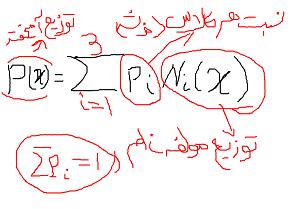خلاصه درس تدریس یار خوشه بندی ۹۲/۰۸/۰۴
تمرین : حتما از مقالات جدید استفاده کنید
مثلا از Fuzzy FCMeans استفاده کنید
هر الگوریتم خوشه بندی یک تابع هدف دارد که آنرا مشخص می کنیم
چند تا معیار پیدا کردن خوشه های بهینه را گفته است
تعداد خوشه بندی بهینه در روش های مختلف ممکن است متفاوت باشد
گزارش حتما باید فارسی باشد.
تا جمعه ۹۲/۰۸/۱۰ تمدید شد.
به فرمت : HomeWork1_nadi
مرجع GMM ما از کتاب Bishop می گوییم
روابط بویژه از طریق فرمولاسیون
روش مخلوط گوسی مثل Fuzzy هست
تعلق به خوشه های مختلف ممنکن است متفاوت باشد
میانگین و واریانس پارامتر ها هستند
اگر داده ها چند بعدی بودند
یک ماتریس برای میانگین داشتیم – یک بردار برای واریانس
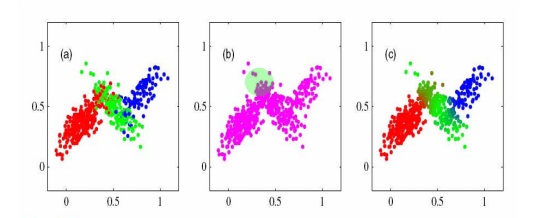
مثلا می گوییم : در مدل سازی یک مجموعه داده ای از یک مخلوط با ۳ تابع گوسی استفاده شده
توزیعی وزنش بیشتر است که تابع های بیشتری به آن Fit شده اند
Pi,k بیشتری دارد
پارامتر وزن : pi k
بردار میانگین : mio k
مولفه : Sigma k
یک متغیر تصادفی Z تعریف می کنیم ، یک بردار است
تعداد مولفه هایش به تعداد مولفه های گوسی هست
۳ مولفه دارد
هر کدام از مولفه ها می توانند ۰ یا ۱ باشند
و مجموع موله ها باید۱ شود
k تا حالت می شود
به جای اینکه بگوییم مولفه گوسی سوم ، متناظر Z آنرا می گوییم
پس توزیع Z پر رنگ میشه :
z=[z1 z2 z3]
توزیع توام
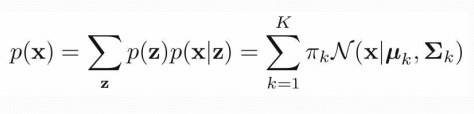
p(a/b)= p(a)*p(b/a) / S(p(a,b))
در صورت وزن هر گوسی را در تابع توزیع ضرب می کنیم
تقسیم بر مجموع pi ها در تابع نرمال ها
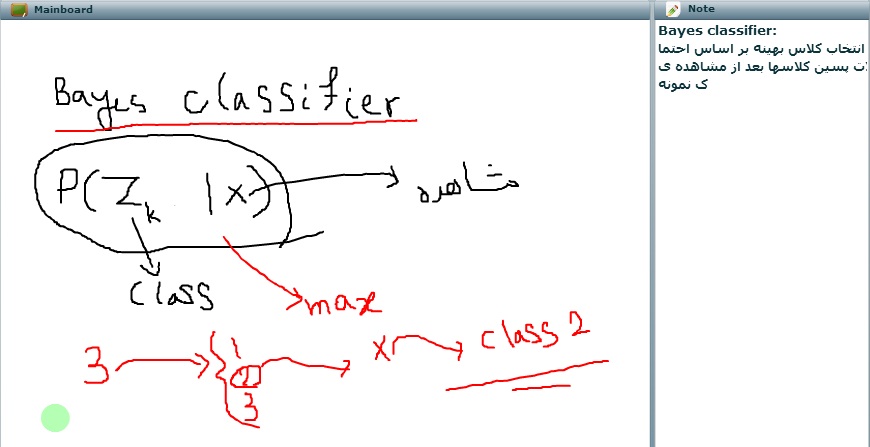
اسلاید ۹ : Prior Probablility
zk =1 احتمال پیشین
احتمال پسین ، احتمال گوسی k پس از مشاهده x
—————————–
تمرین به صورت PDF و داخل یک فایل زیپ باشد