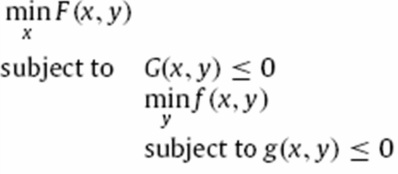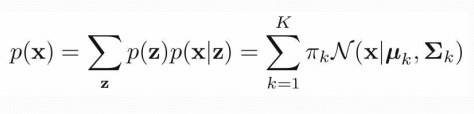تمرین مهلت : ۴ آذر
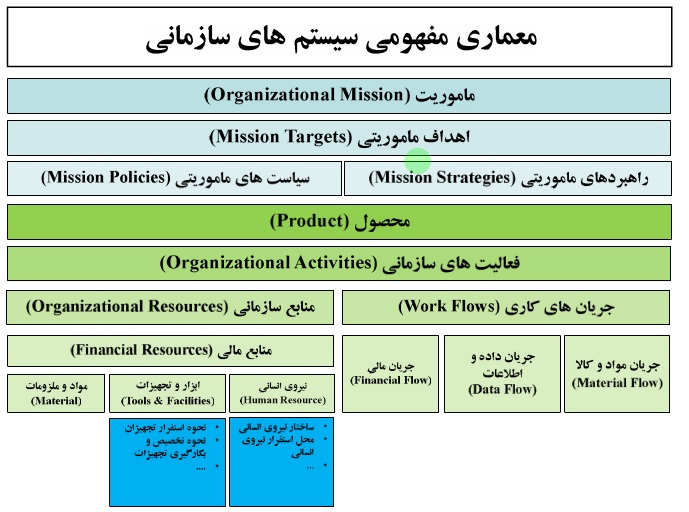
GMM
پیاده سازی k-means
جواب خروجی های k-means بردار وزن ، کواریانس ، را به GMM می دهیم
روش PCA ( Pricipal Component Analysis)
یکی از روش های کاهش بعد هست
وقتی ابعد زیادی داریم باید از روش کاهش بعد استفاده کنیم
مثلا ۳ تا بعد را نسبت به هم رسم کنیم که حالت های خیلی زیادی می شود.
یا اینکه به صورت رندوم چند مولفه را حذف کنیم !!!
یا اینکه مولفه هایی را نگه داریم که بیشترین تاثیر گذاری را دارد
پس PCA روشی است که کاربرد های ( کاهش بعد ، فشرده سازی ، استخراج ویژگی ،تصویر سازی ) دارد
دو تعریف رایج برای PCA که الگوریتم یکسانی دارد :
تعریف ۱ : داده ها را در یک زیر فضا تصویر کنیم به طوری که هدفی آن واریانس داده های تصویر شده بیشینه باشد
تعریف ۲ : تصویر خطی که فاصله تصویر میانگین فاصله های مجذور شده بین نقاط داده های و تصویرهایشان ، کمینه شود.
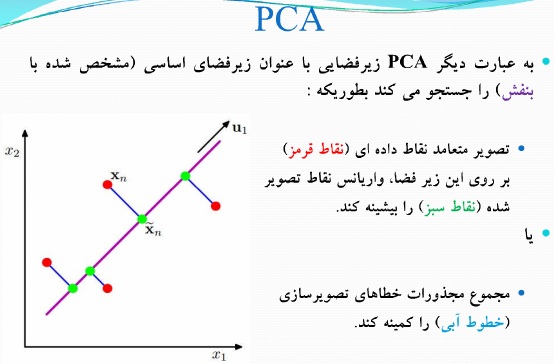
داده های اصلی داده های قرمز رنگ هستند
از این داده های قرمز رنگ تصویری رسم می کنیم که نقاط سبز بدست می آید
با تعریف اول : نقاط سبز از هم بیشترین فاصله را داشته باشند
با تعریف دوم : مجموع خط های آبی رنگ کمترین باشد

فرمولاسیون ماکزیمم واریانس :
این فرمولاسیون مطابق با تعریف اول است .
مثلا ما ۱۰۰ تا داده ۴ بعدی داریم
N=100
D=4
می خواهیم واریانس تصویر داده ها حداکثر شود
در ابتدا فرض می کنیم که داده ها را در یک بعد بهینه می خواهیم تصویر کنیم
اندازه بردار اهمیتی ندارد ، جهت بردار مهم است
پس قیدی می گذاریم : Norm بردار u1 باید ۱ شود
یا اول از کل داد ه ها میانگین بگیریم بعد تصویر کنیم
میانگین داده ها ی تصویر شده را بدست آوردیم
S ماتریس کواریانس
u هم بردار
حتما این اسلاید ها را مطالعه کنید




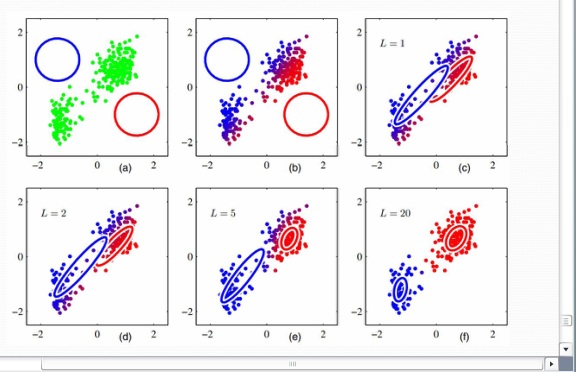
 Mutual Consistency
Mutual Consistency