۹۲/۱/۱۷ ESL
اگر سیگما را نداشته باشیم باید برآورد کنیم SSE
برآوردسیگما ۲ می شود SSEتقسیم بر درجه آزادی
امتحان از آمار و رگرسیون هست
بطور مستقیم از آمار امتحان نمی آید
مشابه نمونه سوالاتی که خانم گرجی حل می کنند
پروژه هم انجام بدهید در فصل ۳
۸ سری داده هست
۴ نمره اضافی پروژه دارد
مهلت تحویل پروژه تا زمانی که میشه نمره ها رو قطعی کرد( تیر یا مرداد)
بهتر است ۲ تا متغیر در نظر بگیرید
روشهای Shrinkage
اسلاید ۱۱ از ۱۹
Ridge Regression
توزیع Yi به شرط بتا j
سیگمای بتا j^2 ها را در نظر میگیریم
————————————
امروز مبحث Lasso Regression را توضیح میدهیم
مجموع مربعات خطا را مینیمم میکنیم به شرط اینکه سیگمای قدر مطلق بتا j ها از یک مقداری کمتر باشد
تفاوت ریج و لاسو :
در ریج هیچ ضریبی صفر نمی شود ولی در لاسو ممکن است ضرایب صفر شوند
در این ۳ روش پارامتر هایی دارند که باید آنها را مشخص میکنیم که به آن Cross Validation می گوییم
subset selection
df landa
می توانیم از تصویری از داده ها استفاده کنیم تا وضوح بهتری داشته باشیم
کاری که در Principal Component Regression انجام میدهیم تصویر سازی است
ماتریس مربع داریم که تجزیه میکنیم به دو ماتریس
ماتریس D (قطری) و ماتریس V ( اوتوگونال ) Di ها مقادیر ویژه هستند
اگر بتوانیم به این صورت بنویسیم از روش پرینسیپال به راحتی میتوانیم حل کنیم
Principal Component یعنی یک X داریم مولفه های اصلی اش را با تجزیه پیدا می کنیم
در واقع اگر دو بعد داشته باشیم p=2
یک سری داده داریم در قالب X1 , X2 که نقاط سبز را تشکیل می دهند
مولفه های اصلی D1 , D2 را پیدا کنیم
در این شکل نقطه ها در جهت D1 پراکنده شده اند
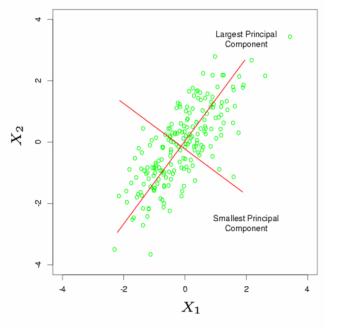
اگر بخواهیم متغیری را حذف کنیم بعد D2 را حذف می کنیم چون D1 مهم تر است
(اجباری هم در حذف بعد نیست )
مقادیر وِیژه را در متلب می توانیم با دستور (SVD(x’x محاسبه کنیم
به جای اینکه p تا Z داشته باشیم M تا Z را نگه میدارم
پس در Principal به جای اینکه بین x , z رگرسیون بگیرم بین y , z رگرس میکنم
M=p least Square
z=xv
کاهش بعد هم انجام داده می شود
۴ روش در این فصل گفتیم :
- Subset Selection
- Ridge Regression
- Lasso Regression
- Principal Component Regression
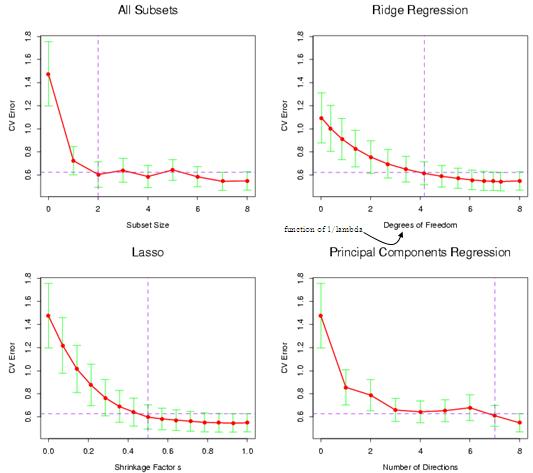
4 روشرگرسیون
معمولا روش ریج دقیق تر است
امتحان از فصل ۱ و ۳ هست