دانلود رکود کلاس حضوری
پروژه ها را شروع کنید
تا آخر بهمن احتمالا وقت هست برای تحویل پروژه
جواب نمونه سوالات ترم گذشته
سوال ۱ :
a) درست است
b) نادرست است (تحلیل مولفه های اصلی نیست – اصلا به تعداد کلاسها توجهی ندارد )
c) نادرست ( EM در GMM بود و در سلسه مراتبی نیست )
d) درست است
e) درست است
f) اشتباه است
سوال ۲ :
a) در PCA مولفه های موثر در را مشخص می کند
b ) فیشر – خطی بودن
c) رسم نقاط – با روش فیشر حل می کنیم
SW^1(mu1-mu2)
سوال ۳ :
a) برچسب داشته باشد بهتر است
b) تعداد داده های اشتباه تقسیم بر تعداد کل مشاهدات
برای بهتر شدن و جلوگیری از Overfitting از CrossValidation میشه استفاده کرد
c) هزینه محاسباتی زیاد است – برای کاهش بعد
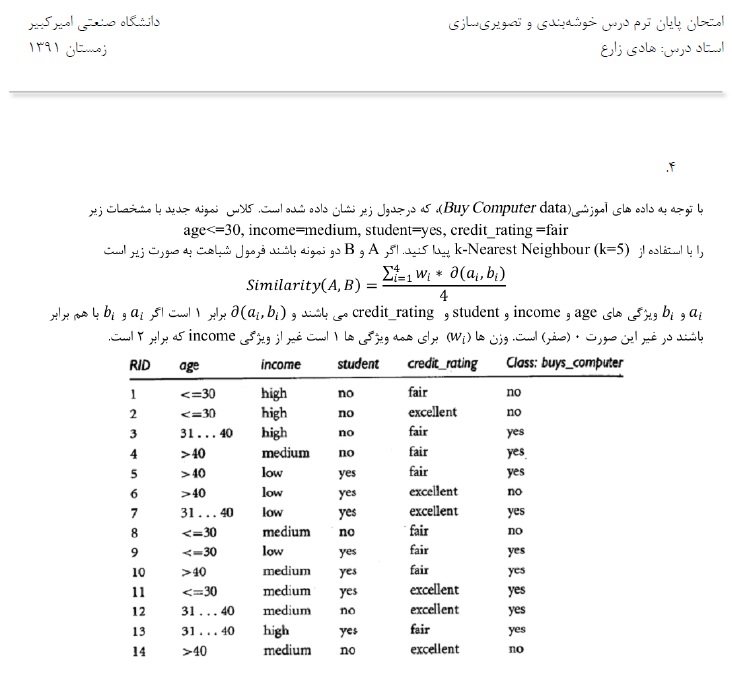
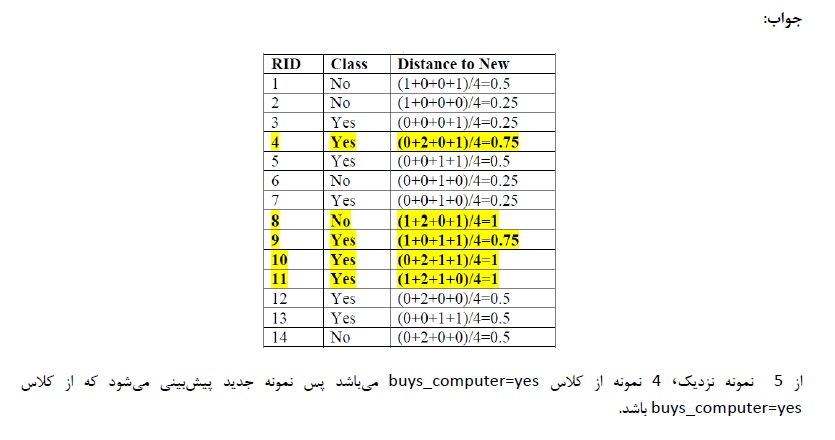
ابتدا باید similarity را باید حساب کنیم ( بجای محاسبه distance )
نمونه جدید را داریم
نونه سوال ترم پیش : نمونه سوال خوشه بندی – دکتر زارع

————-
ارائه خانم مهندس شیخیان
روش خوشه بندی Cure
یک روش خوشه بندی سلسله مراتبی است
سلسله مراتبی ها
خوشه ها از بالا به پایین خوشه ها مشخص تر هستند ولی انباشتگیشون بیشتر است
تمرکز خوشه بندی یک نقطه هست و بر اساس میانگین خوشه ها می تواند با هم merge شوند
مزیت Cure نسبت به سایر روشهای سلسله مراتبی تشخیص خوشه های کروی و غیر کروی را می تواند
انجام دهد
مزایای Cure حساس نبودن به شکل هست
وبه Outlier حساس نیستند چون خوشه بندی را بر اساس میانگین انجام می دهند و نه بر اساس فاصه
نقطه ها
یک الفا بین صف و یک تعریف می شود
و هر چه به صفر نزدیک تر باشد بر اساس تمام نقاط ورودی
و هر چه به یک نزدیک شود بر اساس یک نقطه انجام می دهد
در هر خوشه که تعدای نقاط را داریم
بر اساس Merge شدن نقاط هست
بقیه نقاط در مراحل بعدی با هم Merge می شوند
این روش ار random Sample استفاده می کند
خوشه بندی در دو مرحله صورت می گیرد
دیتا های ورودی پارتشین می شود
خوشه بندی ناقص انجام می شود
outlier های حذف می شود
خیلی مهم است که اندازه random Sample درست محاسبه شود.
چون ممکن است حجم محاسبات زیاد شود و یا اینکه خیلی داده ها دیده نشوند
شرط خاتمه این الگوریتم نسبت n به q هست
در سرعت این الگوریتم (Sample size و تعداد Partition ها ) بسیار مهم است
مهمترین خاصیت »: خوشه های غیر کروی هم می تواند انجام دهد
قابلیت محاسبه big data دارد
استفاده از Partitioning
———————————————————
ارائه خانم مهندس قربانی
الگوریتم Birch
برای Big Data – استفاده از الگوریتم های ساده امکان پذیر نیست
قبلا بر اساس احتمال ( یادگیری ماشین ) و یا بر اساس آمار ( روش های فاصله ) کار می کنند.
در روشهای اماری هزینه IO خیلی زیاد است
ولی روش Birch مشکلات روش های قدیم را ندارد
تراکم خوشه ها حول جرم را نشان می دهد
اگر دو خوشه را در نظر بگیریم ۵ تا معیار داریم
با استفاده از این ها فاصله اقلیدسی یا فاصله منهتن را محاسبه کنیم
با استفاده از فرمول به فاصله خوشه ها می رسیم
یک درخت به نام CF Tree می سازد
تا بتواند خوشه ها را با هم ادغام کند
در مثال آخر LS و SS مشخص شده اند
LS : مجموع خطی داده ها ست
SS : جمع مربعات n داده هست
هر کدام از پارامتر ها یک ارتفاعی دارند
که درخت CF انها را بالانس می کند
بردار CF ذخیره می شود و داده ها ذخیر نمی شود
و با کم کردن اطلاعات داده ها از هزینه های جابجایی جلوگیری می کند
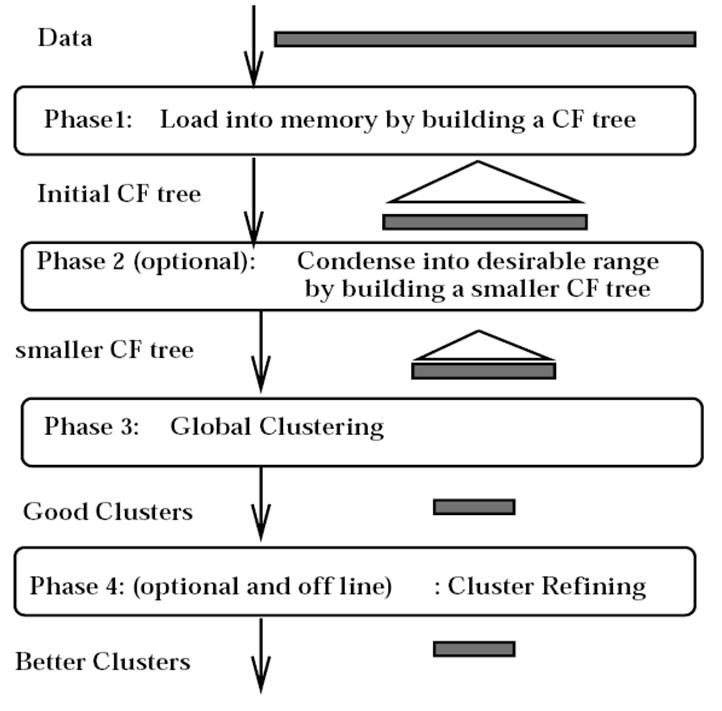
منبع : کتاب Mining of Massive Dataset
ایده کلی : تفاوت مهم Random Sampling بود
ولی birch نقاط را تبدیل به Future می کرد