماره تلفن نداشته باشد، ممکن است هیچ مقدار پذیر تعریف شده باشد.
۵- صفت ذخیرهشده یا مشتق
صفت ذخیرهشده صفتی از یک موجودیت است که مقادیرش برای نمونههای آن موجودیت در پایگاه دادهها ذخیره شود.
صفت مشتق، صفتی است که مقادیرش در پایگاه دادهها ذخیره نشده باشد، بلکه از روی دادههای ذخیره شده قابل اشتقاق یا محاسبه باشد. بعنوان مثال، اگر تاریخ تولد هر دانشجو (بعنوان یکی از صفات خاصه) در سیستم ذخیره شود، دیگر نیازی به ذخیره صفت سن دانشجو نیست و این ویژگی با توجه به تاریخ تولد قابل محاسبه است. پس در اینجا تاریخ تولد یک صفت ذخیره شده و سن یک صفت مشتق است.
برای نمایش صفات مشتق در نمودار ER می توان یا بیضی مربوط به آن صفت و یا خط اتصال آن صفت به موجودیت را بصورت نقطه چین رسم کرد.
ارتباط
تعریف- تعامل و وابستگی بین دو یا بیش از دو نوع موجودیت است.
ارتباط بین دو موجودیت در حقیقت ارتباط بین نمونههای آن دو موجودیت است. هر ارتباط دارای یک عنوان و یک مفهوم مشخص است. بعنوان مثال، بین دو موجودیت دانشجو و درس ارتباط “انتخاب” وجود دارد. یعنی نمونههای موجودیت دانشجو، نمونههایی از موجودیت درس را انتخاب میکنند.
در نمودار ER ارتباط با نماد لوزی نشان داده میشود.
اگر نمونههایی از یک موجودیت بتوانند با نمونههایی از همان موجودیت ارتباط داشته باشند، باید یک ارتباط از موجودیت به خودش رسم شود. مثلا، بین نمونههای موجودیت درس، ارتباط پیش نیازی برقرار است.
ماهیت ارتباط
چندی ارتباط یا بعبارتی نوع تناظر بین نمونههای دو موجودیت حاضر در ارتباط را نشان میدهد. ماهیت ارتباط میتواند یک به یک (۱:۱)، یک به چند (۱:n) یا چند به چند (m:n) باشد.
ارتباط ۱:۱: هر نمونه از موجودیت اول میتواند فقط با یک نمونه از موجودیت دوم ارتباط داشته باشد. هر نمونه از موجودیت دوم نیز فقط میتواند با یک نمونه از موجودیت اول ارتباط داشته باشد. در واقع همان مفهوم تناظر یک بیک در نظریه مجموعهها است.
بعنوان مثال، اگر درجه ارتباط بین موجودیتهای دانشجو و درس ۱:۱ باشد (مطابق شکل زیر)، مفهوم ارتباط چنین است:
هر دانشجو میتواند فقط یک درس را بگیرد. هر درس هم میتواند فقط توسط یک دانشجو گرفته شود.
ارتباط ۱:n: هر نمونه از موجودیت اول میتواند با چند نمونه از موجودیت دوم ارتباط داشته باشد. اما هر نمونه از موجودیت دوم فقط میتواند با یک نمونه از موجودیت اول ارتباط داشته باشد.
اما اگر درجه ارتباط بین موجودیتهای دانشجو و درس ۱:n باشد (مطابق شکل زیر)، مفهوم ارتباط چنین است:
هر دانشجو میتواند چند درس را بگیرد. اما هر درس میتواند فقط توسط یک دانشجو گرفته شود.
ارتباط m:n: هر نمونه از موجودیت اول میتواند با چند نمونه از موجودیت دوم ارتباط داشته باشد. هر نمونه از موجودیت دوم نیز میتواند با چند نمونه از موجودیت اول ارتباط داشته باشد.
حال اگر درجه ارتباط بین موجودیتهای دانشجو و درس m:n باشد (مطابق شکل زیر)، مفهوم ارتباط چنین است:
هر دانشجو میتواند چند درس را بگیرد. هر درس هم میتواند توسط چند دانشجو گرفته شود.
روشهای نمایش دیگری نیز برای نشان دادن ماهیت ارتباط ها وجود دارد، از جمله ارتباط ۱:n فوق به اشکال زیر نیز نمایش داده می شود:
حد ارتباط
برای هریک از موجودیتهای شرکت کننده در یک ارتباط میتوان یک حد مشخص کرد. این حد نشان دهنده حداقل و حداکثر تعداد نمونههای آن موجودیت است که می توانند در ارتباط شرکت کنند.
بعنوان مثال، حدود نشان داده شده در شکل زیر برای دو موجودیت دانشجو و درس بیانگر مفاهیم زیر هستند:
هر دانشجو حداقل ۱ و حداکثر ۵ درس را می تواند انتخاب کند.
هر درس می تواند توسط هیچ دانشجویی انتخاب نشود و یا حداکثر توسط ۲۰ دانشجو انتخاب شود.
شرکت اجباری و اختیاری در ارتباط
موجودیتهایی که در یک ارتباط شرکت دارند، نوع ارتباطشان میتواند اجباری یا اختیاری باشد. اگر مقدار حداقل حد یک موجودیت در یک ارتباط ۰ باشد، به این معنی است که نمونه ای از این موجودیت می تواند وجود داشته باشد که اصلا در ارتباط شرکت نکند. در این حالت شرکت موجودیت را اختیاری میگوییم. در غیر اینصورت، شرکت موجودیت در ارتباط اجباری است.
اگر شرکت موجودیت دانشجو در ارتباط انتخاب درس اجباری و شرکت درس در این رابطه اختیاری باشد، این دو مفهوم به شکل زیر در نمودار این دو موضوع به شکل زیر در نمودار ER نشان داده میشوند.
روش دیگر نمایش ارتباط اجباری با استفاده از دو خط است:
روش سومی هم برای نمایش شرکت اجباری و اختیاری موجودیتها وجود دارد و آن به شکل زیر است:
از نمادهای دایره و خط در این نوع نمایش می توان به ۰ و ۱ (بعنوان نقاط شروع حد ارتباط) تعبیر کرد.
نکته مهم:
در یک ارتباط ۱:n اگر نوع مشارکت موجودیت سمت n اجباری باشد، این موجودیت یک موجودیت وابسته است که وابستگی آن به موجودیت سمت ۱ است.
تبدیل نمودار ER به بانک اطلاعات رابطه ای:
اگرچه مفهوم بانک اطلاعات رابطه ای مبحث فصل بعد است، اما بدلیل اهمیت موضوع تبدیل نمودار ER به بانک اطلاعات و برای اینکه در بحث طراحی بانک اطلاعات فاصله ایجاد نشود، در اینجا اشارهای به این بحث می نماییم. بانک اطلاعات رابطه ای مدلی از بانک اطلاعات است که در آن هر موجودیت به شکل یک جدول در می آید که ستونهای آن صفات خاصه موجودیت و هر سطر آن نمونه ای از آن موجودیت است. ارتباط بین دو موجودیت نیز از طریق اضافه کردن کلید یک موجودیت به موجودیت دیگر (موسوم به کلید خارجی) برقرار می شود. با این مقدمه کوتاه، به شرح مراحل تبدیل موجودیتها به جداول می پردازیم:
۱- بازاء هر موجودیت یک جدول طراحی می کنیم که ستونهای آن صفات خاصه موجودیت بوده و هر سطر آن یک نمونه از آن موجودیت است.
۲- هر ارتباط بین موجودیتها در نمودار ER بسته به ماهیت آن باید در جدائل لحاظ شود. طبق قوانین زیر:
– ارتباط ۱:۱: در این حالت می توان دو موجودیت را در قالب یک جدول ادغام کرد و نیازی به جدا کردن دو جدول نیست.
– ارتباط ۱:n : پس کلید اصلی موجودیت سمت ۱ را بعنوان کلید خارجی به جدول مربوط به موجودیت سمت n نیز اضافه میکنیم.
– ارتباط m:n : برای برقراری ارتباط بین دو جدول، یک جدول دیگر بعنوان جدول واسط طراحی می کنیم. در این جدول واسط، کلیدهای اصلی مربوط به هر دو موجودیت بعنوان کلیدهای خارجی قرار میگیرند.
پس همانگونه که می بینیم در ارتباط m:n خود ارتباط بین دو موجودیت نیز به یک موجودیت تبدیل میشود. از اینرو گاهی در نمودار ER ارتباطهای m:n را به شکل یک موجودیت نمایش می دهند، مثلا:
چند مثال جامع:
مثال اول:
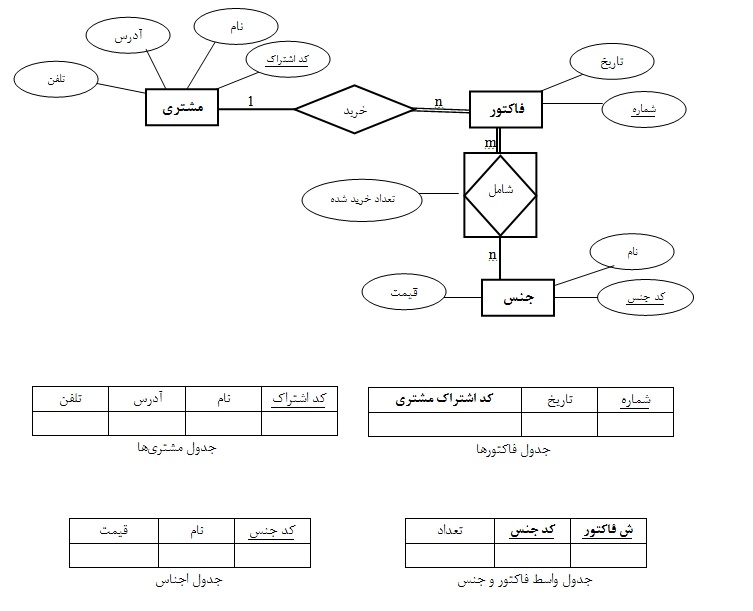
برای یک سیستم فروشگاه با مشخصات زیر یک نمودار ER طراحی کنید و سپس آنرا به بانک اطلاعات رابطه ای تبدیل کنید.
فروشگاه تعدادی مشتری ثابت و مشخص دارد که هر مشتری دارای کد اشتراک، نام، نشانی و تلفن میباشد.
هریک از اجناس فروشگاه یک کد مشخصه، نام و قیمت دارد. (توجه شود که اجناس یک نمونه کد مشخصه یکسانی دارند.)
هر مشتری می تواند در هر بار خرید از برخی اجناس تعدادی را خریداری کند. بازای هر خرید یک فاکتور صادر می شود که دارای شماره و تاریخ است.
حل:
طراحی نمودار ER:
با توجه به سوال مشخص است که موجودیتهای اصلی عبارتند از: مشتری، جنس و فاکتور. از لحاظ ارتباط منطقی هم مشتری و جنس هریک با فاکتور ارتباط دارند و باید توجه شود که ارتباط دو موجودیت مشتری و جنس فقط از طریق موجودیت فاکتور میباشد.
ماهیت ارتباط بین مشتری و فاکتور: برای هر مشتری می تواند در زمانهای مختلف چندین فاکتور ثبت شود. اما هر فاکتور مربوط به یک مشتری است. بنابراین ماهیت ارتباط ۱:n است.
ماهیت ارتباط بین جنس و فاکتور: با توجه به اینکه اجناس همسان یکی فرض میشوند (کد یکسانی دارند)، هر جنس ممکن است در چندین فاکتور ثبت شود. از طرفی هر فاکتور هم ممکن است شامل چندین قلم جنس باشد. بنابراین ماهیت ارتباط m:n است. در نتیجه این ارتباط خود به یک موجودیت تبدیل میشود. تعداد خریداری شده از یک جنس یک قلم اطلاعاتی است که هم مربوط به جنس و هم مربوط به فاکتور است. پس یک صفت خاصه برای موجودیت واسط آنها محسوب می شود.
تبدیل به بانک اطلاعات رابطه ای:
بعد از رسم یک جدول برای هریک از موجودیتها،
– ارتباط بین مشتری و فاکتور ۱:n است. پس کلید اصلی مشتری (موجودیت سمت ۱) را بعنوان کلید خارجی به جدول فاکتور (موجودیت سمت n) نیز اضافه میکنیم.
– ارتباط بین جنس و فاکتور m:n است. بنابراین برای برقراری ارتباط بین دو جدول، یک جدول دیگر بعنوان جدول واسط طراحی می کنیم. در این جدول واسط، کلیدهای اصلی مربوط به هر دو موجودیت فاکتور و جنس بعنوان کلیدهای خارجی قرار میگیرند. این جدول نشان می دهد که چه فاکتوری (شماره فاکتور) شامل چه جنسی (کد جنس) بوده است. با قرار دادن صفت تعداد خریداری شده در این جدول مشخص می شود که چه فاکتوری شامل چه جنسی و به چه تعدادی بوده است.
برای کلید اصلی این جدول می توان از ترکیب دو صفت ش فاکتور و کد جنس استفاده کرد و یا از کلیدهای شماره گذاری اتوماتیک (Auto Increment Number) استفاده کرد.
مثال دوم:
برای یک سیستم دانشگاه با مشخصات زیر یک نمودار ER طراحی کنید و سپس آنرا به بانک اطلاعات رابطه ای تبدیل کنید.
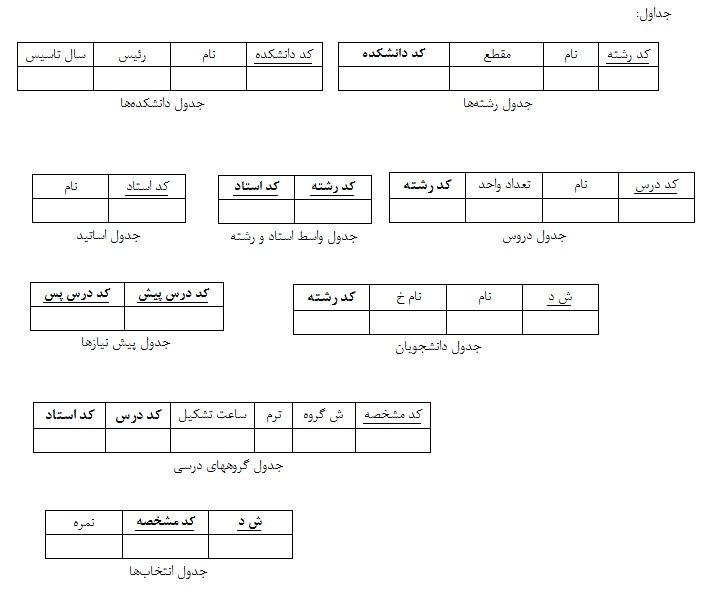
دانشگاه شامل تعدادی دانشکده است که هر دانشکده یک کد، نام، رئیس و یک سال تاسیس دارد.
در هر دانشکده تعدادی رشته دایر است که هر رشته شامل یک کد، یک نام و یک مقطع است.
در هر رشته تعدادی دانشجو تحصیل میکنند که هر دانشجو دارای شماره دانشجویی، نام و نام خانوادگی است.
هر رشته تعدادی استاد دارد که البته بعضی از اساتید بین چند رشته مشترکند. هر استاد دارای کد، نام است.
در سرفصل هر رشته تعدادی درس تعریف شده که هر درس دارای کد، نام درس و تعداد واحد است. هر درس می تواند چندین پیش نیاز داشته باشد و یا پیش نیاز چندین درس دیگر باشد.
در هر ترم از هر درس چندین گروه درسی ارائه می شود که هر گروه یک کد مشخصه، یک شماره گروه و یک ساعت تشکیل دارد.
از دروس ارائه شده هر دانشجو چندین مورد را انتخاب می کند و در نهایت برای هرکدام نمره ای کسب میکند.
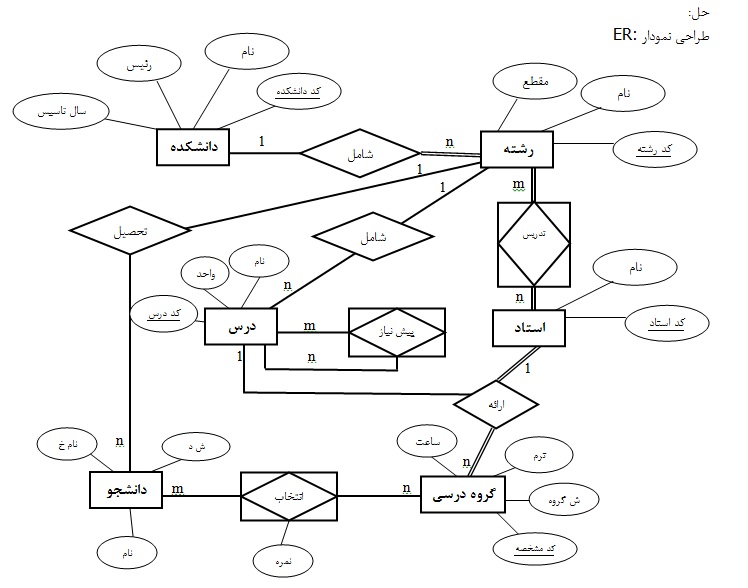
اسلاید مدل رابطه ای
dbSession4 – مدل رابطه ای
dbSession5 – جبر رابطهای
dbSession6 دستورات مربوط به اسکیما (DDL) – دستورات کار با داده ها (DML) – دستورات کنترلی (DCL)
dbSession7 – دستورات مربوط به اسکیما (DDL) – دستورات کار با داده ها (DML)
dbSession8 – دستور Select
dbSession9 – دستورات Insert و Update
dbSession10 نرمال سازی (قسمت اول: وابستگی های تابعی)
dbSession11 – نرمال سازی ( تبدیل جداول غیر نرمال به صورتهای نرمال اصلی )
کلاس تدریس یار یادگیری ماشین* دکتر مولایی* مورخ ۱۱-۱۲-۹۲ تشکیل نمی گردد.
تاریخ تشکیل کلاس جبرانی متعاقبا اعلام می گردد.
Propagation
در این حالت با استفاده عدم قطعیت از متغیر های مستقل به متغیر های وابسته منتشرمی شود
توابع فازی از متغیر های Crisp

فرض می کنیم یک تابع از x , y به ما داده اند
p(y) تابع فازی تعریم می کنیم از p تیلدای Y
یک مثال عددی
توابع مجموعه ای
با استفاده از کات توابع فازی را می توانیم به توابع کریسپ
مجموعه ای تبدیل کنیم ( برای ساده سازی )
فرض کنیم دو مجموعه در اختیار ما گذاشته اند
با استفاده از مفهوم ماکزیمم و مینیمم توابع
Fuzzy Extrema of Function
مهم :
فرض کنیم یک مجموعه کاکزیمم ساز مثل f را تعریف کرده ایم
چقدر امکان دارد که مقدار suprimum f را کسب کند
فرض کنیم بازه suprimum f 9 تا عدد داشته باشد
در اینصورت با توجه به رنج امکان f x که دارای این مقادیر باشد را می توانیم محاسبه کنیم

در این حالت که مینیمم یا منفی x را محاسبه کنیم مشابه هم هست
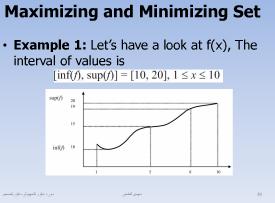
مثال :
مشابه شبیه سازی مونت کارلو انجام می دهیم
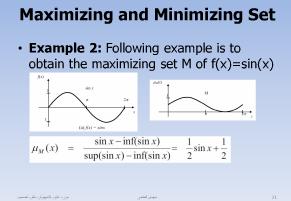
همین مساله را می توانیم گسترش دهیم
در یک دامنه غیر خطی با انجام عملیات ماکزیمم سازی مقدار x0 را می توانیم پیدا کنیم