خزنده وب و موتور جستجو بر اساس Nutch + Hadoop + Hbase + ElasticSearch
معماری خزنده وب Nutch + Hadoop، نمونه آنلاین توزیع معماری پردازش دسته ای است، توان خزیدن عملکرد بسیار خوبی دارد و ارائه گزینه های زیاد پیکربندی برای سفارشی سازی. خزندگان به عنوان تنها مسئول خزیدن در منابع شبکه وب است، بنابراین نیاز به یک موتور جستجو توزیع شده، مورد استفاده برای خزیدن منابع شبکه خزنده وب در زمان واقعی نمایه سازی و جستجو می باشد.
معماری موتور جستجو در ElasticSearch، توزیع آنلاین زمان واقعی معماری پرس و جوی تعاملی تقریبا با هیچ نقطه شکستی، به طور مقیاس پذیر، بسیار در دسترس است. از مقادیر زیادی از اطلاعات را با شاخص های جست و جو می تواند در مورد نزدیکی زمان واقعی است به اتمام است، این امکان وجود دارد تا به سرعت برای فایل در زمان واقعی و میلیاردها داده در سطح PB جستجو، در حالی که ارائه این گزینه از تمام جنبه، می تواند تقریبا در هر جنبه از موتور سفارشی ساخته شده است. پشتیبانی از API آرام، شما می توانید با استفاده از JSON تماس توابع مختلف خود را از طریق HTTP، از جمله جستجو، تجزیه و تحلیل و نظارت. علاوه بر این، برای جاوا، پی اچ پی، پرل، پایتون، روبی و و زبان های دیگر کتابخانه های مشتری بومی است.
پس از خزنده از طریق خزنده وب برای استخراج داده های ساخت یافته را مشاهده کنید برای جستجو شاخص موتورهای حرفه ای برای تجزیه و تحلیل پرس و جو. به عنوان موتور جستجو است که به نزدیکی زمان واقعی پرس و جو های پیچیده تعاملی طراحی شده است، بنابراین موتورهای جستجو به شاخص نیست صفحه برای نجات محتوای اصلی، بنابراین، نیاز به نزدیکی زمان واقعی پایگاه داده توزیع شده برای ذخیره محتویات صفحه اصلی.
معماری پایگاه داده توزیع شده در Hbase + Hadoop، نمونه توزیع آنلاین زمان واقعی معماری دسترسی تصادفی است. سطح قوی از مقیاس پذیری برای حمایت از میلیاردها و میلیون ها نفر از ردیف ستون، داده ها می تواند بر روی خزنده وب است در زمان واقعی نوشته شده است را مشاهده کنید، و می تواند موتور جستجو، زمان واقعی دسترسی به داده ها بر اساس نتایج جستجو را تامین کند.
خزنده وب، پایگاه داده توزیع شده، موتور جستجو در یک خوشه از سخت افزار تجاری عادی اجرا شود. خوشه با استفاده از معماری توزیع شده است که می تواند به هزاران نفر از ماشین آلات، مکانیزم های تحمل پذیر خطا، بخشی از شکست گره دستگاه از دست دادن داده نمی شود نمی خواهد به شکست وظایف محاسبات منجر گسترش داده است. نه تنها در دسترس بودن، هنگامی که یک شکست گره می تواند به سرعت عدم موفقیت، و گسترش بالا، دستگاه باید قادر به سادگی به افزایش سطح انبساط خطی، بهبود ظرفیت ذخیره سازی داده ها و سرعت محاسبات.
روابط خزنده وب، پایگاه داده توزیع شده، موتور جستجو بین:
۱، پس از خزنده وب را به رندر صفحه HTML خزیدن کامل است، داده تجزیه به صف بافر، توسط دو موضوعات دیگر مسئول برای پردازش داده ها، یک موضوع مسئول برای صرفه جویی در داده ها به پایگاه داده توزیع شده است، یک موضوع مسئول داده است به شاخص های ارائه شده به موتورهای جستجو.
۲، موتور جستجو فرآیندهای ضوابط جستجو کاربر، و نتایج جستجو بازگشت به کاربر در صورتی که کاربر مشاهده عکس فوری صفحه وب را از یک پایگاه داده توزیع شده برای به دست آوردن محتوای وب اصلی است.
معماری کلی به عنوان زیر نشان داده شده:
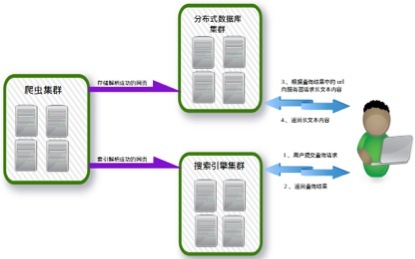
خوشه خزندگان، خوشه پایگاه داده توزیع شده، موتور جستجوی خوشه در استقرار فیزیکی، را می توان در همان خوشه سخت افزار مستقر می توان به طور جداگانه مستقر، تشکیل ۱-۳ سخت افزار خوشه.
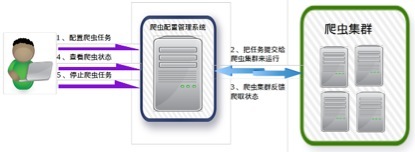
خزنده وب خوشه دارای یک خزنده وب سیستم مدیریت پیکربندی اختصاصی مسئول پیکربندی و مدیریت از خزندگان است، به عنوان زیر نشان داده شده:
موتور جستجو توسط تکه تکه شدن (سفال) و کپی (ماکت) برای دستیابی به عملکرد بالا، مقیاس پذیر و بسیار در دسترس است. روش برش برای نمایه سازی و جستجوی انبوه موازی را فراهم می کند پشتیبانی، که تا حد زیادی بهبود عملکرد نمایه سازی و جستجو، که تا حد زیادی بهبود سطح مقیاس پذیری، فن آوری فراهم می کند نسخه اضافه از اطلاعات، بخشی از شکست ماشین می کند استفاده عادی از سیستم تاثیر نمی گذارد، برای اطمینان از در دسترس بودن ادامه از سیستم.
ساختار شاخص وجود دارد ۲ و ۳ نسخه از قطعات به شرح زیر است:
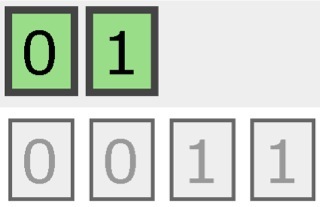
شاخص کامل از ۰ و ۱ به دو قسمت جداگانه قطع، هر بخش دارای دو نسخه از آن بخش خاکستری زیر کلیک کنید.
در یک محیط تولید، با افزایش اندازه داده، به سادگی یک گره به دستگاه های سخت افزاری را اضافه کنید، موتور جستجو به طور خودکار تنظیم به جای تعداد سخت افزار تکه تکه شدن را افزایش می دهد، زمانی که برخی از گره بازنشسته، موتور جستجو خواهد شد به طور خودکار تنظیم به جای کاهش در تعداد قطعات سخت افزاری، در حالی که تعداد نسخه را می توان با توجه به تغییرات در سطح اطمینان از سخت افزار و ظرفیت ذخیره سازی در هر زمان تغییر می کند، تمام این پویا است، بدون راه اندازی مجدد سیستم خوشه، که آن هم تضمین مهم برای در دسترس بودن بالا.
منبع : http://my.oschina.net/apdplat/blog/308396